Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
2405.00998
0
0
🛸
Abstract
This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
Create account to get full access
Overview
- This paper presents a novel latent 3D diffusion model for generating neural voxel fields with accurate part-aware structures.
- The key designs are:
- A latent 3D diffusion process for neural voxel fields, enabling high-resolution generation with rich textural and geometric details.
- A part-aware shape decoder that integrates part codes into the neural voxel fields, guiding accurate part decomposition and high-quality rendering.
- The model is evaluated on four different data classes and outperforms existing state-of-the-art methods in part-aware shape generation.
Plain English Explanation
This research introduces a new way to generate 3D models with accurate and detailed part structures. The key idea is to use a latent 3D diffusion model to create the 3D models, which allows for generating high-resolution models with lots of texture and geometric detail.
Additionally, the model has a "part-aware" shape decoder, which means it can break the 3D model down into distinct parts or components and generate them accurately. This helps the model create 3D models that closely match the real-world objects they are based on.
The researchers tested their model on four different types of 3D data and found that it outperformed other state-of-the-art methods, especially in its ability to generate 3D models with well-defined parts. This could be useful for applications like 3D modeling, computer vision, and robotics, where accurate part-aware 3D models are important.
Technical Explanation
The paper introduces a novel latent 3D diffusion model for generating neural voxel fields with accurate part-aware structures. The key innovations are:
- Latent 3D Diffusion Process: The model uses a latent 3D diffusion process to generate the neural voxel fields, which allows for high-resolution outputs with rich textural and geometric details.
- Part-Aware Shape Decoder: The model includes a part-aware shape decoder that integrates part codes into the neural voxel fields, guiding the accurate decomposition of the shape into parts and producing high-quality rendering results.
Through extensive experiments on four different data classes, the researchers demonstrate that their proposed method outperforms existing state-of-the-art approaches in part-aware shape generation.
Critical Analysis
The paper provides a solid technical contribution by introducing a novel latent 3D diffusion model for generating part-aware neural voxel fields. The key strengths are the high-resolution generation capabilities and the part-aware shape decoder, which together enable accurate 3D model generation.
However, the paper does not extensively discuss the potential limitations or caveats of the approach. For example, it would be helpful to understand the computational and memory requirements of the model, as well as its performance on more diverse or challenging 3D datasets.
Additionally, the paper could have explored the potential biases or ethical considerations around the generation of 3D models, especially in the context of applications like computer vision and robotics. ShapeFusion and StructLDM are examples of 3D generation models that discuss some of these issues.
Overall, the technical contributions of the paper are compelling, and the results demonstrate the potential of the approach. However, a more thorough discussion of the limitations and broader implications would strengthen the critical analysis.
Conclusion
This paper presents a novel latent 3D diffusion model for generating neural voxel fields with accurate part-aware structures. The key innovations are the use of a latent 3D diffusion process for high-resolution generation and a part-aware shape decoder to guide the accurate decomposition of the 3D shapes.
The experimental results show that the proposed method outperforms existing state-of-the-art approaches in part-aware shape generation, which could have important implications for applications like 3D modeling, computer vision, and robotics. While the technical contributions are substantial, the paper could be strengthened by a more comprehensive discussion of the limitations and broader societal implications of the research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Single Mesh Diffusion Models with Field Latents for Texture Generation
Thomas W. Mitchel, Carlos Esteves, Ameesh Makadia
0
0
We introduce a framework for intrinsic latent diffusion models operating directly on the surfaces of 3D shapes, with the goal of synthesizing high-quality textures. Our approach is underpinned by two contributions: field latents, a latent representation encoding textures as discrete vector fields on the mesh vertices, and field latent diffusion models, which learn to denoise a diffusion process in the learned latent space on the surface. We consider a single-textured-mesh paradigm, where our models are trained to generate variations of a given texture on a mesh. We show the synthesized textures are of superior fidelity compared those from existing single-textured-mesh generative models. Our models can also be adapted for user-controlled editing tasks such as inpainting and label-guided generation. The efficacy of our approach is due in part to the equivariance of our proposed framework under isometries, allowing our models to seamlessly reproduce details across locally similar regions and opening the door to a notion of generative texture transfer.
5/30/2024
💬
WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space
Katja Schwarz, Seung Wook Kim, Jun Gao, Sanja Fidler, Andreas Geiger, Karsten Kreis
0
0
Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images' underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data. See https://katjaschwarz.github.io/wildfusion for videos of our 3D results.
4/15/2024
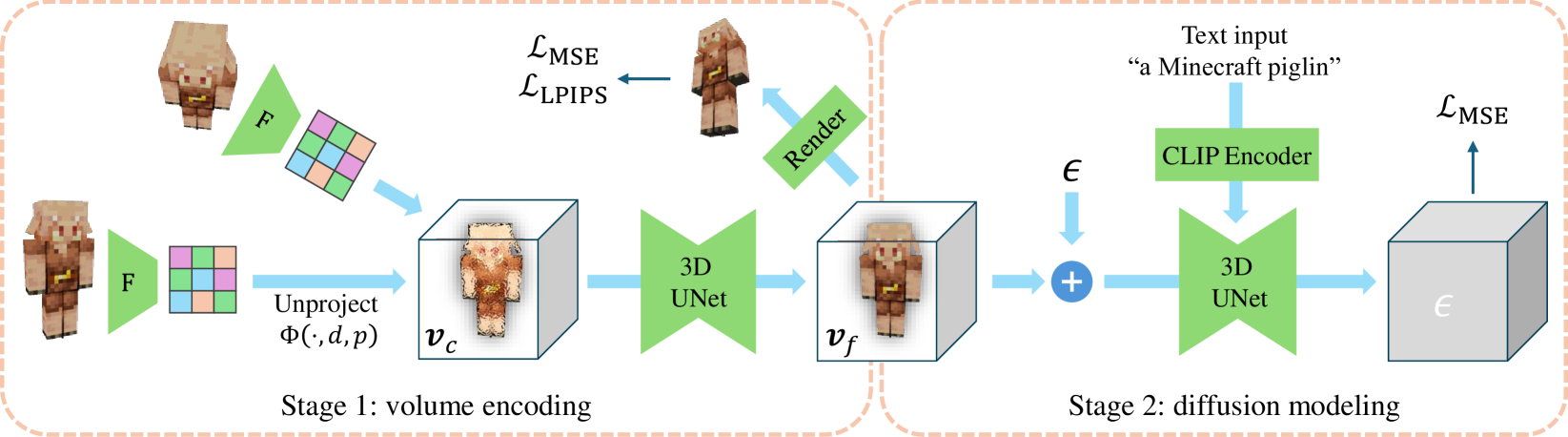
VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder
Zhicong Tang, Shuyang Gu, Chunyu Wang, Ting Zhang, Jianmin Bao, Dong Chen, Baining Guo
0
0
This paper introduces a pioneering 3D volumetric encoder designed for text-to-3D generation. To scale up the training data for the diffusion model, a lightweight network is developed to efficiently acquire feature volumes from multi-view images. The 3D volumes are then trained on a diffusion model for text-to-3D generation using a 3D U-Net. This research further addresses the challenges of inaccurate object captions and high-dimensional feature volumes. The proposed model, trained on the public Objaverse dataset, demonstrates promising outcomes in producing diverse and recognizable samples from text prompts. Notably, it empowers finer control over object part characteristics through textual cues, fostering model creativity by seamlessly combining multiple concepts within a single object. This research significantly contributes to the progress of 3D generation by introducing an efficient, flexible, and scalable representation methodology. Code is available at https://github.com/checkcrab/VolumeDiffusion.
4/30/2024

DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu
0
0
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
5/15/2024