A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners
2406.11050
0
0
Abstract
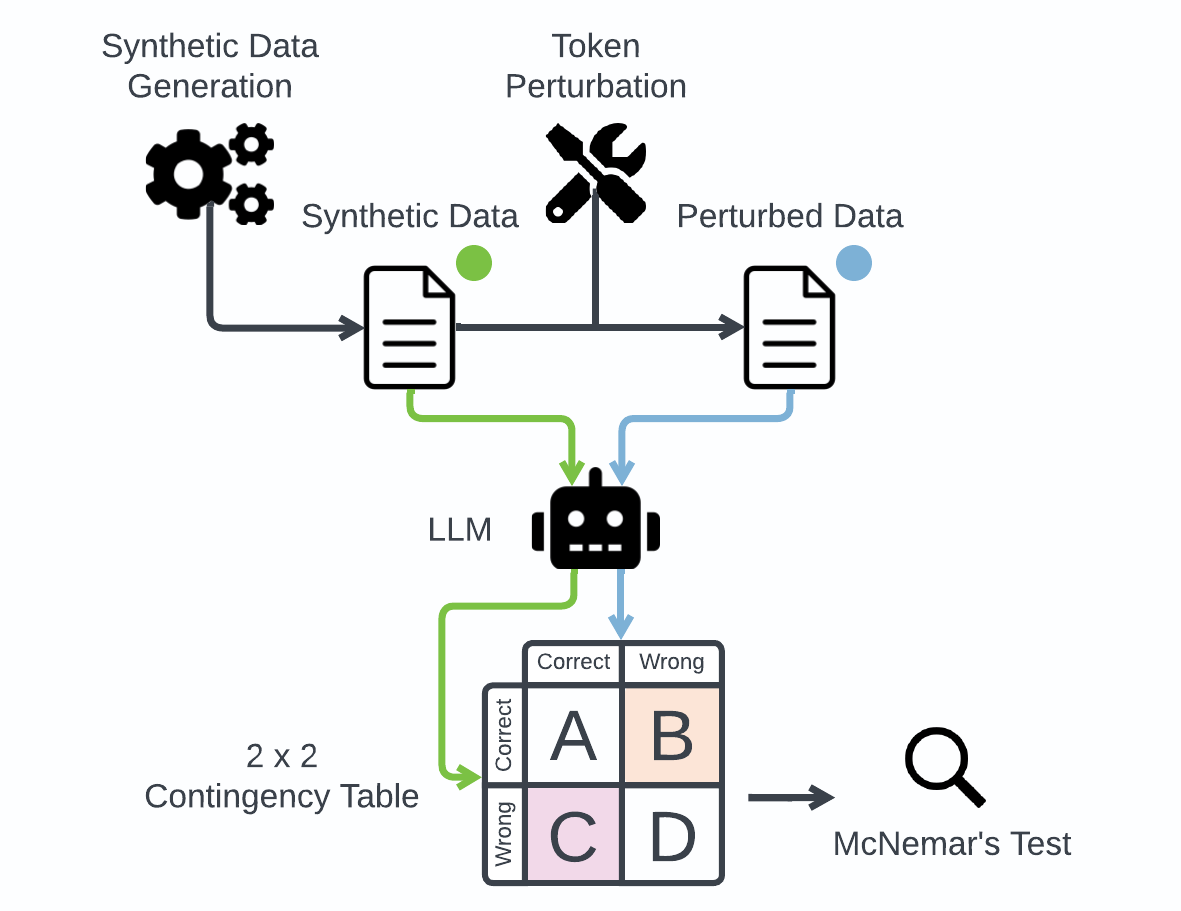
This study introduces a hypothesis-testing framework to assess whether large language models (LLMs) possess genuine reasoning abilities or primarily depend on token bias. We go beyond evaluating LLMs on accuracy; rather, we aim to investigate their token bias in solving logical reasoning tasks. Specifically, we develop carefully controlled synthetic datasets, featuring conjunction fallacy and syllogistic problems. Our framework outlines a list of hypotheses where token biases are readily identifiable, with all null hypotheses assuming genuine reasoning capabilities of LLMs. The findings in this study suggest, with statistical guarantee, that most LLMs still struggle with logical reasoning. While they may perform well on classic problems, their success largely depends on recognizing superficial patterns with strong token bias, thereby raising concerns about their actual reasoning and generalization abilities.
Create account to get full access
Overview
- This paper examines the biases present in the token-level outputs of large language models (LLMs), highlighting that they are not yet genuine reasoners.
- The authors investigate whether LLMs can engage in genuine logical reasoning or if their performance is primarily driven by statistical patterns in their training data.
- They propose a framework for probing the reasoning abilities of LLMs and present empirical results that suggest LLMs struggle with tasks that require genuine deductive reasoning.
Plain English Explanation
The paper explores whether large language models (LLMs) like GPT-3 can truly reason and understand concepts, or if they are simply very good at predicting the next word based on statistical patterns in their training data. The researchers developed a framework to test the reasoning abilities of LLMs by looking at the biases in the tokens (individual words) they output.
The key idea is that if an LLM is a genuine reasoner, it should be able to logically deduce the correct answer for a given task, rather than just relying on common patterns in the training data. The researchers designed experiments to see how LLMs would perform on tasks that require logical reasoning, rather than just recognizing familiar patterns.
Their results suggest that current LLMs struggle with these types of logical reasoning tasks and are still heavily biased by the statistical patterns in their training data. This means they are not yet true "reasoners" and have limitations in their ability to engage in genuine, deductive thinking.
The paper's findings have important implications for the development of AI systems that can truly understand and reason about the world, rather than just mimicking human language. It suggests that more work is needed to build AI models that can go beyond pattern recognition and engage in deeper, more flexible reasoning.
Technical Explanation
The paper proposes a framework for probing the reasoning abilities of large language models (LLMs) by examining the biases present in their token-level outputs. The authors argue that if an LLM is a genuine reasoner, it should be able to logically deduce the correct answer for a given task, rather than simply relying on statistical patterns in its training data.
To test this, the researchers designed experiments that challenged LLMs with tasks requiring logical reasoning, such as evaluating deductive competence and attention-driven reasoning. They found that current LLMs struggle with these types of tasks and are heavily biased by the statistical patterns in their training data, suggesting they are not yet true "reasoners."
The paper builds on previous work in evaluating reasoning behavior and logical reasoning ability of LLMs. The authors argue that understanding the specific biases and limitations of LLMs is crucial for developing AI systems that can engage in genuine, deductive reasoning.
Critical Analysis
The paper provides valuable insights into the limitations of current large language models (LLMs) in terms of their reasoning abilities. The authors' framework for probing token-level biases is a novel approach that sheds light on the underlying mechanisms driving LLM performance.
One potential limitation of the study is the specific set of tasks and experiments used to evaluate reasoning abilities. While the authors have carefully selected tasks that require logical reasoning, there may be other forms of reasoning or cognitive capabilities that were not fully captured. Additionally, the performance of LLMs may improve as the models and training techniques continue to evolve.
The paper also raises important questions about the nature of intelligence and cognition. If current LLMs are not genuine reasoners, then what does it mean to be a "true" reasoner? This issue touches on fundamental debates in artificial intelligence, philosophy of mind, and cognitive science.
Further research is needed to better understand the strengths and limitations of LLMs, as well as to explore alternative approaches to building AI systems with more flexible and robust reasoning abilities. The insights provided in this paper can serve as a valuable foundation for future work in this direction.
Conclusion
This paper presents a novel framework for probing the reasoning abilities of large language models (LLMs) by examining the biases present in their token-level outputs. The authors' findings suggest that current LLMs are not yet genuine reasoners and are heavily reliant on statistical patterns in their training data, rather than engaging in genuine logical deduction.
The implications of this research are significant for the development of AI systems that can truly understand and reason about the world, rather than simply mimicking human language. The paper highlights the need for continued progress in building AI models with more flexible and robust cognitive capabilities.
While the specific experiments and tasks used in this study have their limitations, the overall approach and insights provided can serve as a valuable foundation for future research in this important area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024
💬
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
0
0
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
4/16/2024
💬
Large Language Models are Biased Because They Are Large Language Models
Philip Resnik
0
0
This paper's primary goal is to provoke thoughtful discussion about the relationship between bias and fundamental properties of large language models. We do this by seeking to convince the reader that harmful biases are an inevitable consequence arising from the design of any large language model as LLMs are currently formulated. To the extent that this is true, it suggests that the problem of harmful bias cannot be properly addressed without a serious reconsideration of AI driven by LLMs, going back to the foundational assumptions underlying their design.
6/21/2024