PeersimGym: An Environment for Solving the Task Offloading Problem with Reinforcement Learning
2403.17637
0
0
Abstract
Task offloading, crucial for balancing computational loads across devices in networks such as the Internet of Things, poses significant optimization challenges, including minimizing latency and energy usage under strict communication and storage constraints. While traditional optimization falls short in scalability; and heuristic approaches lack in achieving optimal outcomes, Reinforcement Learning (RL) offers a promising avenue by enabling the learning of optimal offloading strategies through iterative interactions. However, the efficacy of RL hinges on access to rich datasets and custom-tailored, realistic training environments. To address this, we introduce PeersimGym, an open-source, customizable simulation environment tailored for developing and optimizing task offloading strategies within computational networks. PeersimGym supports a wide range of network topologies and computational constraints and integrates a textit{PettingZoo}-based interface for RL agent deployment in both solo and multi-agent setups. Furthermore, we demonstrate the utility of the environment through experiments with Deep Reinforcement Learning agents, showcasing the potential of RL-based approaches to significantly enhance offloading strategies in distributed computing settings. PeersimGym thus bridges the gap between theoretical RL models and their practical applications, paving the way for advancements in efficient task offloading methodologies.
Create account to get full access
Overview
- PeersimGym is an environment for solving the task offloading problem using reinforcement learning
- The task offloading problem involves deciding which computing tasks should be processed locally or offloaded to remote servers to optimize performance
- The paper presents PeersimGym, a simulation environment that allows researchers to train and evaluate reinforcement learning agents to address the task offloading challenge
Plain English Explanation
In modern computing, many tasks like data analysis or video processing can be performed either locally on a device like a smartphone or tablet, or offloaded to remote servers in the cloud. Deciding which tasks to process locally versus offloading them is called the "task offloading problem." This is an important challenge because the right choices can improve performance, reduce energy usage, and lower costs.
The researchers developed PeersimGym, a simulation environment that lets AI systems practice solving the task offloading problem. PeersimGym models a network of devices that can offload tasks to each other or to cloud servers. By training reinforcement learning algorithms in this simulated environment, the researchers aim to develop AI agents that can make intelligent offloading decisions in real-world scenarios.
The key benefit of PeersimGym is that it provides a safe, flexible testbed for experimenting with different reinforcement learning approaches to the task offloading challenge. Instead of having to deploy and test solutions in the real world, which can be costly and time-consuming, researchers can iterate quickly in the simulation to find effective AI strategies. This can accelerate progress in developing practical task offloading systems.
Technical Explanation
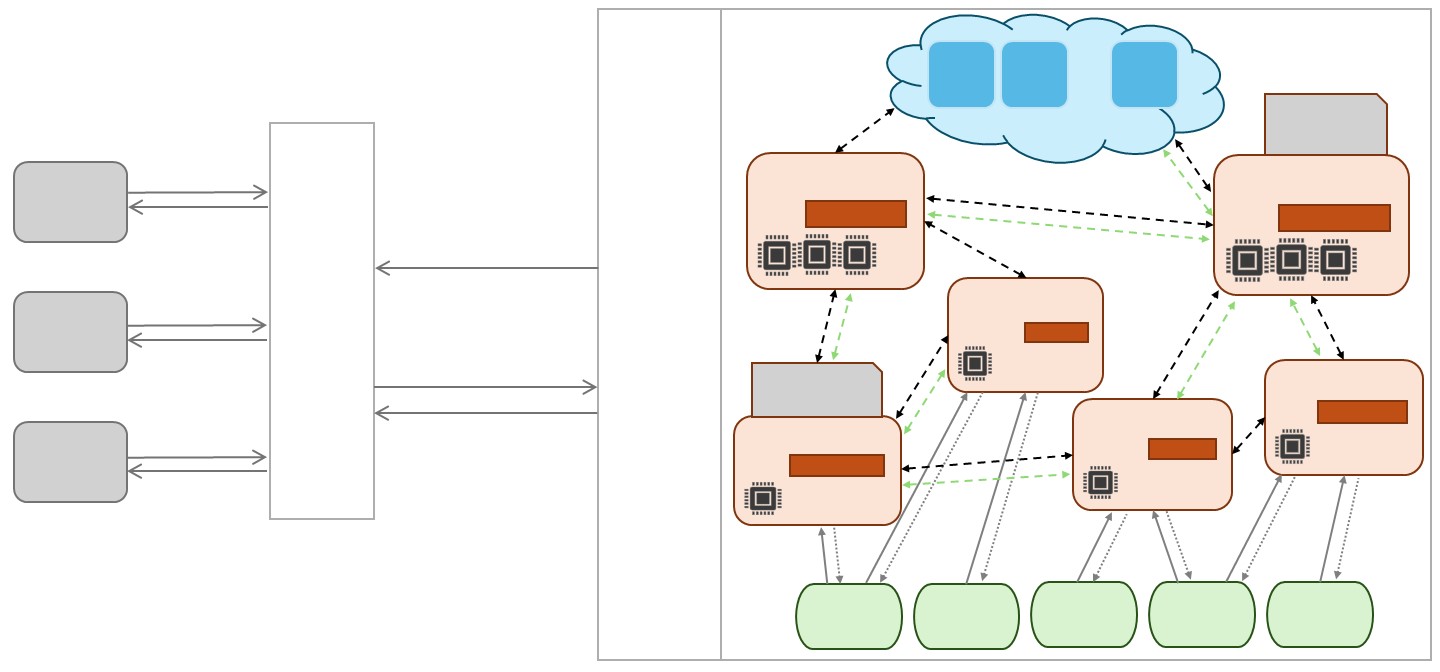
The paper presents the design and implementation of PeersimGym, a simulation environment for the task offloading problem. PeersimGym is built on top of the Peersim peer-to-peer simulator and the OpenAI Gym reinforcement learning framework.
The environment models a network of edge devices (e.g. smartphones, IoT sensors) that can offload computational tasks to each other or to a cloud server. Each device has limited processing power and energy. The goal is to develop reinforcement learning agents that can intelligently decide which tasks to execute locally versus offloading, in order to optimize performance metrics like latency, energy usage, and cost.
PeersimGym provides customizable parameters to control factors like the network topology, task arrival rates, device capabilities, and cloud server characteristics. This allows researchers to experiment with different problem setups and evaluate the robustness of their reinforcement learning solutions.
The paper demonstrates PeersimGym's utility by training a deep Q-learning agent to solve the task offloading problem. Experiments show the agent can learn effective offloading policies that outperform baseline strategies, validating the potential of PeersimGym as a research tool.
Critical Analysis
The paper provides a thorough technical description of PeersimGym and demonstrates its usefulness through initial experiments. However, it does not deeply explore the limitations or potential issues with the simulation environment.
For example, the paper acknowledges that PeersimGym's model of the task offloading problem may not fully capture the complexity of real-world edge computing systems. Factors like device mobility, network dynamics, and security/privacy concerns are simplified or omitted. Further research is needed to understand how well reinforcement learning agents trained in PeersimGym would perform in actual deployments.
Additionally, the experiments focus on a single deep Q-learning agent, but do not compare its performance to other reinforcement learning algorithms or alternative problem-solving approaches. Exploring a wider range of AI techniques could yield additional insights into effective task offloading strategies.
Overall, PeersimGym appears to be a valuable tool for accelerating research in this domain. However, the simulation's limitations should be carefully considered, and the findings from it should be validated through real-world pilots and deployments.
Conclusion
PeersimGym is a novel simulation environment that allows researchers to develop and test reinforcement learning solutions for the task offloading problem in edge computing networks. By providing a flexible, customizable testbed, PeersimGym can help drive progress in this important area of optimization for emerging distributed computing systems.
The initial experiments demonstrate the potential of reinforcement learning to learn effective offloading policies. However, further research is needed to fully assess the capabilities and limitations of PeersimGym, as well as the transferability of the AI agents it produces to real-world edge computing scenarios.
Overall, PeersimGym represents an important step forward in creating practical tools to address the task offloading challenge. As edge computing continues to grow in importance, innovations like PeersimGym will be crucial for developing intelligent, efficient systems to manage the distribution of computational tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Asad Ali Shahid, Yashraj Narang, Vincenzo Petrone, Enrico Ferrentino, Ankur Handa, Dieter Fox, Marco Pavone, Loris Roveda
0
0
In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms - PPO, SAC, and DDPG - dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym - Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick - by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results demonstrate that PBRL agents outperform non-evolutionary baseline agents across tasks essential for humanoid robots, such as bipedal locomotion, manipulation, and grasping in unstructured environments. The trained agents are finally deployed in the real world for the Franka Nut Pick manipulation task. To our knowledge, this is the first sim-to-real attempt for successfully deploying PBRL agents on real hardware. Code and videos of the learned policies are available on our project website (https://sites.google.com/view/pbrl).
6/26/2024

Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
Xinyang Gu, Yen-Jen Wang, Jianyu Chen
0
0
Humanoid-Gym is an easy-to-use reinforcement learning (RL) framework based on Nvidia Isaac Gym, designed to train locomotion skills for humanoid robots, emphasizing zero-shot transfer from simulation to the real-world environment. Humanoid-Gym also integrates a sim-to-sim framework from Isaac Gym to Mujoco that allows users to verify the trained policies in different physical simulations to ensure the robustness and generalization of the policies. This framework is verified by RobotEra's XBot-S (1.2-meter tall humanoid robot) and XBot-L (1.65-meter tall humanoid robot) in a real-world environment with zero-shot sim-to-real transfer. The project website and source code can be found at: https://sites.google.com/view/humanoid-gym/.
5/21/2024
🏅
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
0
0
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
6/6/2024

Sim-to-real Transfer of Deep Reinforcement Learning Agents for Online Coverage Path Planning
Arvi Jonnarth, Ola Johansson, Michael Felsberg
0
0
Sim-to-real transfer presents a difficult challenge, where models trained in simulation are to be deployed in the real world. The distribution shift between the two settings leads to biased representations of the perceived real-world environment, and thus to suboptimal predictions. In this work, we tackle the challenge of sim-to-real transfer of reinforcement learning (RL) agents for coverage path planning (CPP). In CPP, the task is for a robot to find a path that visits every point of a confined area. Specifically, we consider the case where the environment is unknown, and the agent needs to plan the path online while mapping the environment. We bridge the sim-to-real gap through a semi-virtual environment with a simulated sensor and obstacles, while including real robot kinematics and real-time aspects. We investigate what level of fine-tuning is needed for adapting to a realistic setting, comparing to an agent trained solely in simulation. We find that a high model inference frequency is sufficient for reducing the sim-to-real gap, while fine-tuning degrades performance initially. By training the model in simulation and deploying it at a high inference frequency, we transfer state-of-the-art results from simulation to the real domain, where direct learning would take in the order of weeks with manual interaction, i.e., would be completely infeasible.
6/10/2024