PCP-MAE: Learning to Predict Centers for Point Masked Autoencoders

0

Sign in to get full access
Overview
- The paper introduces PCP-MAE, a method for learning to predict the centers of masked regions in point cloud data using a self-supervised approach.
- PCP-MAE aims to improve the performance and interpretability of point cloud masked autoencoders by predicting the center locations of masked regions.
- The proposed approach is evaluated on several point cloud benchmarks and shows improvements over existing masked autoencoder methods.
Plain English Explanation
In this paper, the researchers introduce a new technique called PCP-MAE (Predict Center for Point Masked Autoencoder) that helps improve the performance and understanding of a type of machine learning model called a masked autoencoder.
Masked autoencoders work by randomly "masking" or hiding parts of the input data, and then training the model to try to "fill in" or reconstruct the missing parts. This teaches the model to extract useful features and patterns from the data.
The key innovation in PCP-MAE is that it not only tries to reconstruct the masked regions, but also predicts the center locations of those masked regions. This additional task helps the model learn more meaningful representations of the data, which can lead to better performance on various point cloud benchmarks.
By predicting the center locations, the researchers argue that PCP-MAE can also provide better interpretability - it becomes easier to understand what the model has learned and how it is making its predictions.
The paper evaluates PCP-MAE on several standard point cloud datasets and compares it to other state-of-the-art masked autoencoder methods. The results show that PCP-MAE can outperform these other approaches, demonstrating the benefits of predicting the center locations as part of the self-supervised training process.
Technical Explanation
The PCP-MAE approach builds upon the masked autoencoder (MAE) framework, which has become a popular self-supervised learning technique for point cloud data. In a masked autoencoder, the input point cloud is randomly masked (i.e., a subset of points are removed), and the model is trained to reconstruct the missing regions.
The key innovation in PCP-MAE is the addition of a center prediction task, where the model not only tries to reconstruct the masked regions, but also predicts the center locations of those masked regions. This is achieved by adding a center prediction head to the standard MAE architecture, which takes the encoded point cloud features as input and outputs the predicted center coordinates.
The overall PCP-MAE training process consists of two main steps:
- Masked Region Reconstruction: The model encodes the partially masked input point cloud and tries to reconstruct the missing regions.
- Center Prediction: The encoded features are used to predict the center locations of the masked regions.
By incorporating this center prediction task, the researchers hypothesize that the model will learn more meaningful and interpretable representations of the point cloud data, leading to improved performance on various downstream tasks.
The paper evaluates PCP-MAE on several standard point cloud benchmarks, including shape classification, part segmentation, and object detection. The results show that PCP-MAE outperforms other state-of-the-art masked autoencoder methods, demonstrating the benefits of the center prediction task.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the PCP-MAE approach, comparing it to several baselines on a range of point cloud benchmarks. The authors acknowledge some potential limitations, such as the fact that the center prediction task may not be applicable to all types of point cloud data (e.g., unstructured or highly irregular shapes).
One area that could be explored further is the interpretability of the learned representations. While the authors claim that PCP-MAE can provide better interpretability, the paper does not provide a detailed analysis or visualization of the learned features and their relationship to the center prediction task.
Additionally, the paper does not explore the robustness of PCP-MAE to different types of masking strategies or noise in the input point clouds. Investigating the model's performance under more challenging or realistic data conditions could provide additional insights.
Overall, the PCP-MAE approach represents a promising step in improving the performance and interpretability of masked autoencoders for point cloud data. The paper makes a valuable contribution to the field, and the proposed method could be further refined and extended in future research.
Conclusion
The PCP-MAE method introduced in this paper demonstrates the benefits of incorporating a center prediction task into the masked autoencoder framework for point cloud data. By learning to predict the center locations of masked regions, the model is able to extract more meaningful and interpretable representations, leading to improved performance on a variety of point cloud benchmarks.
The paper's thorough evaluation and comparison to state-of-the-art approaches highlight the potential of the PCP-MAE technique. While the method has some limitations, the findings suggest that predicting the centers of masked regions can be a valuable addition to self-supervised learning for point clouds, with implications for a range of applications such as 3D shape analysis, object detection, and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PCP-MAE: Learning to Predict Centers for Point Masked Autoencoders
Xiangdong Zhang, Shaofeng Zhang, Junchi Yan
Masked autoencoder has been widely explored in point cloud self-supervised learning, whereby the point cloud is generally divided into visible and masked parts. These methods typically include an encoder accepting visible patches (normalized) and corresponding patch centers (position) as input, with the decoder accepting the output of the encoder and the centers (position) of the masked parts to reconstruct each point in the masked patches. Then, the pre-trained encoders are used for downstream tasks. In this paper, we show a motivating empirical result that when directly feeding the centers of masked patches to the decoder without information from the encoder, it still reconstructs well. In other words, the centers of patches are important and the reconstruction objective does not necessarily rely on representations of the encoder, thus preventing the encoder from learning semantic representations. Based on this key observation, we propose a simple yet effective method, i.e., learning to Predict Centers for Point Masked AutoEncoders (PCP-MAE) which guides the model to learn to predict the significant centers and use the predicted centers to replace the directly provided centers. Specifically, we propose a Predicting Center Module (PCM) that shares parameters with the original encoder with extra cross-attention to predict centers. Our method is of high pre-training efficiency compared to other alternatives and achieves great improvement over Point-MAE, particularly outperforming it by 5.50%, 6.03%, and 5.17% on three variants of ScanObjectNN. The code will be made publicly available.
Read more8/19/2024
✨
0
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Siming Yan, Yuqi Yang, Yuxiao Guo, Hao Pan, Peng-shuai Wang, Xin Tong, Yang Liu, Qixing Huang
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Read more4/30/2024
0
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Bin Ren, Guofeng Mei, Danda Pani Paudel, Weijie Wang, Yawei Li, Mengyuan Liu, Rita Cucchiara, Luc Van Gool, Nicu Sebe
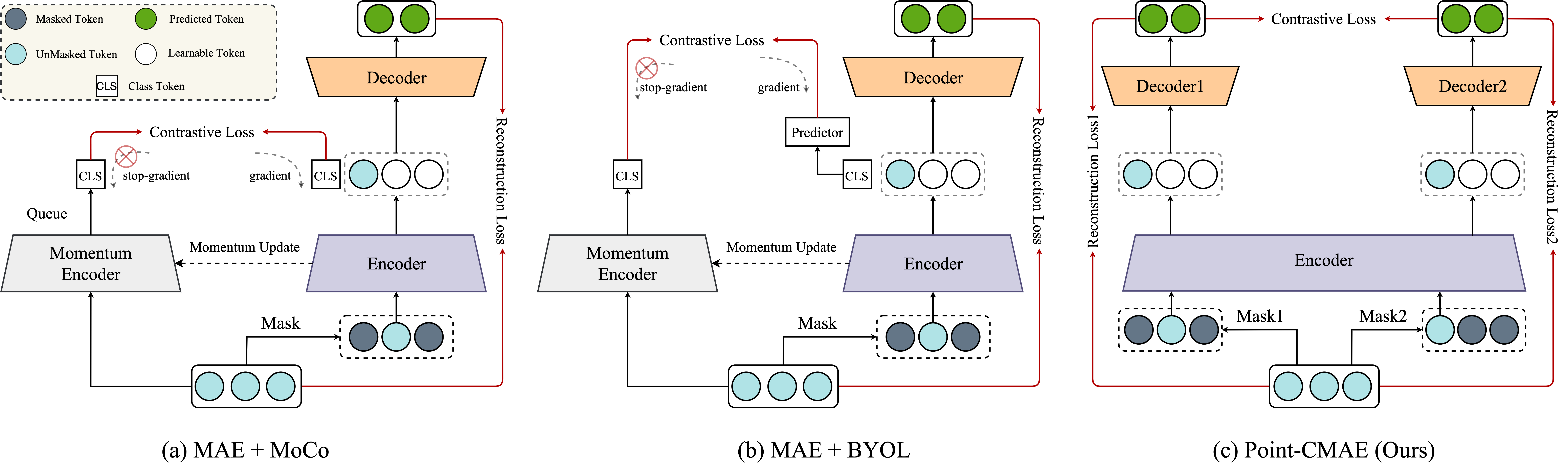
Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.
Read more7/9/2024
📈
0
DiffPMAE: Diffusion Masked Autoencoders for Point Cloud Reconstruction
Yanlong Li, Chamara Madarasingha, Kanchana Thilakarathna
Point cloud streaming is increasingly getting popular, evolving into the norm for interactive service delivery and the future Metaverse. However, the substantial volume of data associated with point clouds presents numerous challenges, particularly in terms of high bandwidth consumption and large storage capacity. Despite various solutions proposed thus far, with a focus on point cloud compression, upsampling, and completion, these reconstruction-related methods continue to fall short in delivering high fidelity point cloud output. As a solution, in DiffPMAE, we propose an effective point cloud reconstruction architecture. Inspired by self-supervised learning concepts, we combine Masked Auto-Encoding and Diffusion Model mechanism to remotely reconstruct point cloud data. By the nature of this reconstruction process, DiffPMAE can be extended to many related downstream tasks including point cloud compression, upsampling and completion. Leveraging ShapeNet-55 and ModelNet datasets with over 60000 objects, we validate the performance of DiffPMAE exceeding many state-of-the-art methods in-terms of auto-encoding and downstream tasks considered.
Read more8/16/2024