Single Mesh Diffusion Models with Field Latents for Texture Generation
2312.09250
0
0

Abstract
We introduce a framework for intrinsic latent diffusion models operating directly on the surfaces of 3D shapes, with the goal of synthesizing high-quality textures. Our approach is underpinned by two contributions: field latents, a latent representation encoding textures as discrete vector fields on the mesh vertices, and field latent diffusion models, which learn to denoise a diffusion process in the learned latent space on the surface. We consider a single-textured-mesh paradigm, where our models are trained to generate variations of a given texture on a mesh. We show the synthesized textures are of superior fidelity compared those from existing single-textured-mesh generative models. Our models can also be adapted for user-controlled editing tasks such as inpainting and label-guided generation. The efficacy of our approach is due in part to the equivariance of our proposed framework under isometries, allowing our models to seamlessly reproduce details across locally similar regions and opening the door to a notion of generative texture transfer.
Create account to get full access
Overview
- This paper proposes a novel diffusion model for generating high-quality textured 3D mesh models.
- The key innovations include using a single mesh as the model's input and training the diffusion model to learn a latent field representation of the texture.
- This approach allows for efficient generation of diverse textures while preserving the underlying mesh geometry.
Plain English Explanation
The researchers have developed a new type of AI model that can create realistic 3D mesh models with detailed textures. Traditionally, generating textured 3D models has been a complex task, as the texture information needs to be carefully aligned with the underlying 3D geometry.
The researchers' approach uses a diffusion model - a type of machine learning model that can generate new data by gradually transforming random noise. Crucially, their model takes a single 3D mesh as input and learns to manipulate a latent "field" representation of the texture, rather than directly generating the texture pixels.
This allows the model to efficiently produce a wide variety of textured 3D meshes while preserving the geometric structure. The researchers demonstrate that their method can generate high-quality textured models that compare favorably to existing techniques, opening up new possibilities for 3D content creation.
Technical Explanation
The core innovation of this paper is the use of a single 3D mesh as the input to a diffusion model, combined with learning a latent field representation of the texture.
Traditionally, generating textured 3D models has required separately modeling the 3D geometry and 2D texture, and aligning them precisely. The researchers instead propose a "single mesh diffusion model" that takes a single 3D mesh as input and learns to manipulate a latent field representation of the texture.
This latent field is a continuous 3D function defined over the surface of the mesh, which encodes the texture information. The diffusion model is trained to gradually transform random noise into this latent field, allowing it to generate diverse textured meshes efficiently.
The researchers demonstrate that their approach can generate high-quality textured 3D models that compare favorably to existing diffusion-based 3D generation methods in terms of both visual quality and computational efficiency.
Critical Analysis
A key strength of this approach is its ability to preserve the underlying 3D geometry while generating diverse textures. This is an important practical consideration, as the 3D mesh and texture are often tightly coupled in real-world 3D models.
However, the paper does not extensively explore the limitations of this approach. For example, it's unclear how well the method would scale to highly complex 3D meshes or handle challenging texture patterns. Additionally, the researchers do not compare their method to other texture generation techniques, such as image-to-image translation or example-based texture synthesis.
Further research could investigate the model's robustness, explore additional applications beyond texture generation, and compare the approach to a wider range of existing techniques.
Conclusion
This paper presents a novel diffusion-based approach for generating high-quality textured 3D mesh models. By using a single 3D mesh as input and learning a latent field representation of the texture, the researchers have developed an efficient and flexible method for 3D content creation.
The ability to preserve geometric structure while generating diverse textures is a significant advancement, with potential applications in areas like computer graphics, virtual reality, and 3D printing. As diffusion models continue to revolutionize generative tasks, this work demonstrates their versatility in the 3D domain and opens up new research directions for 3D content generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!TexPainter: Generative Mesh Texturing with Multi-view Consistency
Hongkun Zhang, Zherong Pan, Congyi Zhang, Lifeng Zhu, Xifeng Gao
0
0
The recent success of pre-trained diffusion models unlocks the possibility of the automatic generation of textures for arbitrary 3D meshes in the wild. However, these models are trained in the screen space, while converting them to a multi-view consistent texture image poses a major obstacle to the output quality. In this paper, we propose a novel method to enforce multi-view consistency. Our method is based on the observation that latent space in a pre-trained diffusion model is noised separately for each camera view, making it difficult to achieve multi-view consistency by directly manipulating the latent codes. Based on the celebrated Denoising Diffusion Implicit Models (DDIM) scheme, we propose to use an optimization-based color-fusion to enforce consistency and indirectly modify the latent codes by gradient back-propagation. Our method further relaxes the sequential dependency assumption among the camera views. By evaluating on a series of general 3D models, we find our simple approach improves consistency and overall quality of the generated textures as compared to competing state-of-the-arts. Our implementation is available at: https://github.com/Quantuman134/TexPainter
6/28/2024
🖼️
EASI-Tex: Edge-Aware Mesh Texturing from Single Image
Sai Raj Kishore Perla, Yizhi Wang, Ali Mahdavi-Amiri, Hao Zhang
0
0
We present a novel approach for single-image mesh texturing, which employs a diffusion model with judicious conditioning to seamlessly transfer an object's texture from a single RGB image to a given 3D mesh object. We do not assume that the two objects belong to the same category, and even if they do, there can be significant discrepancies in their geometry and part proportions. Our method aims to rectify the discrepancies by conditioning a pre-trained Stable Diffusion generator with edges describing the mesh through ControlNet, and features extracted from the input image using IP-Adapter to generate textures that respect the underlying geometry of the mesh and the input texture without any optimization or training. We also introduce Image Inversion, a novel technique to quickly personalize the diffusion model for a single concept using a single image, for cases where the pre-trained IP-Adapter falls short in capturing all the details from the input image faithfully. Experimental results demonstrate the efficiency and effectiveness of our edge-aware single-image mesh texturing approach, coined EASI-Tex, in preserving the details of the input texture on diverse 3D objects, while respecting their geometry.
5/28/2024
Latent diffusion models for parameterization and data assimilation of facies-based geomodels
Guido Di Federico, Louis J. Durlofsky
0
0
Geological parameterization entails the representation of a geomodel using a small set of latent variables and a mapping from these variables to grid-block properties such as porosity and permeability. Parameterization is useful for data assimilation (history matching), as it maintains geological realism while reducing the number of variables to be determined. Diffusion models are a new class of generative deep-learning procedures that have been shown to outperform previous methods, such as generative adversarial networks, for image generation tasks. Diffusion models are trained to denoise, which enables them to generate new geological realizations from input fields characterized by random noise. Latent diffusion models, which are the specific variant considered in this study, provide dimension reduction through use of a low-dimensional latent variable. The model developed in this work includes a variational autoencoder for dimension reduction and a U-net for the denoising process. Our application involves conditional 2D three-facies (channel-levee-mud) systems. The latent diffusion model is shown to provide realizations that are visually consistent with samples from geomodeling software. Quantitative metrics involving spatial and flow-response statistics are evaluated, and general agreement between the diffusion-generated models and reference realizations is observed. Stability tests are performed to assess the smoothness of the parameterization method. The latent diffusion model is then used for ensemble-based data assimilation. Two synthetic true models are considered. Significant uncertainty reduction, posterior P$_{10}$-P$_{90}$ forecasts that generally bracket observed data, and consistent posterior geomodels, are achieved in both cases.
6/28/2024
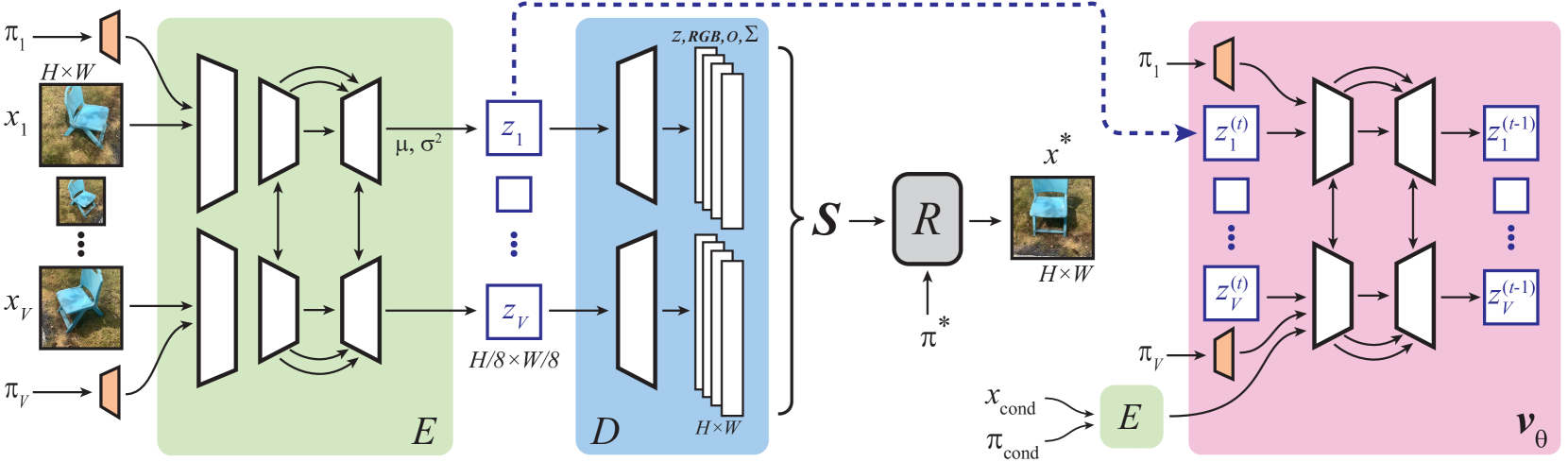
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Paul Henderson, Melonie de Almeida, Daniela Ivanova, Titas Anciukeviv{c}ius
0
0
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
6/21/2024