Partial Information Decomposition for Data Interpretability and Feature Selection
2405.19212
0
0
📊
Abstract
In this paper, we introduce Partial Information Decomposition of Features (PIDF), a new paradigm for simultaneous data interpretability and feature selection. Contrary to traditional methods that assign a single importance value, our approach is based on three metrics per feature: the mutual information shared with the target variable, the feature's contribution to synergistic information, and the amount of this information that is redundant. In particular, we develop a novel procedure based on these three metrics, which reveals not only how features are correlated with the target but also the additional and overlapping information provided by considering them in combination with other features. We extensively evaluate PIDF using both synthetic and real-world data, demonstrating its potential applications and effectiveness, by considering case studies from genetics and neuroscience.
Create account to get full access
Overview
- This paper presents a mutual information-based approach to preserve the re-trainability of neural networks during the pruning and feature selection process.
- The proposed method aims to maintain the network's ability to be re-trained and fine-tuned after pruning or feature selection, which is crucial for practical applications.
- The authors introduce a novel mutual information-based metric to guide the pruning and feature selection process, ensuring that the most informative connections and features are retained.
Plain English Explanation
The paper talks about a way to make pruning and feature selection for neural networks better. Pruning is when you remove parts of the network to make it smaller and faster, while feature selection is choosing which input features to use. The problem is that these processes can sometimes make the network less able to be re-trained and fine-tuned, which is important for real-world use.
The researchers came up with a new way to measure how much information is shared between the inputs, the network, and the outputs. This "mutual information" metric is used to guide the pruning and feature selection, making sure the most important connections and features are kept. This helps preserve the network's ability to be re-trained and adjusted after the pruning or feature selection is done.
By using this mutual information approach, the authors show that the pruned or feature-selected networks can still be fine-tuned and perform well, without losing too much accuracy. This is a useful technique for making neural networks more practical and efficient for real-world applications.
Technical Explanation
The paper introduces a novel mutual information-based metric to guide the pruning and feature selection process for neural networks. The goal is to preserve the "re-trainability" of the network, ensuring that it can be fine-tuned and adjusted after the pruning or feature selection is performed.
The authors first define a mutual information-based criterion that captures the information shared between the network inputs, the hidden representations, and the outputs. This criterion is then used to identify the most informative connections and features to retain during the pruning and feature selection process, respectively.
For pruning, the authors propose a technique that selectively removes the least informative connections based on the mutual information criterion, while preserving the most informative ones. This helps maintain the network's ability to be re-trained and fine-tuned after pruning.
Similarly, for feature selection, the authors use the mutual information criterion to identify the most informative input features to retain, ensuring that the reduced feature set still contains the essential information for the task at hand. This feature selection approach helps preserve the network's re-trainability while reducing the computational and memory footprint.
The paper presents extensive experiments on various benchmark datasets and neural network architectures, demonstrating the effectiveness of the proposed mutual information-based approach in preserving the re-trainability of pruned and feature-selected models. The results show that the pruned and feature-selected models can be efficiently re-trained and fine-tuned, maintaining competitive performance compared to the original, unpruned models.
Critical Analysis
The authors provide a thorough evaluation of their proposed mutual information-based approach, including comparisons to various baseline pruning and feature selection techniques. However, the paper could have benefited from a more in-depth discussion of the limitations and potential caveats of the method.
For example, the authors do not address how the mutual information estimation might be affected by the choice of network architecture or the size of the training dataset. Additionally, the computational complexity of the mutual information calculation, especially for large-scale networks, could be a practical concern that warrants further investigation.
Moreover, the paper does not explore the trade-offs between the degree of pruning or feature selection and the preservation of re-trainability. It would be valuable to understand how the mutual information-based approach performs under different levels of model compression or feature reduction, and whether there are any thresholds or sweet spots where the benefits are most pronounced.
Interpretable diffusion models and information-theoretic approaches to feature selection are active areas of research in the machine learning community, and it would be interesting to see how the mutual information-based techniques presented in this paper could be further combined or compared with these related methods.
Conclusion
This paper presents a novel mutual information-based approach to preserve the re-trainability of neural networks during pruning and feature selection. The proposed method uses a mutual information criterion to identify and retain the most informative connections and features, enabling the pruned or feature-selected models to be efficiently re-trained and fine-tuned without significant performance degradation.
The authors' findings demonstrate the effectiveness of this mutual information-based technique, which can be a valuable tool for improving the practicality and efficiency of neural networks in real-world applications. By preserving the re-trainability of the models, this approach helps address a crucial challenge in neural network compression and optimization, paving the way for more deployable and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Shaurya Dewan, Rushikesh Zawar, Prakanshul Saxena, Yingshan Chang, Andrew Luo, Yonatan Bisk
0
0
Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
6/14/2024
🧠
Which Information Matters? Dissecting Human-written Multi-document Summaries with Partial Information Decomposition
Laura Mascarell, Yan L'Homme, Majed El Helou
0
0
Understanding the nature of high-quality summaries is crucial to further improve the performance of multi-document summarization. We propose an approach to characterize human-written summaries using partial information decomposition, which decomposes the mutual information provided by all source documents into union, redundancy, synergy, and unique information. Our empirical analysis on different MDS datasets shows that there is a direct dependency between the number of sources and their contribution to the summary.
5/24/2024
Partial information decomposition as information bottleneck
Artemy Kolchinsky
0
0
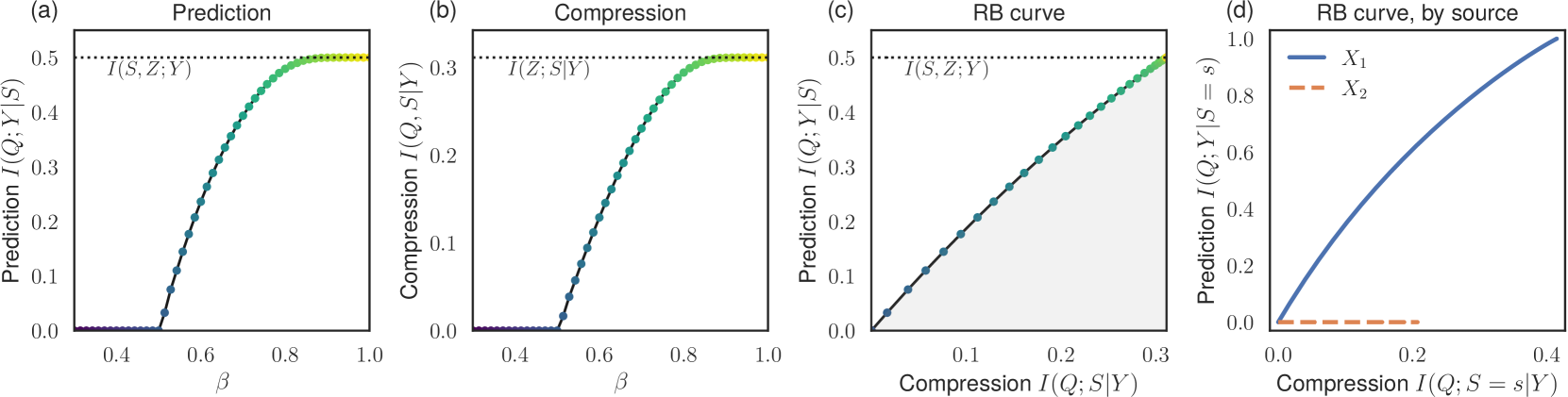
The partial information decomposition (PID) aims to quantify the amount of redundant information that a set of sources provides about a target. Here, we show that this goal can be formulated as a type of information bottleneck (IB) problem, termed the redundancy bottleneck (RB). The RB formalizes a tradeoff between prediction and compression: it extracts information from the sources that best predict the target, without revealing which source provided the information. It can be understood as a generalization of Blackwell redundancy, which we previously proposed as a principled measure of PID redundancy. The RB curve quantifies the prediction--compression tradeoff at multiple scales. This curve can also be quantified for individual sources, allowing subsets of redundant sources to be identified without combinatorial optimization. We provide an efficient iterative algorithm for computing the RB curve.
6/28/2024

A Unified View of Group Fairness Tradeoffs Using Partial Information Decomposition
Faisal Hamman, Sanghamitra Dutta
0
0
This paper introduces a novel information-theoretic perspective on the relationship between prominent group fairness notions in machine learning, namely statistical parity, equalized odds, and predictive parity. It is well known that simultaneous satisfiability of these three fairness notions is usually impossible, motivating practitioners to resort to approximate fairness solutions rather than stringent satisfiability of these definitions. However, a comprehensive analysis of their interrelations, particularly when they are not exactly satisfied, remains largely unexplored. Our main contribution lies in elucidating an exact relationship between these three measures of (un)fairness by leveraging a body of work in information theory called partial information decomposition (PID). In this work, we leverage PID to identify the granular regions where these three measures of (un)fairness overlap and where they disagree with each other leading to potential tradeoffs. We also include numerical simulations to complement our results.
6/10/2024