Persona-DB: Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement

0

Sign in to get full access
Overview
- Persona-DB is a novel approach for efficiently personalizing large language models (LLMs) for response prediction tasks.
- It leverages collaborative data refinement to improve the quality of personalized model outputs.
- The paper presents a detailed evaluation of Persona-DB's performance on various response prediction benchmarks.
Plain English Explanation
Large language models (LLMs) are powerful tools that can generate human-like text on a wide range of topics. However, these models are often trained on broad, generic data, which can limit their ability to respond in a personalized way. <a href="https://aimodels.fyi/papers/arxiv/optimization-methods-personalizing-large-language-models-through">Persona-DB</a> aims to address this by efficiently personalizing LLMs for response prediction tasks.
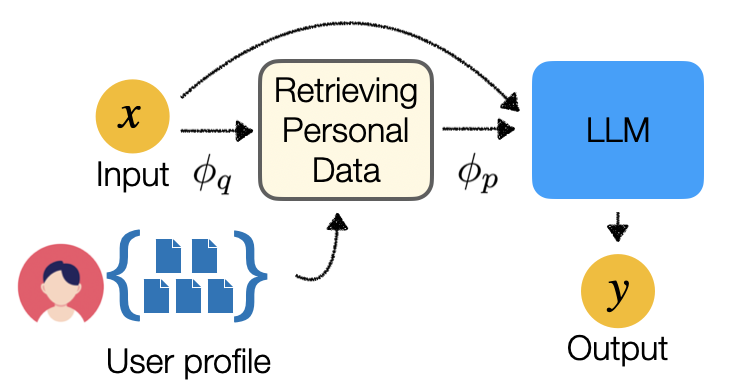
The key idea behind Persona-DB is to use a "persona database" - a collection of user profiles that capture personal attributes, preferences, and communication styles. When generating responses, the model can then leverage this persona information to tailor its output to the specific user. To further improve the quality of the personalized responses, Persona-DB also employs a collaborative data refinement process, where users can provide feedback on the model's outputs, and this feedback is used to iteratively refine the persona database and the model itself.
The paper provides a detailed evaluation of Persona-DB's performance on various response prediction benchmarks, demonstrating its ability to generate more relevant and personalized responses compared to standard LLMs. This work has important implications for building more engaging and personalized conversational AI systems, which could have applications in areas like customer service, mental health support, and educational chatbots.
Technical Explanation
The <a href="https://aimodels.fyi/papers/arxiv/scaling-synthetic-data-creation-1000000000-personas">Persona-DB</a> framework consists of three key components:
-
Persona Database: A collection of user profiles that capture personal attributes, preferences, and communication styles. These profiles serve as a knowledge base that the LLM can leverage when generating personalized responses.
-
Personalization Module: This module takes the user's persona information and the conversation context as input, and then generates a personalized response using the LLM.
-
Collaborative Data Refinement: Users can provide feedback on the model's responses, which is then used to iteratively refine the persona database and update the LLM's parameters, improving the quality of future responses.
The paper evaluates Persona-DB's performance on several response prediction tasks, including empathetic dialogue, persona-based conversation, and open-domain chat. The results show that Persona-DB outperforms standard LLMs in terms of response relevance, coherence, and personalization, demonstrating the effectiveness of the collaborative data refinement process.
The <a href="https://aimodels.fyi/papers/arxiv/apollonion-profile-centric-dialog-agent">paper</a> also discusses potential limitations and future research directions, such as exploring more advanced persona modeling techniques and investigating the scalability of the collaborative data refinement process.
Critical Analysis
The Persona-DB approach presents a promising solution for improving the personalization capabilities of large language models. The use of a persona database and collaborative data refinement seems to be an effective way to capture and leverage user-specific information to generate more relevant and engaging responses.
However, the paper does not address some potential limitations and challenges that may arise in real-world deployment scenarios. For instance, the scalability of the collaborative data refinement process may be a concern, as gathering and incorporating user feedback at a large scale could be resource-intensive. Additionally, the paper does not discuss the potential privacy and ethical implications of maintaining a detailed persona database, which could raise concerns about data privacy and the potential for misuse.
Furthermore, the paper's evaluation focuses primarily on response prediction tasks, and it would be interesting to see how the Persona-DB approach performs on more open-ended and complex dialogue tasks, where the ability to maintain coherent and contextually-appropriate personas over longer conversations may be more challenging.
Overall, the Persona-DB approach is a valuable contribution to the field of personalized conversational AI, and the insights and techniques presented in the paper could inspire further research and development in this area. However, careful consideration of the potential limitations and ethical implications will be crucial as this technology continues to evolve.
Conclusion
The <a href="https://aimodels.fyi/papers/arxiv/steerability-large-language-models-toward-data-driven">Persona-DB</a> paper introduces an efficient and effective approach for personalizing large language models for response prediction tasks. By leveraging a persona database and a collaborative data refinement process, the framework can generate more relevant and personalized responses compared to standard LLMs.
The detailed evaluation presented in the paper demonstrates the potential of this technology to improve the quality and engagement of conversational AI systems, with applications in customer service, mental health support, and educational chatbots, among others. However, the paper also highlights the need to consider potential limitations and ethical implications, such as the scalability of the collaborative data refinement process and the privacy concerns associated with maintaining a detailed persona database.
Overall, the Persona-DB work represents an important step forward in the development of more personalized and engaging conversational AI systems, and the insights and techniques presented in the paper could serve as a foundation for further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Persona-DB: Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement
Chenkai Sun, Ke Yang, Revanth Gangi Reddy, Yi R. Fung, Hou Pong Chan, Kevin Small, ChengXiang Zhai, Heng Ji
The increasing demand for personalized interactions with large language models (LLMs) calls for methodologies capable of accurately and efficiently identifying user opinions and preferences. Retrieval augmentation emerges as an effective strategy, as it can accommodate a vast number of users without the costs from fine-tuning. Existing research, however, has largely focused on enhancing the retrieval stage and devoted limited exploration toward optimizing the representation of the database, a crucial aspect for tasks such as personalization. In this work, we examine the problem from a novel angle, focusing on how data can be better represented for more data-efficient retrieval in the context of LLM customization. To tackle this challenge, we introduce Persona-DB, a simple yet effective framework consisting of a hierarchical construction process to improve generalization across task contexts and collaborative refinement to effectively bridge knowledge gaps among users. In the evaluation of response prediction, Persona-DB demonstrates superior context efficiency in maintaining accuracy with a significantly reduced retrieval size, a critical advantage in scenarios with extensive histories or limited context windows. Our experiments also indicate a marked improvement of over 10% under cold-start scenarios, when users have extremely sparse data. Furthermore, our analysis reveals the increasing importance of collaborative knowledge as the retrieval capacity expands.
Read more8/22/2024
0
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Read more4/10/2024

0
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu
We propose a novel persona-driven data synthesis methodology that leverages various perspectives within a large language model (LLM) to create diverse synthetic data. To fully exploit this methodology at scale, we introduce Persona Hub -- a collection of 1 billion diverse personas automatically curated from web data. These 1 billion personas (~13% of the world's total population), acting as distributed carriers of world knowledge, can tap into almost every perspective encapsulated within the LLM, thereby facilitating the creation of diverse synthetic data at scale for various scenarios. By showcasing Persona Hub's use cases in synthesizing high-quality mathematical and logical reasoning problems, instructions (i.e., user prompts), knowledge-rich texts, game NPCs and tools (functions) at scale, we demonstrate persona-driven data synthesis is versatile, scalable, flexible, and easy to use, potentially driving a paradigm shift in synthetic data creation and applications in practice, which may have a profound impact on LLM research and development.
Read more7/1/2024
0
Apollonion: Profile-centric Dialog Agent
Shangyu Chen, Zibo Zhao, Yuanyuan Zhao, Xiang Li
The emergence of Large Language Models (LLMs) has innovated the development of dialog agents. Specially, a well-trained LLM, as a central process unit, is capable of providing fluent and reasonable response for user's request. Besides, auxiliary tools such as external knowledge retrieval, personalized character for vivid response, short/long-term memory for ultra long context management are developed, completing the usage experience for LLM-based dialog agents. However, the above-mentioned techniques does not solve the issue of textbf{personalization from user perspective}: agents response in a same fashion to different users, without consideration of their features, such as habits, interests and past experience. In another words, current implementation of dialog agents fail in ``knowing the user''. The capacity of well-description and representation of user is under development. In this work, we proposed a framework for dialog agent to incorporate user profiling (initialization, update): user's query and response is analyzed and organized into a structural user profile, which is latter served to provide personal and more precise response. Besides, we proposed a series of evaluation protocols for personalization: to what extend the response is personal to the different users. The framework is named as method{}, inspired by inscription of ``Know Yourself'' in the temple of Apollo (also known as method{}) in Ancient Greek. Few works have been conducted on incorporating personalization into LLM, method{} is a pioneer work on guiding LLM's response to meet individuation via the application of dialog agents, with a set of evaluation methods for measurement in personalization.
Read more4/16/2024