Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
2404.05970
0
0
Abstract
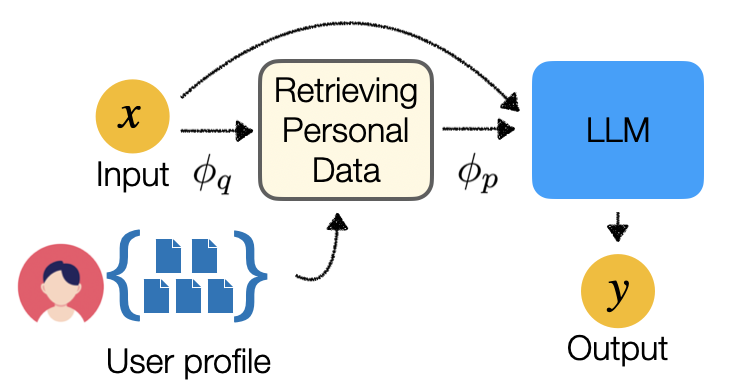
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores techniques to personalize large language models (LLMs) by augmenting them with retrieval-based methods.
- The researchers investigate different optimization approaches to improve the personalization of LLMs, focusing on ranking optimization and retrieval-augmented generation.
- The proposed methods aim to enhance the performance of LLMs in various text generation tasks while accounting for individual preferences and contexts.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models are typically trained on general data and may not always capture the unique preferences and needs of individual users. This paper introduces techniques to personalize LLMs by combining them with retrieval-based methods.
The researchers explore different optimization approaches to improve the personalization of LLMs. One approach is ranking optimization, which aims to ensure that the model's output is relevant and tailored to the user's preferences. Another approach is retrieval-augmented generation, where the model combines its own knowledge with relevant information retrieved from a database to generate more personalized and contextual text.
By incorporating these personalization techniques, the researchers hope to enhance the performance of LLMs in various text generation tasks, such as [content creation, [question answering, and dialogue. This could lead to more engaging and useful interactions with LLMs, as they would be better able to understand and cater to individual user needs.
Technical Explanation
The paper presents several optimization methods to personalize large language models (LLMs) through retrieval augmentation. The key elements of the research are as follows:
Ranking Optimization: The researchers explore techniques to optimize the ranking of the retrieved information, ensuring that the most relevant and personalized content is prioritized in the model's output. This involves developing novel ranking loss functions and training approaches to align the model's preferences with the user's needs.
Retrieval-Augmented Generation: The researchers investigate ways to combine the model's own knowledge with relevant information retrieved from a database or knowledge base. This allows the LLM to generate more contextual and personalized text, drawing on external sources to supplement its capabilities.
To evaluate the proposed methods, the researchers conduct experiments on various text generation tasks, such as content creation, question answering, and dialogue. They assess the performance of the personalized LLMs against baseline models and explore the impact of different optimization approaches on the quality and relevance of the generated text.
Critical Analysis
The paper presents a compelling approach to personalizing large language models, but it also acknowledges several caveats and limitations that warrant further investigation.
One key challenge is ensuring the reliability and trustworthiness of the personalized LLMs. While the proposed methods aim to enhance the relevance and tailoring of the model's output, there are still questions about the model's ability to accurately assess and represent the user's preferences. Additional research is needed to understand the potential biases and uncertainties introduced by the personalization process.
Furthermore, the paper does not fully address the scalability and deployment challenges of implementing these personalization techniques in real-world scenarios. Integrating retrieval-based methods with LLMs at scale could introduce technical and computational complexities that require further exploration.
Overall, the research presented in this paper represents an important step towards more personalized and user-centric language models. However, continued efforts are needed to address the remaining challenges and unlock the full potential of these personalization techniques.
Conclusion
This paper explores innovative approaches to personalizing large language models (LLMs) through retrieval augmentation. By incorporating techniques like ranking optimization and retrieval-augmented generation, the researchers aim to enhance the performance of LLMs in various text generation tasks while accounting for individual user preferences and contexts.
The proposed methods have the potential to lead to more engaging and useful interactions with LLMs, as the models would be better able to understand and cater to the unique needs of each user. However, the research also highlights important considerations around the reliability, trustworthiness, and scalability of these personalization techniques, which will require further investigation and refinement.
As the field of AI continues to advance, the development of personalized and user-centric language models will become increasingly crucial. The insights and approaches presented in this paper contribute to this important area of research and offer a promising path forward for enhancing the capabilities and relevance of large language models.
Related Papers
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
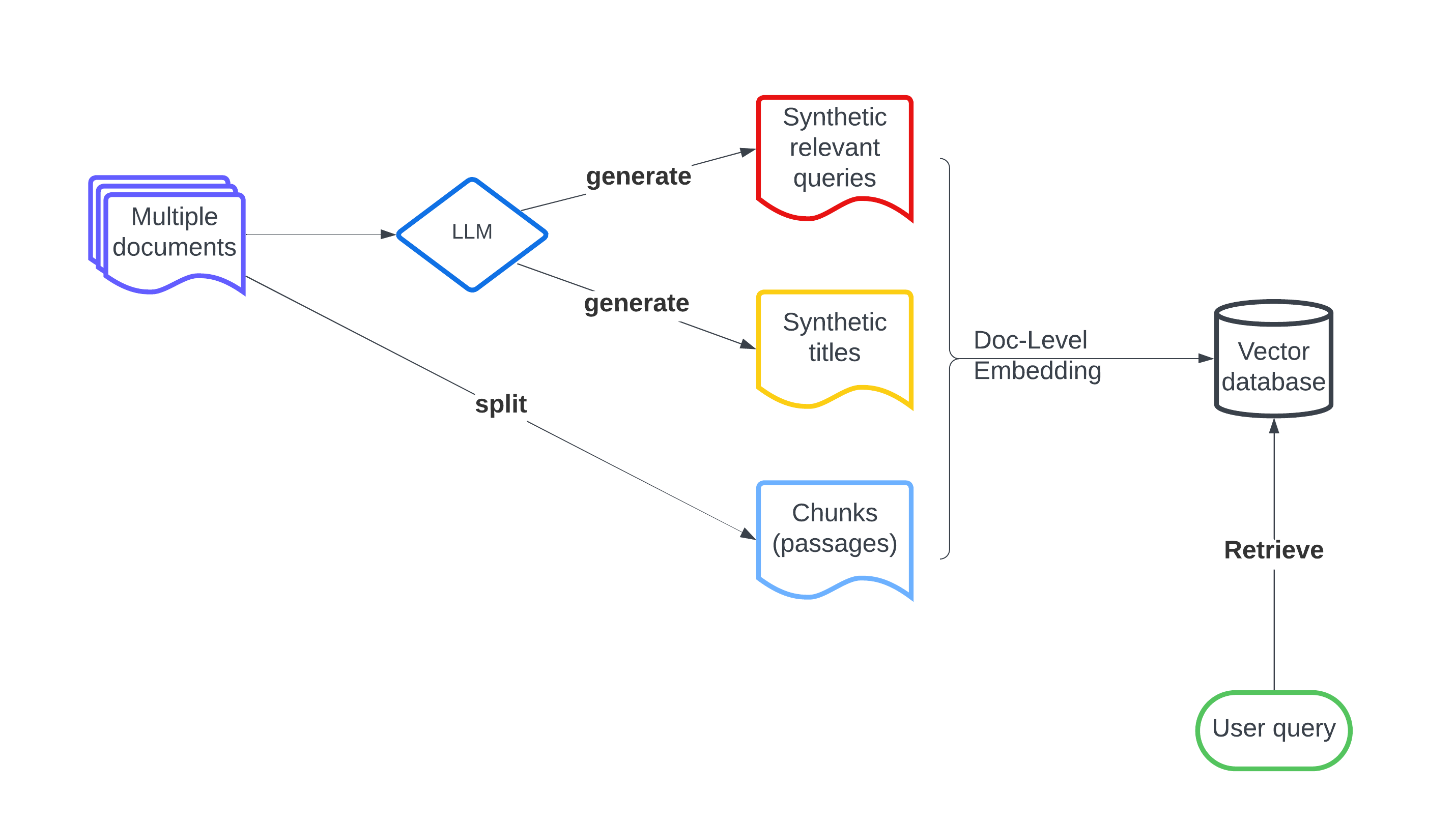
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
🛸
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
0
0
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
5/8/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024
🛸
Modeling Uncertainty and Using Post-fusion as Fallback Improves Retrieval Augmented Generation with LLMs
Ye Liu, Semih Yavuz, Rui Meng, Meghana Moorthy, Shafiq Joty, Caiming Xiong, Yingbo Zhou
0
0
The integration of retrieved passages and large language models (LLMs), such as ChatGPTs, has significantly contributed to improving open-domain question answering. However, there is still a lack of exploration regarding the optimal approach for incorporating retrieved passages into the answer generation process. This paper aims to fill this gap by investigating different methods of combining retrieved passages with LLMs to enhance answer generation. We begin by examining the limitations of a commonly-used concatenation approach. Surprisingly, this approach often results in generating unknown outputs, even when the correct document is among the top-k retrieved passages. To address this issue, we explore four alternative strategies for integrating the retrieved passages with the LLMs. These strategies include two single-round methods that utilize chain-of-thought reasoning and two multi-round strategies that incorporate feedback loops. Through comprehensive analyses and experiments, we provide insightful observations on how to effectively leverage retrieved passages to enhance the answer generation capability of LLMs.
4/9/2024