Personalized Federated Learning via Sequential Layer Expansion in Representation Learning
2404.17799
0
0

Abstract
Federated learning ensures the privacy of clients by conducting distributed training on individual client devices and sharing only the model weights with a central server. However, in real-world scenarios, the heterogeneity of data among clients necessitates appropriate personalization methods. In this paper, we aim to address this heterogeneity using a form of parameter decoupling known as representation learning. Representation learning divides deep learning models into 'base' and 'head' components. The base component, capturing common features across all clients, is shared with the server, while the head component, capturing unique features specific to individual clients, remains local. We propose a new representation learning-based approach that suggests decoupling the entire deep learning model into more densely divided parts with the application of suitable scheduling methods, which can benefit not only data heterogeneity but also class heterogeneity. In this paper, we compare and analyze two layer scheduling approaches, namely forward (textit{Vanilla}) and backward (textit{Anti}), in the context of data and class heterogeneity among clients. Our experimental results show that the proposed algorithm, when compared to existing personalized federated learning algorithms, achieves increased accuracy, especially under challenging conditions, while reducing computation costs.
Create account to get full access
Overview
- This paper proposes a novel personalized federated learning (FL) framework called Personalized Federated Learning via Sequential Layer Expansion (PFLSE)
- The key idea is to expand the model layers sequentially during the training process to capture personalized representations for each client, rather than using a single global model
- This approach aims to address the inherent heterogeneity in federated learning, where clients may have varying data distributions and modeling preferences
Plain English Explanation
In a typical federated learning (FL) setup, a central server coordinates the training of a single global model using data from multiple clients, without the clients sharing their raw data. However, the clients may have very different data and preferences, which can make it challenging to find a single model that works well for everyone.
The PFLSE approach tries to address this by allowing the model to grow and adapt to each individual client during the training process. Instead of a single global model, the framework starts with a small base model and then adds new layers sequentially for each client. This helps capture the unique characteristics and preferences of each client, resulting in a more personalized model.
The key innovation is that the new layers are added in a way that preserves the shared knowledge from the base model, while also allowing for personalization. This helps to strike a balance between maintaining common representations and adapting to individual clients' needs. The personalization approach used here is different from simply fine-tuning a global model, as it allows for more flexibility and control over the personalization process.
Overall, this personalized FL framework aims to improve the performance and effectiveness of federated learning, especially in scenarios where the clients have diverse data and requirements.
Technical Explanation
The PFLSE framework consists of three main components:
- Base Model: A small base model is initialized and shared across all clients.
- Personalization Layers: For each client, a set of personalization layers is added on top of the base model. These layers are trained using the client's local data, while the base model is kept frozen.
- Sequential Layer Expansion: During the training process, the personalization layers are expanded sequentially, with new layers being added in each communication round. This allows the model to gradually adapt to the client's data and preferences.
The key technical contributions of this work include:
-
Personalization Mechanism: The personalization layers are designed to capture client-specific representations while preserving the shared knowledge in the base model. This is achieved through a contrastive learning approach that encourages the personalization layers to extract client-specific features while aligning with the base model's representations.
-
Sequential Layer Expansion: The sequential layer expansion strategy allows the model to gradually increase in complexity and adapt to each client's data distribution. This is in contrast to approaches that use a fixed model architecture for all clients.
-
Theoretical Analysis: The authors provide a theoretical analysis to characterize the convergence and personalization properties of the PFLSE framework, showing its advantages over existing personalized FL methods.
The proposed framework is evaluated on several real-world datasets and demonstrates improved performance compared to various personalized FL baselines, especially in scenarios with high client heterogeneity.
Critical Analysis
The PFLSE framework addresses an important challenge in federated learning, namely the inherent heterogeneity among clients. By allowing for personalization through sequential layer expansion, the approach aims to strike a balance between maintaining shared representations and adapting to individual client needs.
One potential limitation of the framework is the computational and communication cost associated with the sequential layer expansion. As new layers are added for each client, the model size and the amount of information that needs to be exchanged between the server and clients may increase. The authors acknowledge this and suggest that further research on addressing the computational and communication efficiency of personalized FL is needed.
Additionally, the paper does not explicitly address the privacy concerns that may arise from the personalization process. As the model is adapted to each client's data, there is a risk of potential data leakage or privacy breaches, which should be carefully considered and mitigated.
Overall, the PFLSE framework represents an interesting and promising approach to personalized federated learning. The authors have demonstrated its effectiveness on various datasets, but further research is needed to address the potential challenges and limitations, particularly around computational efficiency and privacy preservation.
Conclusion
The Personalized Federated Learning via Sequential Layer Expansion (PFLSE) framework proposed in this paper offers a novel solution to the problem of client heterogeneity in federated learning. By allowing the model to grow and adapt to each client through the sequential addition of personalization layers, the approach aims to capture the unique characteristics and preferences of individual clients while preserving the shared knowledge in the base model.
The key contributions of this work include the personalization mechanism, the sequential layer expansion strategy, and the theoretical analysis of the framework's convergence and personalization properties. The experimental results demonstrate the effectiveness of PFLSE in improving model performance, especially in scenarios with high client heterogeneity.
While the framework shows promise, further research is needed to address potential challenges around computational efficiency and privacy preservation. Nonetheless, the PFLSE approach represents an important step forward in the field of personalized federated learning, with potential applications in a wide range of domains where client diversity is a significant challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
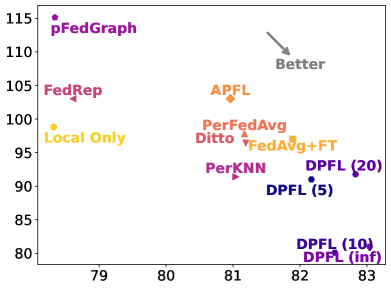
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024

Personalized federated learning based on feature fusion
Wolong Xing, Zhenkui Shi, Hongyan Peng, Xiantao Hu, Xianxian Li
0
0
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.
6/26/2024

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024

Federated Face Forgery Detection Learning with Personalized Representation
Decheng Liu, Zhan Dang, Chunlei Peng, Nannan Wang, Ruimin Hu, Xinbo Gao
0
0
Deep generator technology can produce high-quality fake videos that are indistinguishable, posing a serious social threat. Traditional forgery detection methods directly centralized training on data and lacked consideration of information sharing in non-public video data scenarios and data privacy. Naturally, the federated learning strategy can be applied for privacy protection, which aggregates model parameters of clients but not original data. However, simple federated learning can't achieve satisfactory performance because of poor generalization capabilities for the real hybrid-domain forgery dataset. To solve the problem, the paper proposes a novel federated face forgery detection learning with personalized representation. The designed Personalized Forgery Representation Learning aims to learn the personalized representation of each client to improve the detection performance of individual client models. In addition, a personalized federated learning training strategy is utilized to update the parameters of the distributed detection model. Here collaborative training is conducted on multiple distributed client devices, and shared representations of these client models are uploaded to the server side for aggregation. Experiments on several public face forgery detection datasets demonstrate the superior performance of the proposed algorithm compared with state-of-the-art methods. The code is available at emph{https://github.com/GANG370/PFR-Forgery.}
6/18/2024