On the performativity of SDG classifications in large bibliometric databases

0

Sign in to get full access
Overview
- This paper examines the performativity of Sustainable Development Goal (SDG) classifications in large bibliometric databases.
- It investigates how the assignment of SDG labels to research publications can shape and influence the research landscape.
- The study analyzes data from the Dimensions database to understand the implications of SDG classifications for research trends and priorities.
Plain English Explanation
The paper looks at how the way research publications are labeled with Sustainable Development Goal (SDG) categories can impact the research field itself. SDGs are a set of global goals defined by the United Nations to address challenges like poverty, inequality, and climate change.
When research papers are assigned SDG labels, it can change how the research is perceived and what gets prioritized. The authors used data from the Dimensions database, which tracks publications and their SDG classifications, to understand this effect. They wanted to see how the act of labeling research with SDG categories shapes the research that gets done and the overall direction of the field.
The core idea is that the labels we use to categorize research don't just reflect the content - they can actively influence it. By highlighting certain SDG-related topics, the labeling process can steer research towards those areas and away from others. This is an important consideration as policymakers and funders increasingly use SDG classifications to guide research agendas and funding decisions.
Technical Explanation
The paper investigates the performativity of Sustainable Development Goal (SDG) classifications in large bibliometric databases like Dimensions. Performativity refers to how the act of categorization can shape and influence the phenomenon being categorized.
The authors analyzed SDG classifications applied to research publications in the Dimensions database to understand how this labeling process impacts research priorities and trends. They examined factors like the growth of SDG-related publications over time, the distribution of SDG labels across different research areas, and the citation patterns of SDG-labeled papers.
The results suggest that the SDG classification system can have a significant performative effect, steering research towards certain SDG-aligned topics and potentially neglecting other important areas. The authors found evidence of "self-fulfilling prophecies", where the act of labeling a paper with a particular SDG label increases its visibility and citation, further reinforcing that SDG focus.
The paper highlights the need to critically examine how classification schemas like the SDGs are deployed in large-scale research databases. The performative impacts of such taxonomies can have important implications for research priorities, funding allocation, and the overall direction of scientific progress in addressing global challenges.
Critical Analysis
The paper provides a nuanced and thoughtful analysis of the performative effects of SDG classifications in bibliometric data. The authors acknowledge the potential value of the SDG framework in guiding research towards pressing global issues. However, they also caution that the way these classifications are implemented can have unintended consequences that merit further scrutiny.
One limitation noted in the paper is the reliance on a single database, Dimensions, which may not be fully representative of global research output. Expanding the analysis to include other major databases could strengthen the conclusions. Additionally, the authors suggest that the specific algorithm used to assign SDG labels in Dimensions may be a factor in the observed performative effects, warranting further investigation.
While the paper does not make strong normative claims, it raises important questions about the politics of research classification and the need for reflexivity in the use of such taxonomic systems. The findings highlight the risk of "self-reinforcing loops" where the labeling process itself shapes the research landscape, potentially overlooking valuable work that does not fit neatly into predefined SDG categories.
Readers may wish to consider how similar performative dynamics could arise in other contexts, such as the use of AI models for text-based summarization or predicting sustainable development goals. Approaches to auditing large language models and mitigating label bias may offer relevant insights for understanding and addressing performative effects in research classification systems.
Conclusion
This paper offers a thought-provoking examination of the performative aspects of Sustainable Development Goal (SDG) classifications in large bibliometric databases. The authors demonstrate how the act of labeling research publications with SDG categories can shape the research landscape, potentially reinforcing certain priorities while obscuring others.
The findings highlight the need for careful consideration of the sociopolitical implications of research classification systems, especially as they become increasingly integral to funding decisions, policy priorities, and the overall direction of scientific progress. By critically examining these performative effects, the paper encourages readers to be more mindful of how the tools we use to organize and understand research can themselves transform the very phenomena they aim to capture.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the performativity of SDG classifications in large bibliometric databases
Matteo Ottaviani, Stephan Stahlschmidt
Large bibliometric databases, such as Web of Science, Scopus, and OpenAlex, facilitate bibliometric analyses, but are performative, affecting the visibility of scientific outputs and the impact measurement of participating entities. Recently, these databases have taken up the UN's Sustainable Development Goals (SDGs) in their respective classifications, which have been criticised for their diverging nature. This work proposes using the feature of large language models (LLMs) to learn about the data bias injected by diverse SDG classifications into bibliometric data by exploring five SDGs. We build a LLM that is fine-tuned in parallel by the diverse SDG classifications inscribed into the databases' SDG classifications. Our results show high sensitivity in model architecture, classified publications, fine-tuning process, and natural language generation. The wide arbitrariness at different levels raises concerns about using LLM in research practice.
Read more5/7/2024

0
Surveying Attitudinal Alignment Between Large Language Models Vs. Humans Towards 17 Sustainable Development Goals
Qingyang Wu, Ying Xu, Tingsong Xiao, Yunze Xiao, Yitong Li, Tianyang Wang, Yichi Zhang, Shanghai Zhong, Yuwei Zhang, Wei Lu, Yifan Yang
Large Language Models (LLMs) have emerged as potent tools for advancing the United Nations' Sustainable Development Goals (SDGs). However, the attitudinal disparities between LLMs and humans towards these goals can pose significant challenges. This study conducts a comprehensive review and analysis of the existing literature on the attitudes of LLMs towards the 17 SDGs, emphasizing the comparison between their attitudes and support for each goal and those of humans. We examine the potential disparities, primarily focusing on aspects such as understanding and emotions, cultural and regional differences, task objective variations, and factors considered in the decision-making process. These disparities arise from the underrepresentation and imbalance in LLM training data, historical biases, quality issues, lack of contextual understanding, and skewed ethical values reflected. The study also investigates the risks and harms that may arise from neglecting the attitudes of LLMs towards the SDGs, including the exacerbation of social inequalities, racial discrimination, environmental destruction, and resource wastage. To address these challenges, we propose strategies and recommendations to guide and regulate the application of LLMs, ensuring their alignment with the principles and goals of the SDGs, and therefore creating a more just, inclusive, and sustainable future.
Read more4/23/2024
0
Predicting Sustainable Development Goals Using Course Descriptions -- from LLMs to Conventional Foundation Models
Lev Kharlashkin, Melany Macias, Leo Huovinen, Mika Hamalainen
We present our work on predicting United Nations sustainable development goals (SDG) for university courses. We use an LLM named PaLM 2 to generate training data given a noisy human-authored course description input as input. We use this data to train several different smaller language models to predict SDGs for university courses. This work contributes to better university level adaptation of SDGs. The best performing model in our experiments was BART with an F1-score of 0.786.
Read more4/24/2024
0
Efficacy of Large Language Models in Systematic Reviews
Aaditya Shah, Shridhar Mehendale, Siddha Kanthi
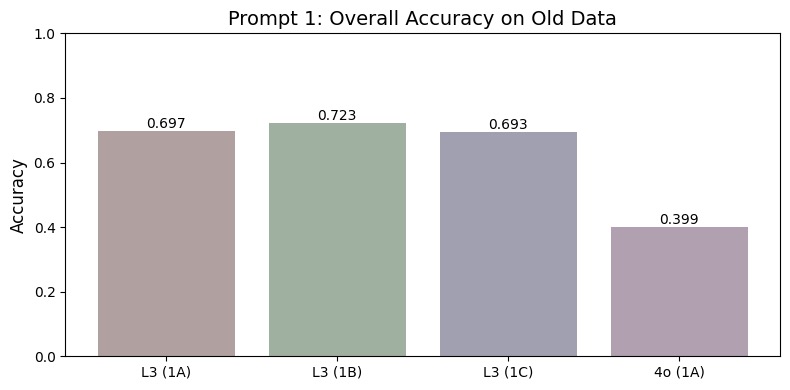
This study investigates the effectiveness of Large Language Models (LLMs) in interpreting existing literature through a systematic review of the relationship between Environmental, Social, and Governance (ESG) factors and financial performance. The primary objective is to assess how LLMs can replicate a systematic review on a corpus of ESG-focused papers. We compiled and hand-coded a database of 88 relevant papers published from March 2020 to May 2024. Additionally, we used a set of 238 papers from a previous systematic review of ESG literature from January 2015 to February 2020. We evaluated two current state-of-the-art LLMs, Meta AI's Llama 3 8B and OpenAI's GPT-4o, on the accuracy of their interpretations relative to human-made classifications on both sets of papers. We then compared these results to a Custom GPT and a fine-tuned GPT-4o Mini model using the corpus of 238 papers as training data. The fine-tuned GPT-4o Mini model outperformed the base LLMs by 28.3% on average in overall accuracy on prompt 1. At the same time, the Custom GPT showed a 3.0% and 15.7% improvement on average in overall accuracy on prompts 2 and 3, respectively. Our findings reveal promising results for investors and agencies to leverage LLMs to summarize complex evidence related to ESG investing, thereby enabling quicker decision-making and a more efficient market.
Read more8/12/2024