P$^2$-ViT: Power-of-Two Post-Training Quantization and Acceleration for Fully Quantized Vision Transformer

0

Sign in to get full access
Overview
- Presents a novel post-training quantization technique called "Power-of-Two Post-Training Quantization (P2-ViT)" for fully quantizing Vision Transformers (ViTs)
- Demonstrates that P2-ViT can achieve high accuracy on image classification tasks while enabling efficient hardware acceleration
- Provides a comprehensive survey of model compression and acceleration techniques for Vision Transformers, including Q-HyViT, TRIO-ViT, and Model Quantization for Hardware Acceleration of Vision Transformers: A Comprehensive Survey
Plain English Explanation
The paper introduces a new technique called "Power-of-Two Post-Training Quantization (P2-ViT)" that can significantly reduce the size and computational requirements of Vision Transformer (ViT) models without sacrificing their performance on image classification tasks.
ViTs are a type of machine learning model that have shown impressive results in various computer vision applications. However, their large size and high computational demands can make them challenging to deploy on resource-constrained devices like smartphones or edge computing platforms.
P2-ViT addresses this problem by quantizing the model's weights and activations to powers of two, which allows for efficient hardware acceleration. The researchers demonstrate that P2-ViT can achieve high accuracy on popular image classification benchmarks while reducing the model's size and inference time by up to 4x compared to the original ViT.
This work builds on previous research in model quantization and ViT acceleration, providing a comprehensive survey of techniques for optimizing ViTs for deployment on real-world systems.
Technical Explanation
The core idea of P2-ViT is to quantize the weights and activations of the ViT model to powers of two, which enables efficient hardware acceleration. The researchers start by conducting a thorough analysis of the numerical properties of ViT models, revealing that the weights and activations can be well approximated by powers of two without significant loss in accuracy.
Building on this insight, the authors propose the P2-ViT quantization scheme, which includes the following key components:
- Power-of-Two Quantization: The weights and activations are quantized to the nearest power of two, reducing the number of bits required to represent each value.
- Customized Quantization Ranges: The quantization range for each layer is optimized individually to minimize the quantization error.
- Efficient Inference: The quantized model can be efficiently executed on hardware that supports power-of-two operations, such as bit-shifts and bit-wise operations.
The researchers evaluate P2-ViT on several image classification benchmarks, including ImageNet, and demonstrate that it can achieve comparable or even superior accuracy compared to the original ViT models while providing up to 4x reduction in model size and inference time.
The paper also provides a comprehensive survey of other model compression and acceleration techniques for Vision Transformers, including Q-HyViT, TRIO-ViT, and a broader survey of model quantization and hardware acceleration methods.
Critical Analysis
The paper presents a strong technical contribution in the form of the P2-ViT quantization technique, which effectively leverages the numerical properties of ViT models to enable efficient hardware acceleration. The authors provide a thorough evaluation of their approach on several benchmarks, demonstrating its effectiveness in terms of both accuracy and inference efficiency.
One potential limitation of the work is that it focuses solely on image classification tasks, and it's unclear how well the P2-ViT approach would generalize to other computer vision tasks, such as object detection or semantic segmentation. Additionally, the paper does not explore the impact of the quantization on the model's robustness or its ability to transfer to other domains, which could be an important consideration for real-world applications.
The comprehensive survey of related techniques, such as Q-HyViT, TRIO-ViT, and the broader survey of model quantization and hardware acceleration methods, provides a valuable resource for researchers and practitioners interested in optimizing ViT models for real-world deployment.
Conclusion
The P2-ViT paper introduces a novel post-training quantization technique that can effectively reduce the size and computational requirements of Vision Transformer models without sacrificing their performance on image classification tasks. By leveraging the numerical properties of ViTs and enabling efficient hardware acceleration, P2-ViT represents an important step forward in making these powerful models more accessible for deployment on resource-constrained devices.
The comprehensive survey of related work in this area provides a useful reference for researchers and engineers working on model compression and acceleration for Vision Transformers. As the field of deep learning continues to evolve, techniques like P2-ViT will play a crucial role in bridging the gap between the capabilities of advanced models and the practical constraints of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
P$^2$-ViT: Power-of-Two Post-Training Quantization and Acceleration for Fully Quantized Vision Transformer
Huihong Shi, Xin Cheng, Wendong Mao, Zhongfeng Wang
Vision Transformers (ViTs) have excelled in computer vision tasks but are memory-consuming and computation-intensive, challenging their deployment on resource-constrained devices. To tackle this limitation, prior works have explored ViT-tailored quantization algorithms but retained floating-point scaling factors, which yield non-negligible re-quantization overhead, limiting ViTs' hardware efficiency and motivating more hardware-friendly solutions. To this end, we propose emph{P$^2$-ViT}, the first underline{P}ower-of-Two (PoT) underline{p}ost-training quantization and acceleration framework to accelerate fully quantized ViTs. Specifically, {as for quantization,} we explore a dedicated quantization scheme to effectively quantize ViTs with PoT scaling factors, thus minimizing the re-quantization overhead. Furthermore, we propose coarse-to-fine automatic mixed-precision quantization to enable better accuracy-efficiency trade-offs. {In terms of hardware,} we develop {a dedicated chunk-based accelerator} featuring multiple tailored sub-processors to individually handle ViTs' different types of operations, alleviating reconfigurable overhead. Additionally, we design {a tailored row-stationary dataflow} to seize the pipeline processing opportunity introduced by our PoT scaling factors, thereby enhancing throughput. Extensive experiments consistently validate P$^2$-ViT's effectiveness. {Particularly, we offer comparable or even superior quantization performance with PoT scaling factors when compared to the counterpart with floating-point scaling factors. Besides, we achieve up to $mathbf{10.1times}$ speedup and $mathbf{36.8times}$ energy saving over GPU's Turing Tensor Cores, and up to $mathbf{1.84times}$ higher computation utilization efficiency against SOTA quantization-based ViT accelerators. Codes are available at url{https://github.com/shihuihong214/P2-ViT}.
Read more5/31/2024
0
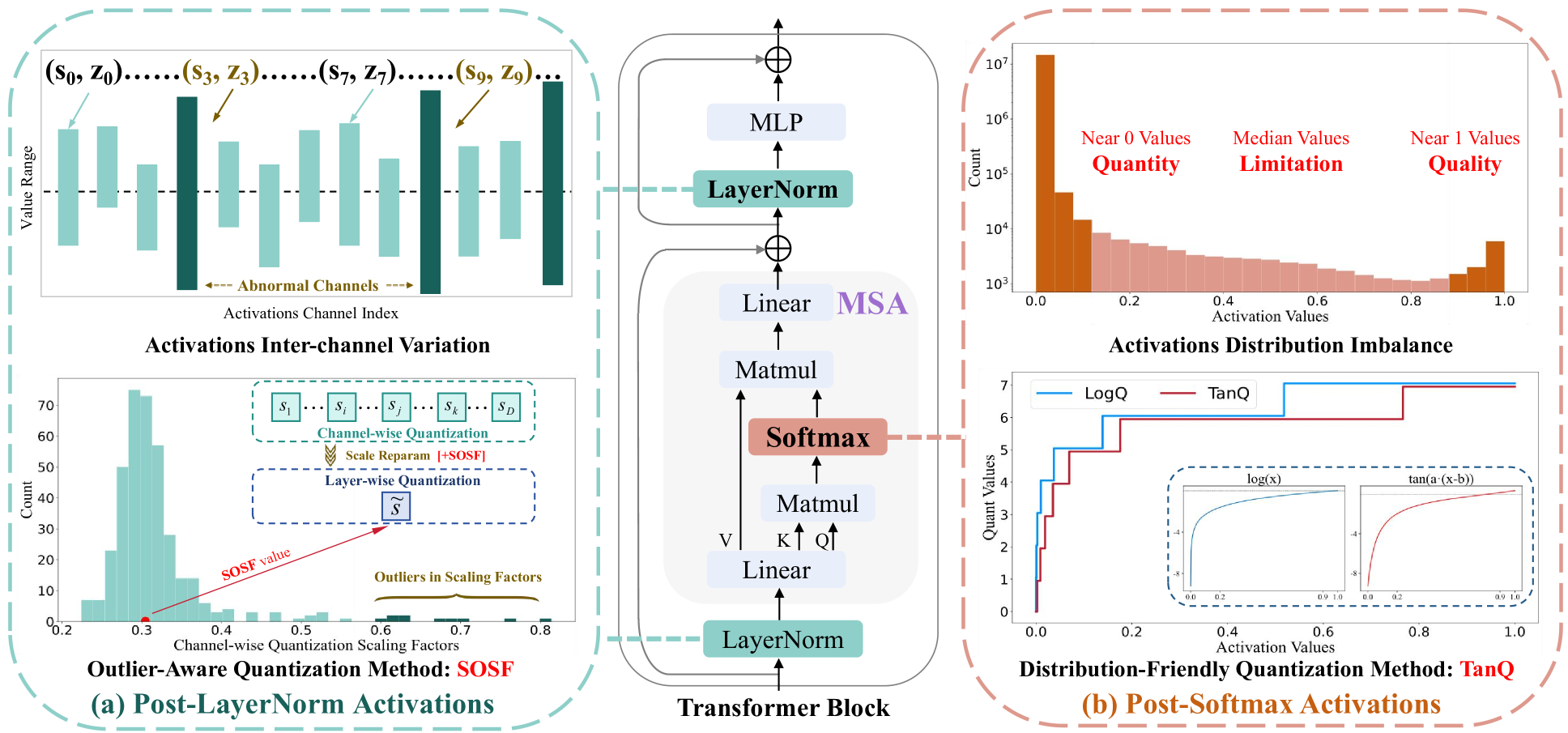
DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training Quantization for Vision Transformers
Lianwei Yang, Haisong Gong, Qingyi Gu
Vision transformers (ViTs) have garnered significant attention for their performance in vision tasks, but the high computational cost and significant latency issues have hindered widespread adoption. Post-training quantization (PTQ), a promising method for model compression, still faces accuracy degradation challenges with ViTs. There are two reasons for this: the existing quantization paradigm does not fit the power-law distribution of post-Softmax activations well, and accuracy inevitably decreases after reparameterizing post-LayerNorm activations. We propose a Distribution-Friendly and Outlier-Aware Post-training Quantization method for Vision Transformers, named DopQ-ViT. DopQ-ViT analyzes the inefficiencies of current quantizers and introduces a distribution-friendly Tan Quantizer called TanQ. TanQ focuses more on values near 1, more accurately preserving the power-law distribution of post-Softmax activations, and achieves favorable results. Besides, during the reparameterization of post-LayerNorm activations from channel-wise to layer-wise quantization, the accuracy degradation is mainly due to the significant impact of outliers in the scaling factors. Therefore, DopQ-ViT proposes a method to select Median as the Optimal Scaling Factor, denoted as MOSF, which compensates for the influence of outliers and preserves the performance of the quantization model. DopQ-ViT has been extensively validated and significantly improves the performance of quantization models, especially in low-bit settings.
Read more8/19/2024
👀
0
Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
Read more5/20/2024
0
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
Huihong Shi, Haikuo Shao, Wendong Mao, Zhongfeng Wang
Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with textit{standard ViTs}, we focus our attention towards the quantization and acceleration for textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $uparrow$$mathbf{7.2}times$ and $uparrow$$mathbf{14.6}times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $uparrow$$mathbf{5.9}times$ and $uparrow$$mathbf{2.0}times$ DSP efficiency.} Codes will be released publicly upon acceptance.
Read more5/8/2024