PEFSL: A deployment Pipeline for Embedded Few-Shot Learning on a FPGA SoC
2404.19354
0
0
📉
Abstract
This paper tackles the challenges of implementing few-shot learning on embedded systems, specifically FPGA SoCs, a vital approach for adapting to diverse classification tasks, especially when the costs of data acquisition or labeling prove to be prohibitively high. Our contributions encompass the development of an end-to-end open-source pipeline for a few-shot learning platform for object classification on a FPGA SoCs. The pipeline is built on top of the Tensil open-source framework, facilitating the design, training, evaluation, and deployment of DNN backbones tailored for few-shot learning. Additionally, we showcase our work's potential by building and deploying a low-power, low-latency demonstrator trained on the MiniImageNet dataset with a dataflow architecture. The proposed system has a latency of 30 ms while consuming 6.2 W on the PYNQ-Z1 board.
Create account to get full access
Overview
- This paper addresses the challenges of implementing few-shot learning on embedded systems, specifically FPGA SoCs.
- The researchers developed an end-to-end open-source pipeline for a few-shot learning platform for object classification on FPGA SoCs, built on the Tensil open-source framework.
- They showcase a low-power, low-latency demonstrator trained on the MiniImageNet dataset with a dataflow architecture, which has a latency of 30 ms and consumes 6.2 W on the PYNQ-Z1 board.
Plain English Explanation
The paper focuses on the challenge of enabling few-shot learning on embedded systems, like the system-on-a-chip (SoC) found in field-programmable gate arrays (FPGAs). Few-shot learning is an important approach for adapting to diverse classification tasks, especially when acquiring or labeling data is expensive.
The researchers developed an end-to-end pipeline that allows for the design, training, evaluation, and deployment of deep neural network (DNN) models tailored for few-shot learning on FPGA SoCs. This pipeline is built using the Tensil open-source framework, which simplifies the process of working with these specialized hardware platforms.
As a demonstration, the researchers created a low-power, low-latency system for object classification using the MiniImageNet dataset. This system runs on a PYNQ-Z1 board and has a latency of just 30 milliseconds while consuming only 6.2 watts of power. This shows the potential of FPGA-based spatial acceleration for few-shot learning on embedded devices.
Technical Explanation
The researchers developed an end-to-end open-source pipeline for a few-shot learning platform on FPGA SoCs. This pipeline is built on top of the Tensil open-source framework, which facilitates the design, training, evaluation, and deployment of DNN backbones tailored for few-shot learning.
As a demonstration, the researchers built and deployed a low-power, low-latency system trained on the MiniImageNet dataset. This system uses a dataflow architecture and runs on the PYNQ-Z1 board, achieving a latency of 30 ms while consuming 6.2 W of power.
Critical Analysis
The paper provides a valuable contribution by addressing the challenges of implementing few-shot learning on FPGA SoCs, which are important for enabling adaptive and efficient machine learning on embedded devices. The researchers' development of an open-source pipeline built on the Tensil framework is a significant step forward in making this technology more accessible.
However, the paper does not provide extensive details on the specific DNN architectures or training methodologies used, which would be helpful for understanding the technical details of their approach. Additionally, the researchers could have discussed the potential limitations of their system, such as the scalability to larger datasets or the generalization capabilities of the few-shot learning models.
Further research could explore the potential for FPGA-based spatial acceleration of large-scale few-shot learning models, as well as investigate ways to leverage pre-trained vision-language transformers or semantically-aided few-shot learning to further enhance the performance and efficiency of these embedded systems.
Conclusion
This paper presents an important step towards enabling few-shot learning on embedded FPGA SoCs, which is crucial for adapting machine learning models to diverse classification tasks with limited data. The researchers' development of an open-source pipeline built on the Tensil framework, along with their demonstration of a low-power, low-latency object classification system, showcases the potential of this approach. As the field of embedded FPGA developments continues to advance, this work paves the way for more efficient and adaptive machine learning on edge devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Embedded FPGA Developments in 130nm and 28nm CMOS for Machine Learning in Particle Detector Readout
Julia Gonski, Aseem Gupta, Haoyi Jia, Hyunjoon Kim, Lorenzo Rota, Larry Ruckman, Angelo Dragone, Ryan Herbst
0
0
Embedded field programmable gate array (eFPGA) technology allows the implementation of reconfigurable logic within the design of an application-specific integrated circuit (ASIC). This approach offers the low power and efficiency of an ASIC along with the ease of FPGA configuration, particularly beneficial for the use case of machine learning in the data pipeline of next-generation collider experiments. An open-source framework called FABulous was used to design eFPGAs using 130 nm and 28 nm CMOS technology nodes, which were subsequently fabricated and verified through testing. The capability of an eFPGA to act as a front-end readout chip was tested using simulation of high energy particles passing through a silicon pixel sensor. A machine learning-based classifier, designed for reduction of sensor data at the source, was synthesized and configured onto the eFPGA. A successful proof-of-concept was demonstrated through reproduction of the expected algorithm result on the eFPGA with perfect accuracy. Further development of the eFPGA technology and its application to collider detector readout is discussed.
4/30/2024
🏷️
Investigating Resource-efficient Neutron/Gamma Classification ML Models Targeting eFPGAs
Jyothisraj Johnson, Billy Boxer, Tarun Prakash, Carl Grace, Peter Sorensen, Mani Tripathi
0
0
There has been considerable interest and resulting progress in implementing machine learning (ML) models in hardware over the last several years from the particle and nuclear physics communities. A big driver has been the release of the Python package, hls4ml, which has enabled porting models specified and trained using Python ML libraries to register transfer level (RTL) code. So far, the primary end targets have been commercial FPGAs or synthesized custom blocks on ASICs. However, recent developments in open-source embedded FPGA (eFPGA) frameworks now provide an alternate, more flexible pathway for implementing ML models in hardware. These customized eFPGA fabrics can be integrated as part of an overall chip design. In general, the decision between a fully custom, eFPGA, or commercial FPGA ML implementation will depend on the details of the end-use application. In this work, we explored the parameter space for eFPGA implementations of fully-connected neural network (fcNN) and boosted decision tree (BDT) models using the task of neutron/gamma classification with a specific focus on resource efficiency. We used data collected using an AmBe sealed source incident on Stilbene, which was optically coupled to an OnSemi J-series SiPM to generate training and test data for this study. We investigated relevant input features and the effects of bit-resolution and sampling rate as well as trade-offs in hyperparameters for both ML architectures while tracking total resource usage. The performance metric used to track model performance was the calculated neutron efficiency at a gamma leakage of 10$^{-3}$. The results of the study will be used to aid the specification of an eFPGA fabric, which will be integrated as part of a test chip.
4/24/2024

Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
Keon-Hee Park, Kyungwoo Song, Gyeong-Moon Park
0
0
Few-Shot Class Incremental Learning (FSCIL) is a task that requires a model to learn new classes incrementally without forgetting when only a few samples for each class are given. FSCIL encounters two significant challenges: catastrophic forgetting and overfitting, and these challenges have driven prior studies to primarily rely on shallow models, such as ResNet-18. Even though their limited capacity can mitigate both forgetting and overfitting issues, it leads to inadequate knowledge transfer during few-shot incremental sessions. In this paper, we argue that large models such as vision and language transformers pre-trained on large datasets can be excellent few-shot incremental learners. To this end, we propose a novel FSCIL framework called PriViLege, Pre-trained Vision and Language transformers with prompting functions and knowledge distillation. Our framework effectively addresses the challenges of catastrophic forgetting and overfitting in large models through new pre-trained knowledge tuning (PKT) and two losses: entropy-based divergence loss and semantic knowledge distillation loss. Experimental results show that the proposed PriViLege significantly outperforms the existing state-of-the-art methods with a large margin, e.g., +9.38% in CUB200, +20.58% in CIFAR-100, and +13.36% in miniImageNet. Our implementation code is available at https://github.com/KHU-AGI/PriViLege.
4/3/2024
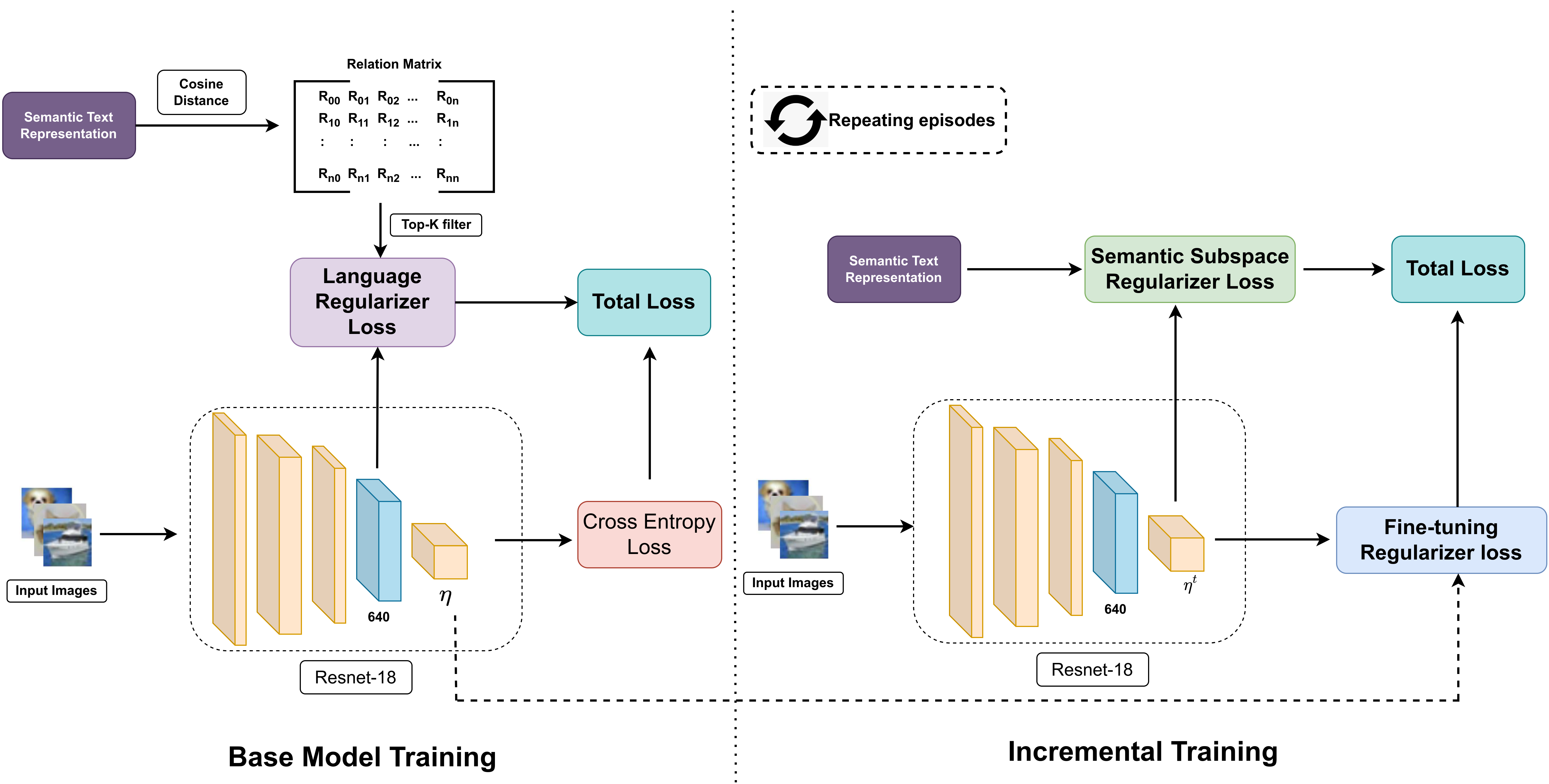
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
0
0
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
5/3/2024