PersonaGym: Evaluating Persona Agents and LLMs

0

Sign in to get full access
Overview
- This paper presents PersonaGym, a framework for evaluating persona agents and large language models (LLMs) on their ability to engage in persona-based conversations.
- The researchers design a set of evaluation tasks that assess an agent's understanding of persona and its ability to maintain a consistent persona throughout a conversation.
- They evaluate several persona agent models and LLMs on these tasks, providing insights into the current capabilities and limitations of these systems.
Plain English Explanation
The paper describes a new way to test how well AI chatbots and language models can understand and maintain a consistent personality or "persona" when conversing with people. The researchers created a set of evaluation tasks, called PersonaGym, that measure an AI's ability to understand and stick to a specific persona throughout a conversation.
For example, one task might involve an AI playing the role of a friendly, outgoing person, while another task might have the AI play a more reserved, intellectual persona. The researchers then evaluate how well different AI models, including some of the latest large language models (LLMs) like ChatGPT, perform on these tasks.
The goal is to better understand the current limitations of these AI systems when it comes to maintaining a consistent personality, which is an important aspect of having natural, engaging conversations. The findings from this research can help inform the development of more advanced persona-based AI agents in the future.
Technical Explanation
The paper introduces the PersonaGym evaluation framework, which consists of a set of tasks designed to assess an AI agent's understanding and maintenance of persona throughout a conversation. These tasks include:
- Normative Evaluation: Measuring an agent's ability to understand and respond appropriately to persona-based prompts.
- Persona Consistency: Evaluating an agent's ability to maintain a consistent persona across multiple turns of a conversation.
- Persona Flexibility: Assessing an agent's ability to switch between different personas within a conversation.
The researchers evaluate several persona agent models and LLMs on these tasks, including Persona-LLM, PerLLM, and ChatGPT. Their findings provide insights into the current capabilities and limitations of these systems when it comes to persona-based conversations.
Critical Analysis
The paper highlights some important limitations of current persona-based AI agents and LLMs. For example, the researchers found that even state-of-the-art models like ChatGPT struggle to maintain a consistent persona throughout a conversation, and have difficulty switching between personas as needed.
Additionally, the paper raises concerns about the potential biases and lack of nuance in how these models represent and understand personas, which could lead to stereotypical or oversimplified portrayals of different personalities.
Further research is needed to address these limitations and develop more sophisticated persona-based AI systems that can engage in truly natural and engaging conversations. Potential areas for improvement include better persona modeling, more advanced context understanding, and more robust methods for maintaining persona consistency.
Conclusion
The PersonaGym evaluation framework provides a valuable tool for assessing the current capabilities and limitations of persona-based AI agents and LLMs. The findings from this research highlight the need for continued advancements in persona modeling and persona-based conversation abilities, which will be crucial for the development of more natural and engaging AI assistants in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PersonaGym: Evaluating Persona Agents and LLMs
Vinay Samuel, Henry Peng Zou, Yue Zhou, Shreyas Chaudhari, Ashwin Kalyan, Tanmay Rajpurohit, Ameet Deshpande, Karthik Narasimhan, Vishvak Murahari
Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model. Importantly, we find that increased model size and complexity do not necessarily imply enhanced persona agent capabilities thereby highlighting the pressing need for algorithmic and architectural invention towards faithful and performant persona agents.
Read more7/30/2024

0
Building Better AI Agents: A Provocation on the Utilisation of Persona in LLM-based Conversational Agents
Guangzhi Sun, Xiao Zhan, Jose Such
The incorporation of Large Language Models (LLMs) such as the GPT series into diverse sectors including healthcare, education, and finance marks a significant evolution in the field of artificial intelligence (AI). The increasing demand for personalised applications motivated the design of conversational agents (CAs) to possess distinct personas. This paper commences by examining the rationale and implications of imbuing CAs with unique personas, smoothly transitioning into a broader discussion of the personalisation and anthropomorphism of CAs based on LLMs in the LLM era. We delve into the specific applications where the implementation of a persona is not just beneficial but critical for LLM-based CAs. The paper underscores the necessity of a nuanced approach to persona integration, highlighting the potential challenges and ethical dilemmas that may arise. Attention is directed towards the importance of maintaining persona consistency, establishing robust evaluation mechanisms, and ensuring that the persona attributes are effectively complemented by domain-specific knowledge.
Read more7/18/2024
💬
0
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
Read more4/3/2024
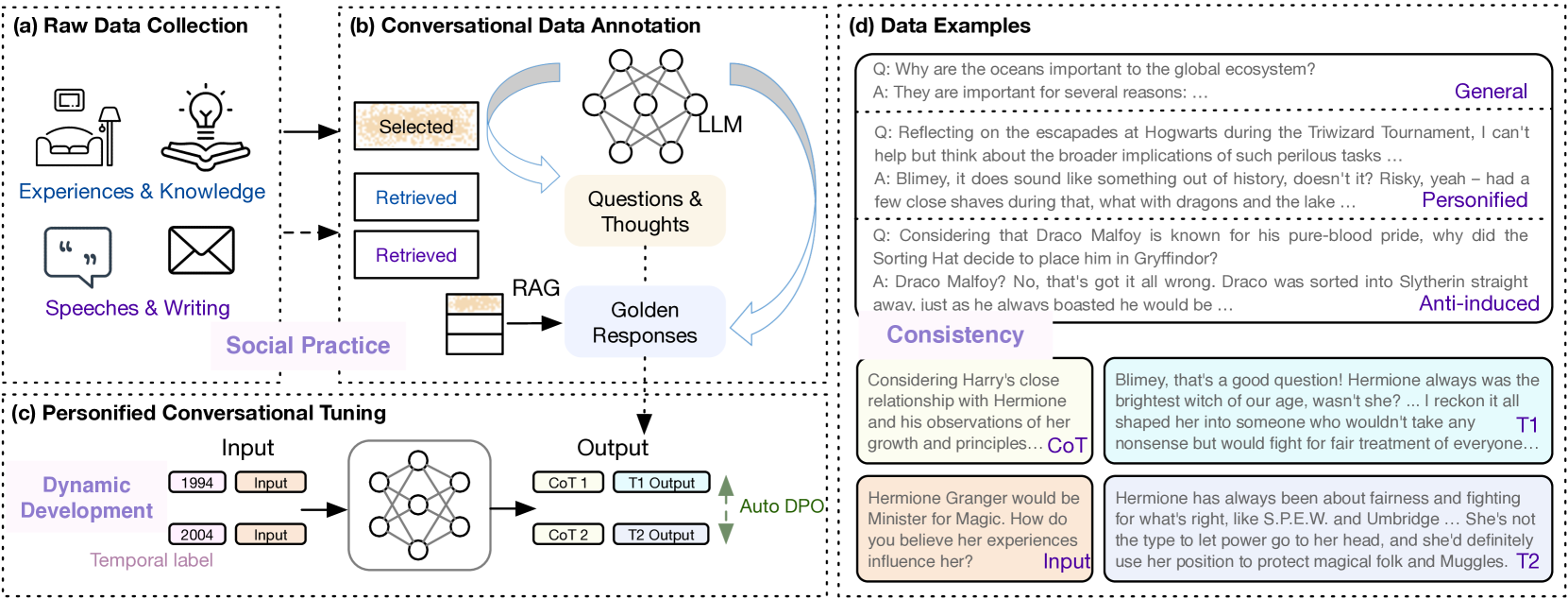
0
PersLLM: A Personified Training Approach for Large Language Models
Zheni Zeng, Jiayi Chen, Huimin Chen, Yukun Yan, Yuxuan Chen, Zhenghao Liu, Zhiyuan Liu, Maosong Sun
Large language models exhibit aspects of human-level intelligence that catalyze their application as human-like agents in domains such as social simulations, human-machine interactions, and collaborative multi-agent systems. However, the absence of distinct personalities, such as displaying ingratiating behaviors, inconsistent opinions, and uniform response patterns, diminish LLMs utility in practical applications. Addressing this, the development of personality traits in LLMs emerges as a crucial area of research to unlock their latent potential. Existing methods to personify LLMs generally involve strategies like employing stylized training data for instruction tuning or using prompt engineering to simulate different personalities. These methods only capture superficial linguistic styles instead of the core of personalities and are therefore not stable. In this study, we propose PersLLM, integrating psychology-grounded principles of personality: social practice, consistency, and dynamic development, into a comprehensive training methodology. We incorporate personality traits directly into the model parameters, enhancing the model's resistance to induction, promoting consistency, and supporting the dynamic evolution of personality. Single-agent evaluation validates our method's superiority, as it produces responses more aligned with reference personalities compared to other approaches. Case studies for multi-agent communication highlight its benefits in enhancing opinion consistency within individual agents and fostering collaborative creativity among multiple agents in dialogue contexts, potentially benefiting human simulation and multi-agent cooperation. Additionally, human-agent interaction evaluations indicate that our personified models significantly enhance interactive experiences, underscoring the practical implications of our research.
Read more7/29/2024