Pearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset

0

Sign in to get full access
Overview
- This paper introduces Pearl, a new dataset for conversational recommendation systems that incorporates persona information and product reviews.
- The dataset aims to facilitate research on building more natural and engaging conversational recommendation agents.
- Key features of the dataset include persona profiles, product reviews, and multi-turn dialogues between users and agents.
Plain English Explanation
The researchers who created this Pearl dataset want to help develop better conversational AI assistants that can recommend products to users in a more natural, human-like way. Typical recommendation systems often just suggest items based on user preferences, without much context or personality.
The Pearl dataset provides more realistic information that can be used to train these conversational AI models. It includes detailed persona profiles for the users, with information about their interests, traits, and backgrounds. It also includes real product reviews that users have written, which can give the AI a better understanding of how people actually discuss and evaluate products.
By training AI on this kind of rich, contextual data, the researchers hope to create recommendation agents that can engage in more natural, back-and-forth conversations. The agents would be able to learn about the user's unique preferences and personality, and then make recommendations that feel more personalized and relevant.
Technical Explanation
The Pearl dataset contains a large number of multi-turn dialogues between users and conversational agents discussing and recommending various products. Each user is associated with a detailed persona profile that includes their interests, traits, and background information. The dialogues also incorporate realistic product reviews written by the users.
The goal is to enable the development of more advanced conversational recommendation systems that can leverage this persona and review data to have more natural, engaging interactions. Typical recommendation approaches often focus narrowly on predicting user preferences, without considering the social and emotional context of the conversation.
In contrast, the Pearl dataset allows researchers to explore techniques for building recommendation agents that can adaptively respond to the user's personality, interests, and opinions expressed through the dialogue and product reviews. This could lead to more personalized and persuasive recommendation experiences.
The dataset was collected through crowdsourcing, with trained annotators roleplaying as users and agents in simulated recommendation conversations. Rigorous quality control measures were used to ensure the dialogues were coherent and representative of real-world interactions.
Critical Analysis
The Pearl dataset represents an important step forward in enabling more sophisticated conversational recommendation systems. By incorporating persona profiles and product reviews, it provides a richer, more realistic testbed for developing AI agents that can engage in natural, contextual dialogues.
However, some potential limitations of the dataset should be considered. The dialogues were generated through crowdsourcing, so they may not fully capture the nuance and complexity of real human-AI interactions. There could also be biases in the persona profiles and review data that need to be carefully accounted for.
Additionally, while the dataset is large, it may not cover the full breadth of product categories, user demographics, and conversational scenarios that real-world recommendation systems would need to handle. Supplementary datasets or data augmentation techniques may be required to achieve broad, generalizable performance.
Researchers utilizing the Pearl dataset should also be mindful of potential ethical concerns around the use of personal data and the development of AI systems that could perpetuate harmful stereotypes or biases. Careful consideration of these issues will be essential as the field of conversational recommendation continues to advance.
Conclusion
The Pearl dataset represents an important contribution to the field of conversational recommendation systems. By incorporating persona profiles and product reviews, it enables the development of AI agents that can engage in more natural, context-aware dialogues with users.
Leveraging this dataset, researchers can explore new techniques for building recommendation systems that are better able to understand and respond to the unique preferences, traits, and opinions of individual users. This could lead to more personalized, persuasive, and engaging recommendation experiences that better meet the needs of diverse users.
While the dataset has some limitations, it provides a valuable testbed for advancing the state-of-the-art in conversational recommendation. As the field continues to evolve, the insights and innovations enabled by the Pearl dataset could have far-reaching implications for how people interact with and discover new products and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset
Minjin Kim, Minju Kim, Hana Kim, Beong-woo Kwak, Soyeon Chun, Hyunseo Kim, SeongKu Kang, Youngjae Yu, Jinyoung Yeo, Dongha Lee
Conversational recommender system is an emerging area that has garnered an increasing interest in the community, especially with the advancements in large language models (LLMs) that enable diverse reasoning over conversational input. Despite the progress, the field has many aspects left to explore. The currently available public datasets for conversational recommendation lack specific user preferences and explanations for recommendations, hindering high-quality recommendations. To address such challenges, we present a novel conversational recommendation dataset named PEARL, synthesized with persona- and knowledge-augmented LLM simulators. We obtain detailed persona and knowledge from real-world reviews and construct a large-scale dataset with over 57k dialogues. Our experimental results demonstrate that utterances in PEARL include more specific user preferences, show expertise in the target domain, and provide recommendations more relevant to the dialogue context than those in prior datasets.
Read more6/11/2024

0
Persona-DB: Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement
Chenkai Sun, Ke Yang, Revanth Gangi Reddy, Yi R. Fung, Hou Pong Chan, Kevin Small, ChengXiang Zhai, Heng Ji
The increasing demand for personalized interactions with large language models (LLMs) calls for methodologies capable of accurately and efficiently identifying user opinions and preferences. Retrieval augmentation emerges as an effective strategy, as it can accommodate a vast number of users without the costs from fine-tuning. Existing research, however, has largely focused on enhancing the retrieval stage and devoted limited exploration toward optimizing the representation of the database, a crucial aspect for tasks such as personalization. In this work, we examine the problem from a novel angle, focusing on how data can be better represented for more data-efficient retrieval in the context of LLM customization. To tackle this challenge, we introduce Persona-DB, a simple yet effective framework consisting of a hierarchical construction process to improve generalization across task contexts and collaborative refinement to effectively bridge knowledge gaps among users. In the evaluation of response prediction, Persona-DB demonstrates superior context efficiency in maintaining accuracy with a significantly reduced retrieval size, a critical advantage in scenarios with extensive histories or limited context windows. Our experiments also indicate a marked improvement of over 10% under cold-start scenarios, when users have extremely sparse data. Furthermore, our analysis reveals the increasing importance of collaborative knowledge as the retrieval capacity expands.
Read more8/22/2024

0
Recent Trends in Personalized Dialogue Generation: A Review of Datasets, Methodologies, and Evaluations
Yi-Pei Chen, Noriki Nishida, Hideki Nakayama, Yuji Matsumoto
Enhancing user engagement through personalization in conversational agents has gained significance, especially with the advent of large language models that generate fluent responses. Personalized dialogue generation, however, is multifaceted and varies in its definition -- ranging from instilling a persona in the agent to capturing users' explicit and implicit cues. This paper seeks to systemically survey the recent landscape of personalized dialogue generation, including the datasets employed, methodologies developed, and evaluation metrics applied. Covering 22 datasets, we highlight benchmark datasets and newer ones enriched with additional features. We further analyze 17 seminal works from top conferences between 2021-2023 and identify five distinct types of problems. We also shed light on recent progress by LLMs in personalized dialogue generation. Our evaluation section offers a comprehensive summary of assessment facets and metrics utilized in these works. In conclusion, we discuss prevailing challenges and envision prospect directions for future research in personalized dialogue generation.
Read more5/29/2024
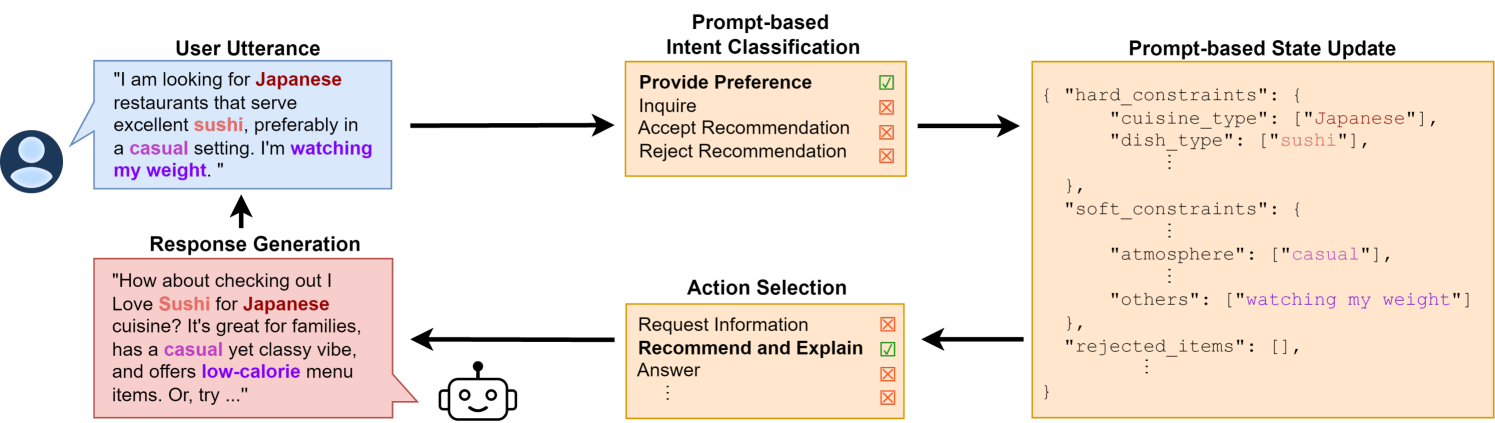
0
Retrieval-Augmented Conversational Recommendation with Prompt-based Semi-Structured Natural Language State Tracking
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Korikov, Scott Sanner
Conversational recommendation (ConvRec) systems must understand rich and diverse natural language (NL) expressions of user preferences and intents, often communicated in an indirect manner (e.g., I'm watching my weight). Such complex utterances make retrieving relevant items challenging, especially if only using often incomplete or out-of-date metadata. Fortunately, many domains feature rich item reviews that cover standard metadata categories and offer complex opinions that might match a user's interests (e.g., classy joint for a date). However, only recently have large language models (LLMs) let us unlock the commonsense connections between user preference utterances and complex language in user-generated reviews. Further, LLMs enable novel paradigms for semi-structured dialogue state tracking, complex intent and preference understanding, and generating recommendations, explanations, and question answers. We thus introduce a novel technology RA-Rec, a Retrieval-Augmented, LLM-driven dialogue state tracking system for ConvRec, showcased with a video, open source GitHub repository, and interactive Google Colab notebook.
Read more6/4/2024