PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
2401.02797
0
0
Abstract
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel method called PeFoMed (Parameter Efficient Fine-tuning on Multimodal Large Language Models for Medical Visual Question Answering) to improve the performance of large language models on medical visual question answering tasks.
- PeFoMed leverages parameter-efficient fine-tuning techniques to adapt multimodal large language models to the medical domain without significantly increasing the model size.
- The authors demonstrate the effectiveness of PeFoMed on the MedExpQA dataset, a benchmark for medical visual question answering.
Plain English Explanation
The paper describes a new technique called PeFoMed that helps large language models, which are powerful AI systems trained on vast amounts of text data, become better at answering questions about medical images and information.
Large language models are often very good at understanding and generating human-like text, but they can struggle when it comes to tasks that involve both text and images, like medical visual question answering. PeFoMed aims to address this by using a special fine-tuning process that allows the language model to adapt to the medical domain without dramatically increasing the size of the model.
The authors tested PeFoMed on the MedExpQA dataset, which is a benchmark for evaluating how well AI systems can answer questions about medical images and information. Their results show that PeFoMed can significantly improve the performance of large language models on this task, making them more useful for real-world medical applications.
Technical Explanation
The paper introduces PeFoMed, a parameter-efficient fine-tuning approach for adapting multimodal large language models to the medical domain for visual question answering tasks. The authors leverage techniques like AdapterNet and Mixture-of-Experts (MoE) to fine-tune the pre-trained models with minimal additional parameters.
Specifically, PeFoMed introduces task-specific adapter modules and MoE layers within the base multimodal model architecture. During fine-tuning, only the adapter modules and MoE layers are trained, while the main model parameters are frozen. This allows the model to specialize in the medical domain without significantly increasing the overall parameter count.
The authors evaluate PeFoMed on the MedExpQA dataset, a challenging benchmark for medical visual question answering. They compare PeFoMed to various fine-tuning baselines and demonstrate that it outperforms them while using fewer trainable parameters. The paper also provides ablation studies to analyze the contribution of different components of PeFoMed.
Critical Analysis
The paper provides a solid technical contribution by introducing PeFoMed, a parameter-efficient fine-tuning approach for adapting large multimodal language models to medical visual question answering tasks. The authors' use of techniques like AdapterNet and MoE is well-motivated and the experimental results on the MedExpQA dataset are promising.
However, the paper does not address potential limitations or caveats of the PeFoMed approach. For example, it would be helpful to understand how well PeFoMed generalizes to other medical visual tasks or datasets, or how it compares to more computationally expensive fine-tuning methods. Additionally, the paper does not discuss the potential biases or fairness implications of using large language models, even with domain-specific fine-tuning, for medical applications.
Further research could explore the robustness and generalizability of PeFoMed, as well as investigate ways to make the fine-tuning process more transparent and accountable. Nonetheless, the core ideas presented in this paper represent an important step towards developing more efficient and effective multimodal language models for medical applications.
Conclusion
The PeFoMed method proposed in this paper offers a promising approach for adapting large multimodal language models to the medical domain for visual question answering tasks. By leveraging parameter-efficient fine-tuning techniques, the authors demonstrate how to specialize these powerful models for medical applications without significantly increasing their size and complexity.
The strong performance of PeFoMed on the MedExpQA benchmark suggests that this method could be valuable for developing AI-powered medical tools and assistants that can effectively process and reason about both textual and visual medical information. As the field of multimodal language modeling continues to advance, techniques like PeFoMed will be crucial for making these models more accessible and useful in real-world healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
Hanguang Xiao, Feizhong Zhou, Xingyue Liu, Tianqi Liu, Zhipeng Li, Xin Liu, Xiaoxuan Huang
0
0
Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
5/15/2024
Towards a clinically accessible radiology foundation model: open-access and lightweight, with automated evaluation
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Yu Gu, Cliff Wong, Mu Wei, Tristan Naumann, Muhao Chen, Matthew P. Lungren, Serena Yeung-Levy, Curtis P. Langlotz, Sheng Wang, Hoifung Poon
0
0
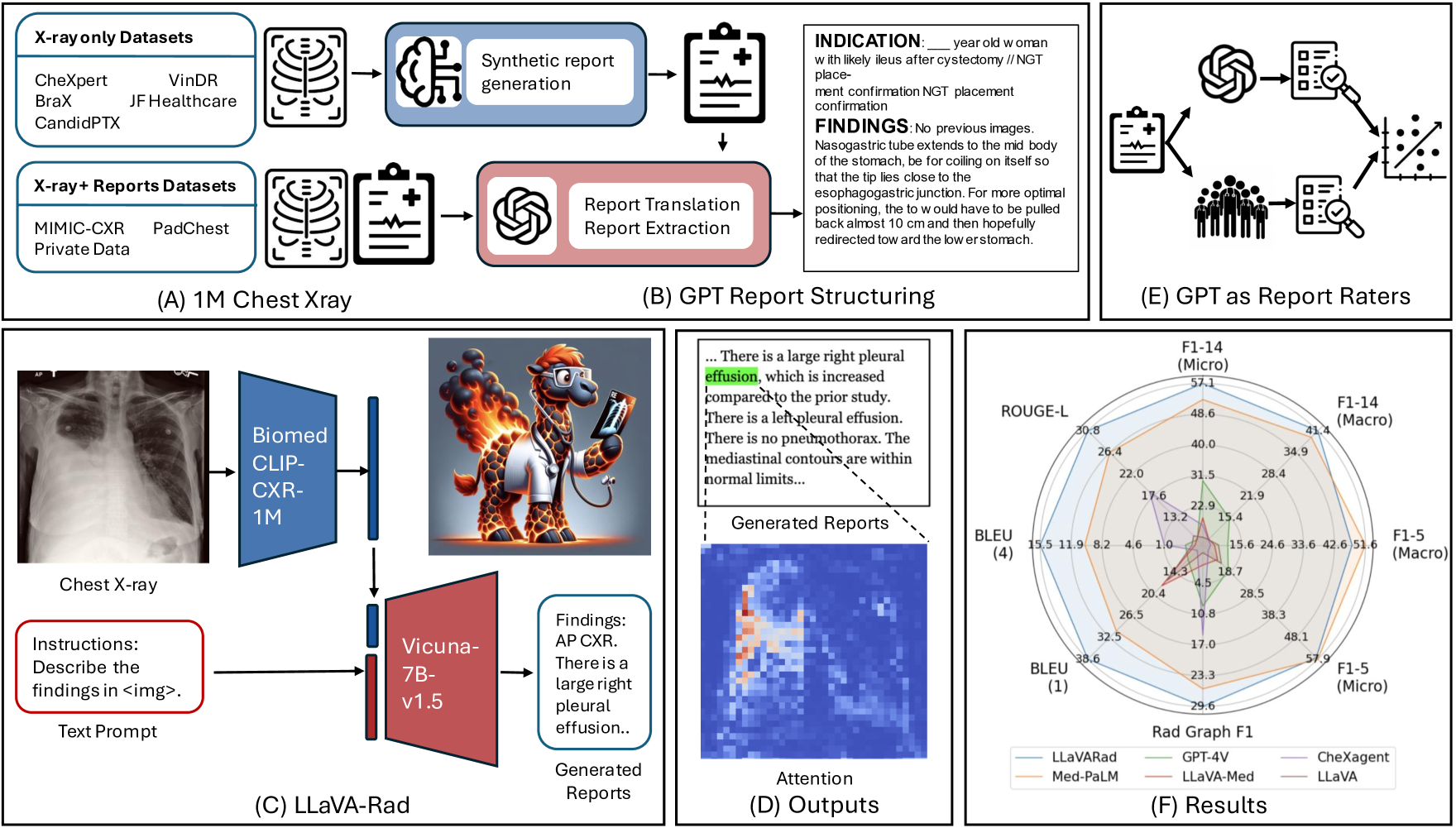
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world clinics. Frontier general-domain models such as GPT-4V still have significant performance gaps in multimodal biomedical applications. More importantly, less-acknowledged pragmatic issues, including accessibility, model cost, and tedious manual evaluation make it hard for clinicians to use state-of-the-art large models directly on private patient data. Here, we explore training open-source small multimodal models (SMMs) to bridge competency gaps for unmet clinical needs in radiology. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space, as exemplified by LLaVA-Med. For training, we assemble a large dataset of over 697 thousand radiology image-text pairs. For evaluation, we propose CheXprompt, a GPT-4-based metric for factuality evaluation, and demonstrate its parity with expert evaluation. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LlaVA-Rad (7B) model attains state-of-the-art results on standard radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). The inference of LlaVA-Rad is fast and can be performed on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
5/14/2024
🛸
WangLab at MEDIQA-M3G 2024: Multimodal Medical Answer Generation using Large Language Models
Ronald Xie, Steven Palayew, Augustin Toma, Gary Bader, Bo Wang
0
0
This paper outlines our submission to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task. We report results for two standalone solutions under the English category of the task, the first involving two consecutive API calls to the Claude 3 Opus API and the second involving training an image-disease label joint embedding in the style of CLIP for image classification. These two solutions scored 1st and 2nd place respectively on the competition leaderboard, substantially outperforming the next best solution. Additionally, we discuss insights gained from post-competition experiments. While the performance of these two solutions have significant room for improvement due to the difficulty of the shared task and the challenging nature of medical visual question answering in general, we identify the multi-stage LLM approach and the CLIP image classification approach as promising avenues for further investigation.
4/24/2024
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
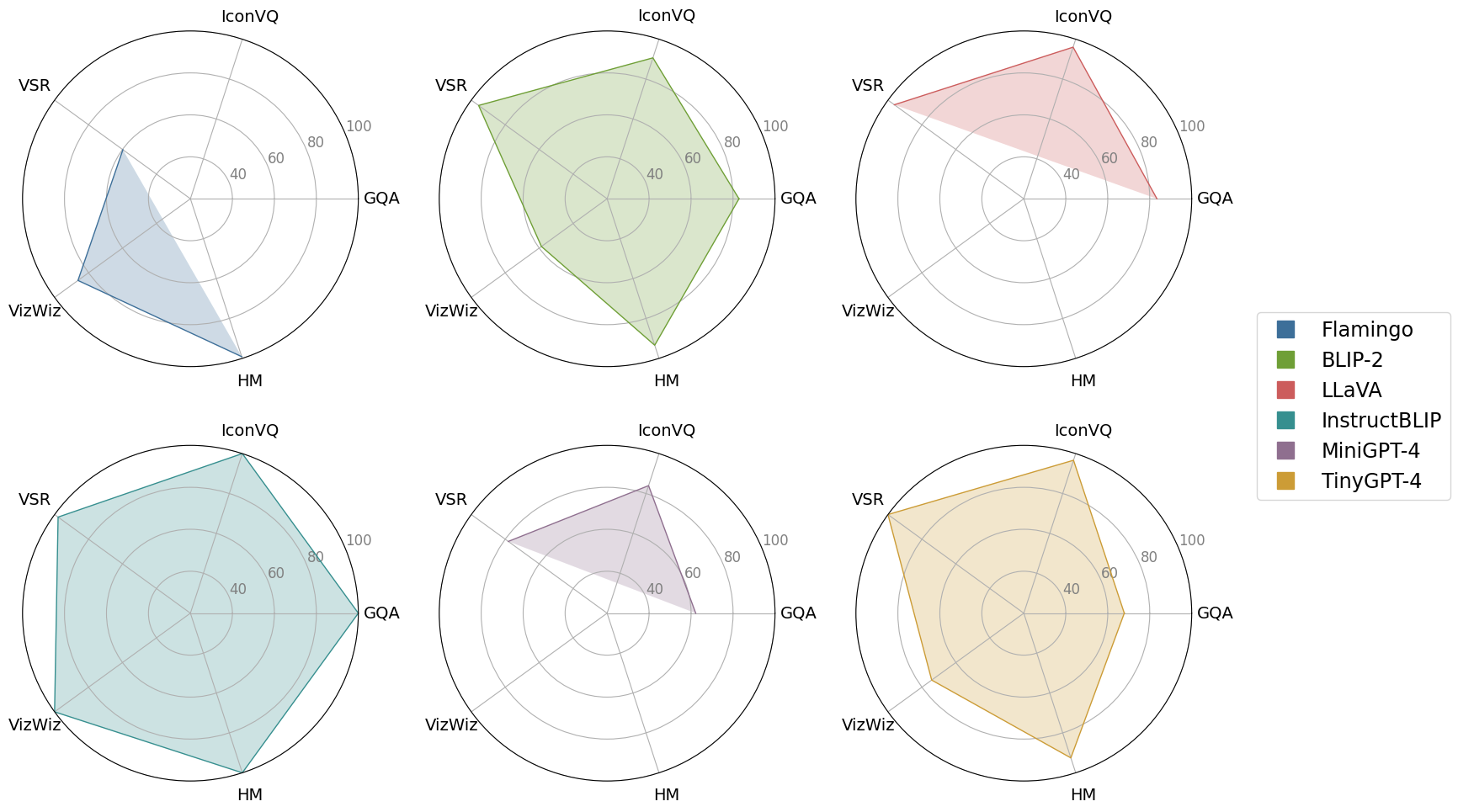
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
4/8/2024