PEMMA: Parameter-Efficient Multi-Modal Adaptation for Medical Image Segmentation
2404.13704
0
0
Abstract
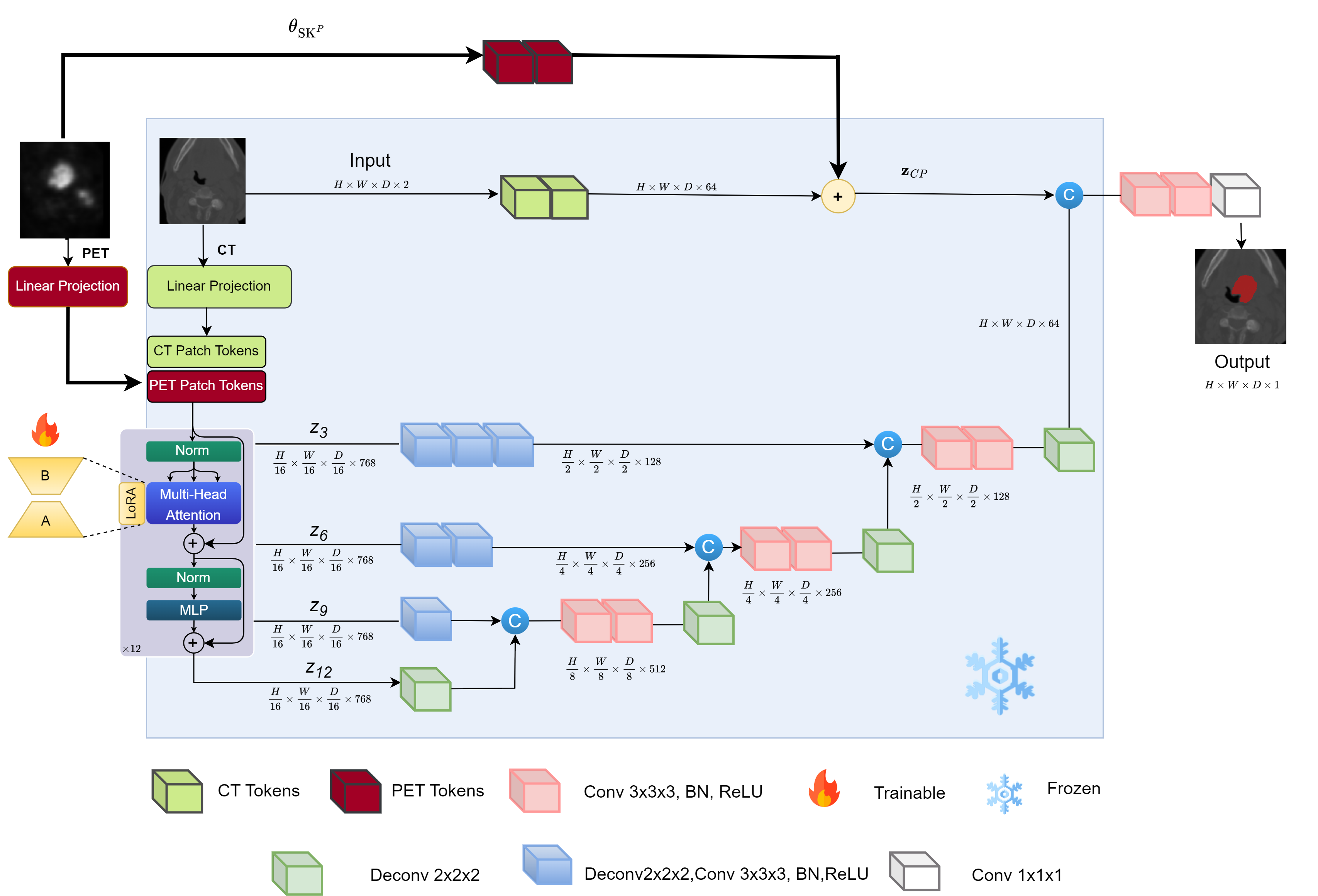
Imaging modalities such as Computed Tomography (CT) and Positron Emission Tomography (PET) are key in cancer detection, inspiring Deep Neural Networks (DNN) models that merge these scans for tumor segmentation. When both CT and PET scans are available, it is common to combine them as two channels of the input to the segmentation model. However, this method requires both scan types during training and inference, posing a challenge due to the limited availability of PET scans, thereby sometimes limiting the process to CT scans only. Hence, there is a need to develop a flexible DNN architecture that can be trained/updated using only CT scans but can effectively utilize PET scans when they become available. In this work, we propose a parameter-efficient multi-modal adaptation (PEMMA) framework for lightweight upgrading of a transformer-based segmentation model trained only on CT scans to also incorporate PET scans. The benefits of the proposed approach are two-fold. Firstly, we leverage the inherent modularity of the transformer architecture and perform low-rank adaptation (LoRA) of the attention weights to achieve parameter-efficient adaptation. Secondly, since the PEMMA framework attempts to minimize cross modal entanglement, it is possible to subsequently update the combined model using only one modality, without causing catastrophic forgetting of the other modality. Our proposed method achieves comparable results with the performance of early fusion techniques with just 8% of the trainable parameters, especially with a remarkable +28% improvement on the average dice score on PET scans when trained on a single modality.
Create account to get full access
Overview
- Proposes a parameter-efficient approach for adapting pre-trained models to medical image segmentation tasks across multiple modalities
- Introduces PEMMA (Parameter-Efficient Multi-Modal Adaptation), a method that leverages low-rank adaptation and cross-modal entanglement to enable efficient fine-tuning
- Demonstrates PEMMA's effectiveness on 3D medical image segmentation tasks, outperforming previous adaptation methods while using significantly fewer parameters
Plain English Explanation
The paper presents a new technique called PEMMA (Parameter-Efficient Multi-Modal Adaptation) that allows machine learning models to be efficiently adapted to perform medical image segmentation tasks across different types of medical scans, such as MRI and PET-CT.
The key idea behind PEMMA is to use a "low-rank" adaptation approach, which means only updating a small number of the model's parameters during the adaptation process. This is more efficient than fine-tuning the entire model, which can require a lot of computing power and training data.
PEMMA also incorporates "cross-modal entanglement", which helps the model learn connections between different types of medical scans. This allows the adapted model to perform well on a variety of medical imaging modalities, rather than being specialized for just one type.
The researchers demonstrate that PEMMA outperforms previous adaptation methods while using significantly fewer parameters. This makes it a promising approach for efficiently deploying machine learning models in real-world medical imaging applications, where data and computational resources may be limited.
Technical Explanation
The paper introduces PEMMA (Parameter-Efficient Multi-Modal Adaptation), a novel method for adapting pre-trained deep learning models to perform 3D medical image segmentation tasks across multiple imaging modalities. PEMMA leverages two key techniques:
-
Low-rank Adaptation: Instead of fine-tuning the entire model, PEMMA updates only a small number of the model's parameters during adaptation. This "low-rank" approach is more parameter-efficient than full fine-tuning, requiring fewer resources and less training data.
-
Cross-modal Entanglement: PEMMA incorporates a cross-modal entanglement module that helps the model learn connections between different imaging modalities, such as MRI and PET-CT. This allows the adapted model to perform well on a variety of medical imaging tasks, rather than being specialized for a single modality.
The researchers evaluate PEMMA on several 3D medical image segmentation benchmarks, including brain, cardiac, and abdominal tasks. They demonstrate that PEMMA outperforms previous adaptation methods, such as PEFoMED and Cross-Model Mutual Learning, while using significantly fewer parameters.
Critical Analysis
The paper provides a comprehensive evaluation of PEMMA, including comparisons to state-of-the-art adaptation methods on multiple medical imaging tasks. The results demonstrate the effectiveness of PEMMA's low-rank adaptation and cross-modal entanglement approach, which could be particularly beneficial in real-world medical imaging applications where data and computational resources are limited.
However, the paper does not fully address potential limitations or caveats of the proposed method. For example, it remains unclear how PEMMA would perform on tasks with substantial domain shift between the pre-trained model and the target medical imaging data, or how sensitive the method is to the choice of pre-trained model. Additionally, the paper does not discuss potential challenges in deploying PEMMA in clinical settings, such as the interpretability of the model's predictions or the regulatory requirements for medical AI systems.
Further research could explore the robustness and generalizability of PEMMA, as well as investigate ways to improve the method's transparency and clinical feasibility. Nonetheless, the paper presents a promising approach for efficient multi-modal adaptation in medical image analysis, which could have significant implications for the field.
Conclusion
The PEMMA (Parameter-Efficient Multi-Modal Adaptation) method proposed in this paper offers a novel and efficient solution for adapting pre-trained deep learning models to a variety of 3D medical image segmentation tasks. By leveraging low-rank adaptation and cross-modal entanglement, PEMMA can outperform previous adaptation techniques while using significantly fewer parameters.
This parameter-efficient approach has the potential to enable the widespread deployment of powerful machine learning models in real-world medical imaging applications, where data and computational resources may be limited. While the paper does not address all potential limitations, the promising results demonstrate the value of PEMMA as a step forward in the field of medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-modal Evidential Fusion Network for Trusted PET/CT Tumor Segmentation
Yuxuan Qi, Li Lin, Jiajun Wang, Jingya Zhang, Bin Zhang
0
0
Accurate segmentation of tumors in PET/CT images is important in computer-aided diagnosis and treatment of cancer. The key issue of such a segmentation problem lies in the effective integration of complementary information from PET and CT images. However, the quality of PET and CT images varies widely in clinical settings, which leads to uncertainty in the modality information extracted by networks. To take the uncertainty into account in multi-modal information fusion, this paper proposes a novel Multi-modal Evidential Fusion Network (MEFN) comprising a Cross-Modal Feature Learning (CFL) module and a Multi-modal Trusted Fusion (MTF) module. The CFL module reduces the domain gap upon modality conversion and highlights common tumor features, thereby alleviating the needs of the segmentation module to handle modality specificity. The MTF module utilizes mutual attention mechanisms and an uncertainty calibrator to fuse modality features based on modality uncertainty and then fuse the segmentation results under the guidance of Dempster-Shafer Theory. Besides, a new uncertainty perceptual loss is introduced to force the model focusing on uncertain features and hence improve its ability to extract trusted modality information. Extensive comparative experiments are conducted on two publicly available PET/CT datasets to evaluate the performance of our proposed method whose results demonstrate that our MEFN significantly outperforms state-of-the-art methods with improvements of 2.15% and 3.23% in DSC scores on the AutoPET dataset and the Hecktor dataset, respectively. More importantly, our model can provide radiologists with credible uncertainty of the segmentation results for their decision in accepting or rejecting the automatic segmentation results, which is particularly important for clinical applications. Our code will be available at https://github.com/QPaws/MEFN.
6/27/2024

PEM: Prototype-based Efficient MaskFormer for Image Segmentation
Niccol`o Cavagnero, Gabriele Rosi, Claudia Cuttano, Francesca Pistilli, Marco Ciccone, Giuseppe Averta, Fabio Cermelli
0
0
Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
5/7/2024

Deep Learning-Based Segmentation of Tumors in PET/CT Volumes: Benchmark of Different Architectures and Training Strategies
Monika G'orka, Daniel Jaworek, Marek Wodzinski
0
0
Cancer is one of the leading causes of death globally, and early diagnosis is crucial for patient survival. Deep learning algorithms have great potential for automatic cancer analysis. Artificial intelligence has achieved high performance in recognizing and segmenting single lesions. However, diagnosing multiple lesions remains a challenge. This study examines and compares various neural network architectures and training strategies for automatically segmentation of cancer lesions using PET/CT images from the head, neck, and whole body. The authors analyzed datasets from the AutoPET and HECKTOR challenges, exploring popular single-step segmentation architectures and presenting a two-step approach. The results indicate that the V-Net and nnU-Net models were the most effective for their respective datasets. The results for the HECKTOR dataset ranged from 0.75 to 0.76 for the aggregated Dice coefficient. Eliminating cancer-free cases from the AutoPET dataset was found to improve the performance of most models. In the case of AutoPET data, the average segmentation efficiency after training only on images containing cancer lesions increased from 0.55 to 0.66 for the classic Dice coefficient and from 0.65 to 0.73 for the aggregated Dice coefficient. The research demonstrates the potential of artificial intelligence in precise oncological diagnostics and may contribute to the development of more targeted and effective cancer assessment techniques.
4/16/2024
✨
A Multimodal Feature Distillation with CNN-Transformer Network for Brain Tumor Segmentation with Incomplete Modalities
Ming Kang, Fung Fung Ting, Raphael C. -W. Phan, Zongyuan Ge, Chee-Ming Ting
0
0
Existing brain tumor segmentation methods usually utilize multiple Magnetic Resonance Imaging (MRI) modalities in brain tumor images for segmentation, which can achieve better segmentation performance. However, in clinical applications, some modalities are missing due to resource constraints, leading to severe degradation in the performance of methods applying complete modality segmentation. In this paper, we propose a Multimodal feature distillation with Convolutional Neural Network (CNN)-Transformer hybrid network (MCTSeg) for accurate brain tumor segmentation with missing modalities. We first design a Multimodal Feature Distillation (MFD) module to distill feature-level multimodal knowledge into different unimodality to extract complete modality information. We further develop a Unimodal Feature Enhancement (UFE) module to model the relationship between global and local information semantically. Finally, we build a Cross-Modal Fusion (CMF) module to explicitly align the global correlations among different modalities even when some modalities are missing. Complementary features within and across different modalities are refined via the CNN-Transformer hybrid architectures in both the UFE and CMF modules, where local and global dependencies are both captured. Our ablation study demonstrates the importance of the proposed modules with CNN-Transformer networks and the convolutional blocks in Transformer for improving the performance of brain tumor segmentation with missing modalities. Extensive experiments on the BraTS2018 and BraTS2020 datasets show that the proposed MCTSeg framework outperforms the state-of-the-art methods in missing modalities cases. Our code is available at: https://github.com/mkang315/MCTSeg.
4/23/2024