Sim-to-real Transfer of Deep Reinforcement Learning Agents for Online Coverage Path Planning
2406.04920
0
0

Abstract
Sim-to-real transfer presents a difficult challenge, where models trained in simulation are to be deployed in the real world. The distribution shift between the two settings leads to biased representations of the perceived real-world environment, and thus to suboptimal predictions. In this work, we tackle the challenge of sim-to-real transfer of reinforcement learning (RL) agents for coverage path planning (CPP). In CPP, the task is for a robot to find a path that visits every point of a confined area. Specifically, we consider the case where the environment is unknown, and the agent needs to plan the path online while mapping the environment. We bridge the sim-to-real gap through a semi-virtual environment with a simulated sensor and obstacles, while including real robot kinematics and real-time aspects. We investigate what level of fine-tuning is needed for adapting to a realistic setting, comparing to an agent trained solely in simulation. We find that a high model inference frequency is sufficient for reducing the sim-to-real gap, while fine-tuning degrades performance initially. By training the model in simulation and deploying it at a high inference frequency, we transfer state-of-the-art results from simulation to the real domain, where direct learning would take in the order of weeks with manual interaction, i.e., would be completely infeasible.
Create account to get full access
Overview
- This paper explores the challenge of transferring deep reinforcement learning (DRL) agents trained in simulation to real-world environments for online coverage path planning tasks.
- The researchers propose a novel approach that combines domain randomization, curriculum learning, and a novel reward shaping technique to enable effective sim-to-real transfer.
- The agents are trained in simulation and then deployed in real-world scenarios, demonstrating the ability to navigate and cover target areas efficiently.
Plain English Explanation
The paper discusses a way to train robots or other autonomous agents in a simulated environment, and then have those agents successfully operate in the real world. This is an important challenge, as it's often easier and safer to train agents in simulation, but the real world is much more complex and unpredictable than any simulation.
The researchers developed a new approach that combines a few key techniques to help bridge the gap between simulation and reality:
-
Domain randomization: They added a lot of variation to the simulated environment, making it less predictable and more like the real world. This helps the agents learn to be more adaptable.
-
Curriculum learning: They started the agents off in simpler environments and gradually increased the difficulty, allowing them to build up their skills incrementally.
-
Reward shaping: They carefully designed the rewards the agents receive during training to incentivize the right behaviors for the real-world task.
By using this approach, the agents were able to learn how to navigate and cover target areas efficiently in the real world, even though they were initially trained only in simulation. This is an important step forward for sim-to-real transfer of reinforcement learning agents.
Technical Explanation
The paper presents a framework for transferring deep reinforcement learning (DRL) agents trained in simulation to real-world environments for online coverage path planning tasks. The key innovations include:
-
Domain randomization: The researchers randomize various parameters of the simulated environment, such as lighting, textures, and dynamics, to improve the agents' adaptability to real-world conditions.
-
Curriculum learning: The training process starts with relatively simple environments and progressively increases the complexity, allowing the agents to build up their skills incrementally.
-
Reward shaping: The researchers design the reward function to encourage behaviors that are beneficial for the real-world coverage path planning task, such as efficient navigation and thorough coverage of the target area.
The agents are trained using proximal policy optimization (PPO), a popular DRL algorithm. During the training process, the agents are evaluated on both simulated and real-world environments to ensure effective sim-to-real transfer.
The experimental results demonstrate that the proposed approach outperforms baseline methods in terms of coverage rate and path efficiency when deployed on a real-world mobile robot platform. The agents are able to navigate the environment and cover target areas effectively, showcasing the potential of this framework for sim-to-real transfer of DRL agents.
Critical Analysis
The paper presents a well-designed and thorough approach to sim-to-real transfer of DRL agents for online coverage path planning. The researchers have carefully addressed several key challenges, such as the reality gap between simulation and the real world, and have demonstrated promising results.
However, the paper does not discuss some potential limitations or areas for further research. For example, the experiments were conducted in a relatively simple indoor environment, and it's unclear how the approach would scale to more complex, real-world scenarios with dynamic obstacles, uneven terrain, or larger target areas.
Additionally, the paper does not provide much detail on the computational and resource requirements of the proposed framework. This information would be useful for understanding the practical feasibility and deployment considerations of this approach.
It would also be interesting to see how this framework might be adapted or extended to other robotic tasks beyond coverage path planning, such as autonomous navigation or manipulation. Overall, the research presented in this paper represents an important contribution to the field of sim-to-real transfer of DRL agents, but there are still opportunities for further exploration and refinement.
Conclusion
This paper introduces a novel approach for transferring deep reinforcement learning agents trained in simulation to real-world environments for online coverage path planning tasks. The key innovations include domain randomization, curriculum learning, and reward shaping, which together enable effective sim-to-real transfer.
The experimental results demonstrate the agents' ability to navigate and cover target areas efficiently in real-world scenarios, outperforming baseline methods. This work represents an important step forward in bridging the gap between simulation and reality, which is a critical challenge for deploying autonomous systems in the real world.
The proposed framework has the potential to unlock new applications and use cases for reinforcement learning in robotics and other domains, paving the way for more robust and capable autonomous systems. As the field continues to evolve, further research is needed to address the remaining challenges and expand the capabilities of sim-to-real transfer techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
A Platform-Agnostic Deep Reinforcement Learning Framework for Effective Sim2Real Transfer in Autonomous Driving
Dianzhao Li, Ostap Okhrin
0
0
Deep Reinforcement Learning (DRL) has shown remarkable success in solving complex tasks across various research fields. However, transferring DRL agents to the real world is still challenging due to the significant discrepancies between simulation and reality. To address this issue, we propose a robust DRL framework that leverages platform-dependent perception modules to extract task-relevant information and train a lane-following and overtaking agent in simulation. This framework facilitates the seamless transfer of the DRL agent to new simulated environments and the real world with minimal effort. We evaluate the performance of the agent in various driving scenarios in both simulation and the real world, and compare it to human players and the PID baseline in simulation. Our proposed framework significantly reduces the gaps between different platforms and the Sim2Real gap, enabling the trained agent to achieve similar performance in both simulation and the real world, driving the vehicle effectively.
5/1/2024
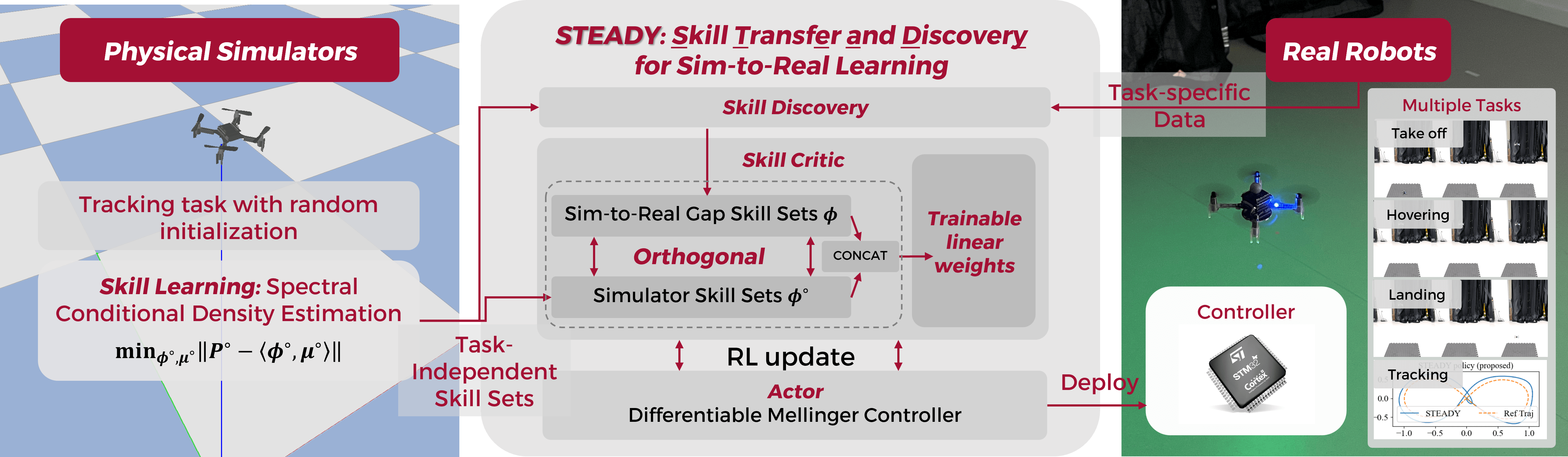
Skill Transfer and Discovery for Sim-to-Real Learning: A Representation-Based Viewpoint
Haitong Ma, Zhaolin Ren, Bo Dai, Na Li
0
0
We study sim-to-real skill transfer and discovery in the context of robotics control using representation learning. We draw inspiration from spectral decomposition of Markov decision processes. The spectral decomposition brings about representation that can linearly represent the state-action value function induced by any policies, thus can be regarded as skills. The skill representations are transferable across arbitrary tasks with the same transition dynamics. Moreover, to handle the sim-to-real gap in the dynamics, we propose a skill discovery algorithm that learns new skills caused by the sim-to-real gap from real-world data. We promote the discovery of new skills by enforcing orthogonal constraints between the skills to learn and the skills from simulators, and then synthesize the policy using the enlarged skill sets. We demonstrate our methodology by transferring quadrotor controllers from simulators to Crazyflie 2.1 quadrotors. We show that we can learn the skill representations from a single simulator task and transfer these to multiple different real-world tasks including hovering, taking off, landing and trajectory tracking. Our skill discovery approach helps narrow the sim-to-real gap and improve the real-world controller performance by up to 30.2%.
4/9/2024

DrEureka: Language Model Guided Sim-To-Real Transfer
Yecheng Jason Ma, William Liang, Hung-Ju Wang, Sam Wang, Yuke Zhu, Linxi Fan, Osbert Bastani, Dinesh Jayaraman
0
0
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
6/5/2024

Sim-to-real transfer of active suspension control using deep reinforcement learning
Viktor Wiberg, Erik Wallin, Arvid Falldin, Tobias Semberg, Morgan Rossander, Eddie Wadbro, Martin Servin
0
0
We explore sim-to-real transfer of deep reinforcement learning controllers for a heavy vehicle with active suspensions designed for traversing rough terrain. While related research primarily focuses on lightweight robots with electric motors and fast actuation, this study uses a forestry vehicle with a complex hydraulic driveline and slow actuation. We simulate the vehicle using multibody dynamics and apply system identification to find an appropriate set of simulation parameters. We then train policies in simulation using various techniques to mitigate the sim-to-real gap, including domain randomization, action delays, and a reward penalty to encourage smooth control. In reality, the policies trained with action delays and a penalty for erratic actions perform nearly at the same level as in simulation. In experiments on level ground, the motion trajectories closely overlap when turning to either side, as well as in a route tracking scenario. When faced with a ramp that requires active use of the suspensions, the simulated and real motions are in close alignment. This shows that the actuator model together with system identification yields a sufficiently accurate model of the actuators. We observe that policies trained without the additional action penalty exhibit fast switching or bang-bang control. These present smooth motions and high performance in simulation but transfer poorly to reality. We find that policies make marginal use of the local height map for perception, showing no indications of predictive planning. However, the strong transfer capabilities entail that further development concerning perception and performance can be largely confined to simulation.
5/1/2024