PC-LoRA: Low-Rank Adaptation for Progressive Model Compression with Knowledge Distillation
2406.09117
0
0

Abstract
Low-rank adaption (LoRA) is a prominent method that adds a small number of learnable parameters to the frozen pre-trained weights for parameter-efficient fine-tuning. Prompted by the question, ``Can we make its representation enough with LoRA weights solely at the final phase of finetuning without the pre-trained weights?'' In this work, we introduce Progressive Compression LoRA~(PC-LoRA), which utilizes low-rank adaptation (LoRA) to simultaneously perform model compression and fine-tuning. The PC-LoRA method gradually removes the pre-trained weights during the training process, eventually leaving only the low-rank adapters in the end. Thus, these low-rank adapters replace the whole pre-trained weights, achieving the goals of compression and fine-tuning at the same time. Empirical analysis across various models demonstrates that PC-LoRA achieves parameter and FLOPs compression rates of 94.36%/89.1% for vision models, e.g., ViT-B, and 93.42%/84.2% parameters and FLOPs compressions for language models, e.g., BERT.
Create account to get full access
Overview
- This paper introduces PC-LoRA, a novel low-rank adaptation (LoRA) technique for progressive model compression with knowledge distillation.
- PC-LoRA enables efficient model compression by training a compact "student" model to mimic the behavior of a larger "teacher" model.
- The key innovation is the use of low-rank adaptation to fine-tune only a small subset of the model parameters, preserving the original model's performance while significantly reducing its size.
Plain English Explanation
PC-LoRA: Low-Rank Adaptation for Progressive Model Compression with Knowledge Distillation is a method for making machine learning models smaller and more efficient without losing too much performance. The idea is to train a smaller "student" model to behave like a larger "teacher" model, using a technique called "low-rank adaptation" (LoRA).
LoRA works by only fine-tuning a small subset of the model's parameters, rather than updating the entire model. This preserves the original model's knowledge, while allowing the student model to be much smaller and more efficient. The authors show that this approach can significantly reduce the size of large language models, for example, without sacrificing too much accuracy.
This is an important advancement, as smaller models can run on less powerful hardware, making AI systems more accessible and environmentally friendly. The techniques developed in this paper build on prior work on LoRA and other low-rank adaptation methods, demonstrating how these ideas can be applied for progressive model compression.
Technical Explanation
The key technical innovation in PC-LoRA is the use of low-rank adaptation (LoRA) to fine-tune a smaller "student" model to mimic the behavior of a larger "teacher" model. Specifically, the authors add trainable low-rank matrices to a subset of the model's weight matrices, allowing them to update only a small portion of the parameters during fine-tuning.
This approach builds on prior work on LoRA and related techniques like DORA and ALORA, which have shown the effectiveness of low-rank adaptations for efficient fine-tuning. The authors further demonstrate how these ideas can be applied for progressive model compression using knowledge distillation.
Through extensive experiments, the authors show that PC-LoRA can achieve significant model compression (up to 10x reduction in parameters) with only modest drops in performance, outperforming alternative compression techniques. This makes it a promising approach for deploying large language models on resource-constrained devices or in energy-efficient scenarios.
Critical Analysis
The PC-LoRA approach presented in this paper is a well-designed and rigorously evaluated technique for efficient model compression. The authors thoroughly compare their method to a range of baselines and provide compelling results across multiple benchmark tasks.
That said, the paper does not address some potential limitations or caveats. For example, it is unclear how the performance of PC-LoRA scales to larger, more complex models, or how it might be impacted by different fine-tuning regimes or dataset characteristics. Additionally, the paper does not explore the potential for further architectural innovations or the integration of PC-LoRA with other compression techniques, such as quantization or pruning.
Moreover, while the authors demonstrate the practical benefits of PC-LoRA in terms of model size and inference efficiency, they do not delve into the broader implications or potential societal impacts of deploying such compressed models. Further research could investigate how these techniques might enable more accessible and environmentally sustainable AI systems.
Overall, the PC-LoRA method represents an important contribution to the field of model compression, and the authors have done an admirable job of advancing the state of the art. However, there remain opportunities for future work to expand the scope and understanding of this approach.
Conclusion
PC-LoRA introduces an efficient technique for compressing large machine learning models using low-rank adaptation and knowledge distillation. By fine-tuning only a small subset of model parameters, PC-LoRA can significantly reduce the size of models while preserving their performance.
This work builds on and extends previous research on low-rank adaptation methods, demonstrating how these ideas can be applied for progressive model compression. The authors show that PC-LoRA outperforms alternative compression techniques, making it a promising approach for deploying large language models on resource-constrained devices or in energy-efficient scenarios.
While the paper presents a well-designed and rigorously evaluated technique, there remain opportunities for further research to explore the scalability, architectural innovations, and broader implications of this approach. Nonetheless, PC-LoRA represents an important advancement in the field of efficient and sustainable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
0
0
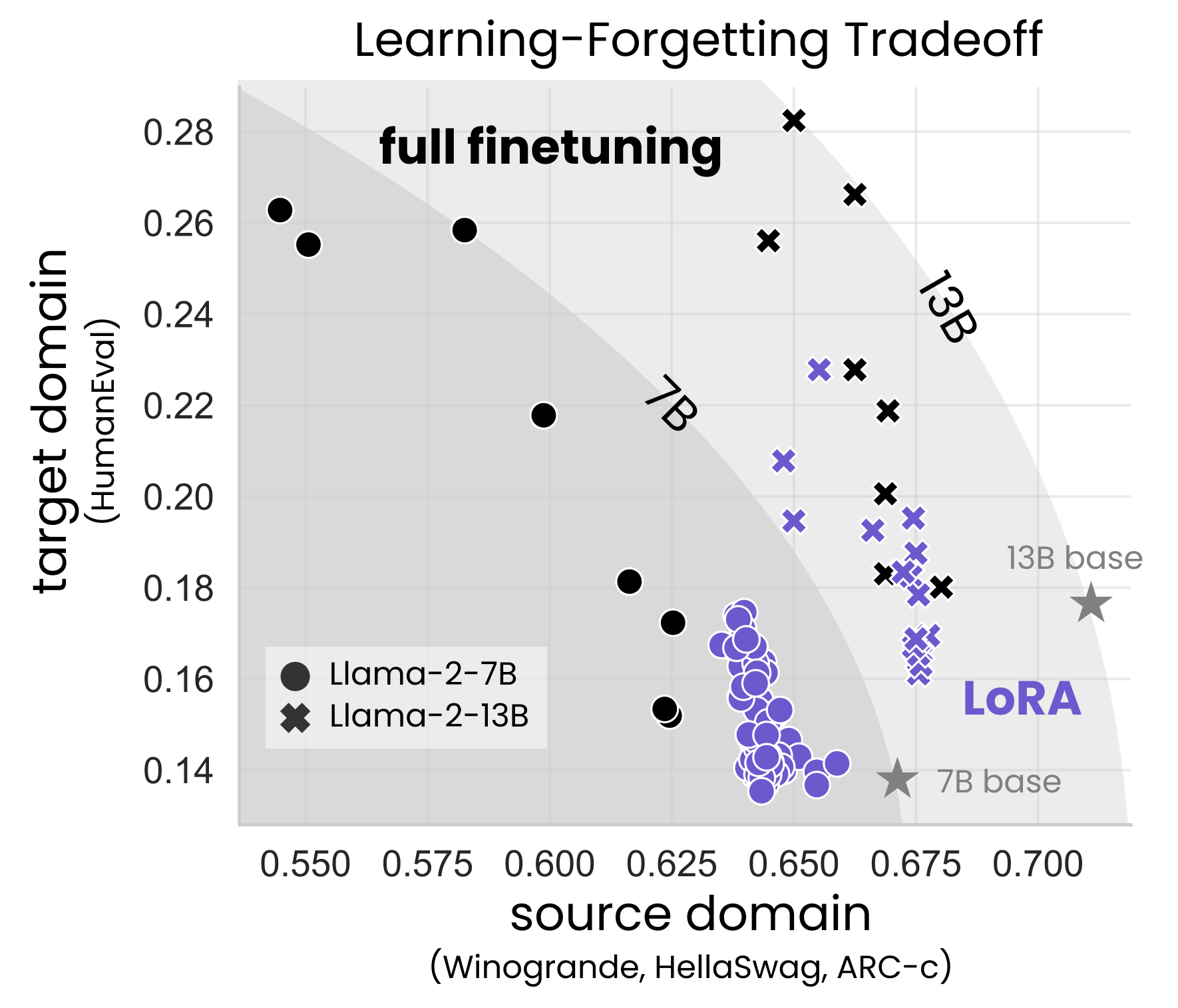
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
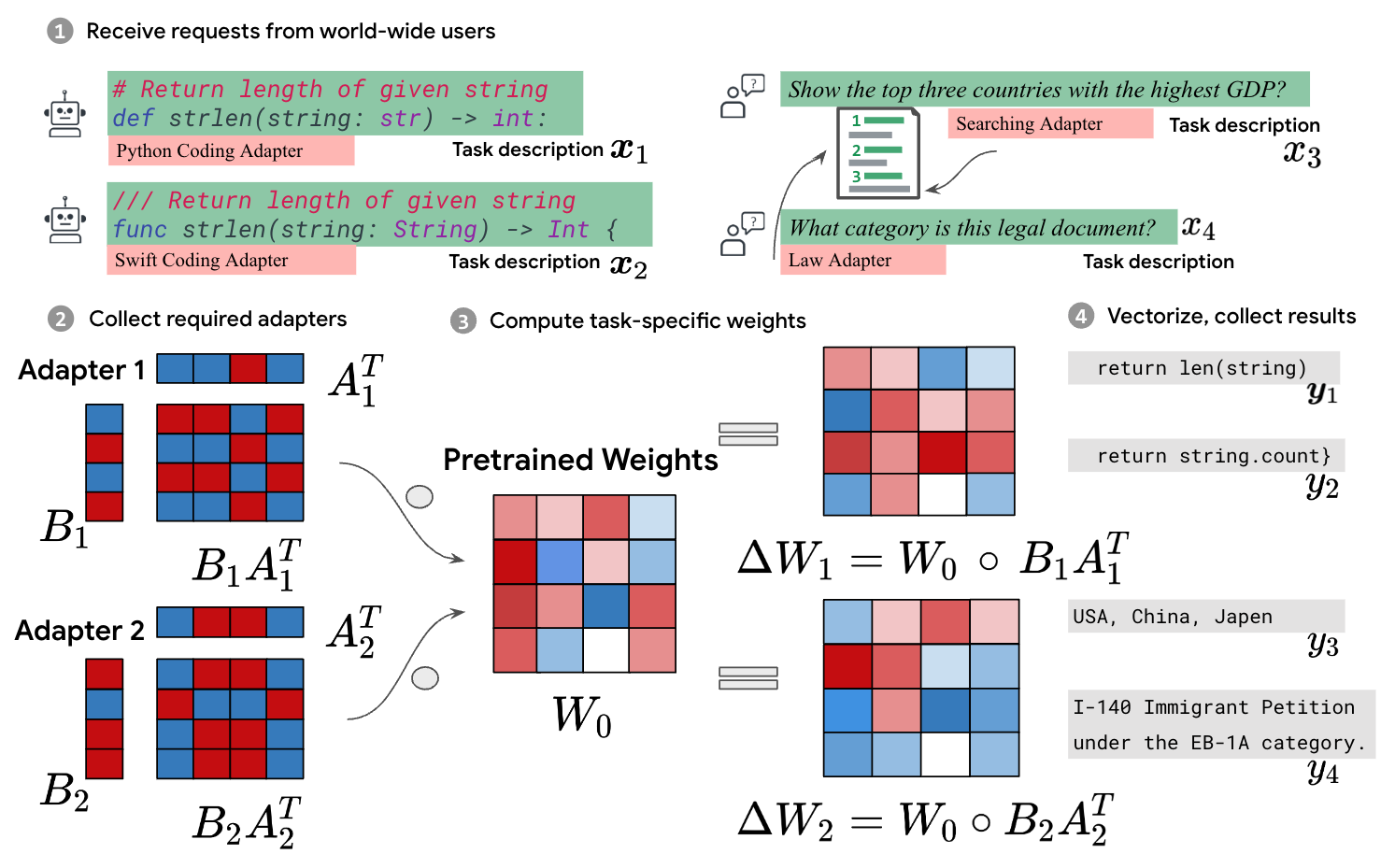
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024
👀
FLoCoRA: Federated learning compression with low-rank adaptation
Lucas Grativol Ribeiro (IMT Atlantique - MEE, Lab_STICC_BRAIn, Lab-STICC_2AI, LHC), Mathieu Leonardon (IMT Atlantique - MEE, Lab_STICC_BRAIn), Guillaume Muller (Mines Saint-'Etienne MSE, FAYOL-ENSMSE, FAYOL-ENSMSE), Virginie Fresse (LHC, TSE), Matthieu Arzel (IMT Atlantique - MEE, Lab-STICC_2AI)
0
0
Low-Rank Adaptation (LoRA) methods have gained popularity in efficient parameter fine-tuning of models containing hundreds of billions of parameters. In this work, instead, we demonstrate the application of LoRA methods to train small-vision models in Federated Learning (FL) from scratch. We first propose an aggregation-agnostic method to integrate LoRA within FL, named FLoCoRA, showing that the method is capable of reducing communication costs by 4.8 times, while having less than 1% accuracy degradation, for a CIFAR-10 classification task with a ResNet-8. Next, we show that the same method can be extended with an affine quantization scheme, dividing the communication cost by 18.6 times, while comparing it with the standard method, with still less than 1% of accuracy loss, tested with on a ResNet-18 model. Our formulation represents a strong baseline for message size reduction, even when compared to conventional model compression works, while also reducing the training memory requirements due to the low-rank adaptation.
6/21/2024
🌀
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen
0
0
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed Low-Rank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing ours, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. ours~consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding. Code is available at https://github.com/NVlabs/DoRA.
6/4/2024