Personalized LLM Response Generation with Parameterized Memory Injection
2404.03565
0
0

Abstract
Large Language Models (LLMs) have exhibited remarkable proficiency in comprehending and generating natural language. On the other hand, personalized LLM response generation holds the potential to offer substantial benefits for individuals in critical areas such as medical. Existing research has explored memory-augmented methods to prompt the LLM with pre-stored user-specific knowledge for personalized response generation in terms of new queries. We contend that such paradigm is unable to perceive fine-granularity information. In this study, we propose a novel textbf{M}emory-textbf{i}njected approach using parameter-efficient fine-tuning (PEFT) and along with a Bayesian Optimisation searching strategy to achieve textbf{L}LM textbf{P}ersonalization(textbf{MiLP}).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel approach to generating personalized responses from large language models (LLMs) using parameterized memory injection.
- The key idea is to incorporate personalized information into the LLM's memory during inference, allowing the model to generate more tailored and relevant responses for each user.
- The approach involves encoding user preferences, context, and other relevant information into a memory module that is then selectively injected into the LLM's hidden states during the response generation process.
- Experiments on various conversational tasks demonstrate the effectiveness of this method in improving the relevance and personalization of LLM outputs.
Plain English Explanation
The paper introduces a way to make AI language models more personalized and relevant to individual users. Large language models (LLMs) are powerful AI systems that can generate human-like text, but they typically produce generic, one-size-fits-all responses.
The researchers' key insight is to give the LLM access to personalized information about the user, such as their preferences, context, and background. They do this by creating a "memory module" that encodes this user-specific data. During the response generation process, the LLM can selectively pull in relevant information from this memory module, allowing it to produce more tailored and relevant outputs.
Imagine you're chatting with an AI assistant. Normally, the assistant would give you a generic, impersonal response. But with this new approach, the assistant can access information about your interests, location, and past conversations to craft a response that is much more personalized and meaningful to you.
By injecting this personalized memory into the LLM, the researchers were able to demonstrate significant improvements in the relevance and quality of the generated responses across various conversational tasks. This represents an important step towards building AI assistants that can engage in more natural, contextual, and personalized dialogue.
Technical Explanation
The core of the proposed approach is a "Parameterized Memory Injection" (PMI) module that is integrated with the LLM. This module takes in user-specific information, such as their preferences, context, and background, and encodes it into a personalized memory representation.
During response generation, the PMI module selectively injects this personalized memory into the LLM's hidden states at various layers. This allows the LLM to incorporate the user-specific information into its language modeling, resulting in more tailored and relevant outputs.
The researchers experiment with different methods for encoding the personalized memory, including attention-based and gating mechanisms. They also explore how the extent and location of the memory injection affects the model's performance.
Experiments are conducted on several conversational tasks, such as persona-based dialogue, empathetic response generation, and task-oriented dialogue. The results demonstrate that the PMI-enhanced LLM significantly outperforms standard LLM baselines in terms of relevance, coherence, and user satisfaction.
The paper also discusses potential limitations and future research directions, such as the challenge of scaling the personalized memory to large numbers of users and exploring the interpretability of the injection process.
Critical Analysis
The proposed PMI approach represents an important step towards building more personalized and contextual language models. By incorporating user-specific information into the response generation process, the model is able to produce outputs that are more relevant and tailored to individual users.
One key strength of the approach is its flexibility - the personalized memory can encode a wide range of user-specific data, from preferences and interests to task-specific context. This allows the model to be applied across diverse conversational scenarios.
However, the paper does acknowledge some limitations. Scaling the personalized memory to large user populations may pose challenges, as the memory module would need to be efficiently stored and accessed. Additionally, the interpretability of the memory injection process could be an area for further investigation, to better understand how the user-specific information is being leveraged by the model.
It would also be interesting to see how this approach generalizes to other language modeling tasks beyond conversational scenarios, such as content generation or text summarization. Exploring the potential biases or fairness implications of the personalized memory injection would also be a valuable direction for future research.
Overall, this work represents an important contribution to the field of personalized language modeling, demonstrating the value of integrating user-specific information into large language models. As AI systems become more ubiquitous in our daily lives, approaches like this will be crucial for building AI assistants that can engage in more natural, contextual, and meaningful interactions.
Conclusion
The paper presents a novel approach to generating personalized responses from large language models by incorporating user-specific information through a Parameterized Memory Injection module. This allows the LLM to produce more relevant and tailored outputs, as demonstrated across various conversational tasks.
The key insight of the work is the ability to selectively inject personalized memory into the LLM's hidden states, enabling the model to leverage user-specific context and preferences during response generation. This represents an important step towards building AI assistants that can engage in more natural, contextual, and personalized dialogue.
While the paper identifies some limitations around scaling and interpretability, the proposed PMI approach shows great promise for advancing the state of the art in personalized language modeling. As AI systems become more integrated into our daily lives, this type of personalization will be crucial for building AI assistants that can truly understand and respond to the unique needs of each individual user.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLM-based Medical Assistant Personalization with Short- and Long-Term Memory Coordination
Kai Zhang, Yangyang Kang, Fubang Zhao, Xiaozhong Liu
0
0
Large Language Models (LLMs), such as GPT3.5, have exhibited remarkable proficiency in comprehending and generating natural language. On the other hand, medical assistants hold the potential to offer substantial benefits for individuals. However, the exploration of LLM-based personalized medical assistant remains relatively scarce. Typically, patients converse differently based on their background and preferences which necessitates the task of enhancing user-oriented medical assistant. While one can fully train an LLM for this objective, the resource consumption is unaffordable. Prior research has explored memory-based methods to enhance the response with aware of previous mistakes for new queries during a dialogue session. We contend that a mere memory module is inadequate and fully training an LLM can be excessively costly. In this study, we propose a novel computational bionic memory mechanism, equipped with a parameter-efficient fine-tuning (PEFT) schema, to personalize medical assistants.
4/5/2024

MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Ali Modarressi, Abdullatif Koksal, Ayyoob Imani, Mohsen Fayyaz, Hinrich Schutze
0
0
While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $unicode{x2013}$ though non-parametric $unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
4/19/2024
PMG : Personalized Multimodal Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
0
0
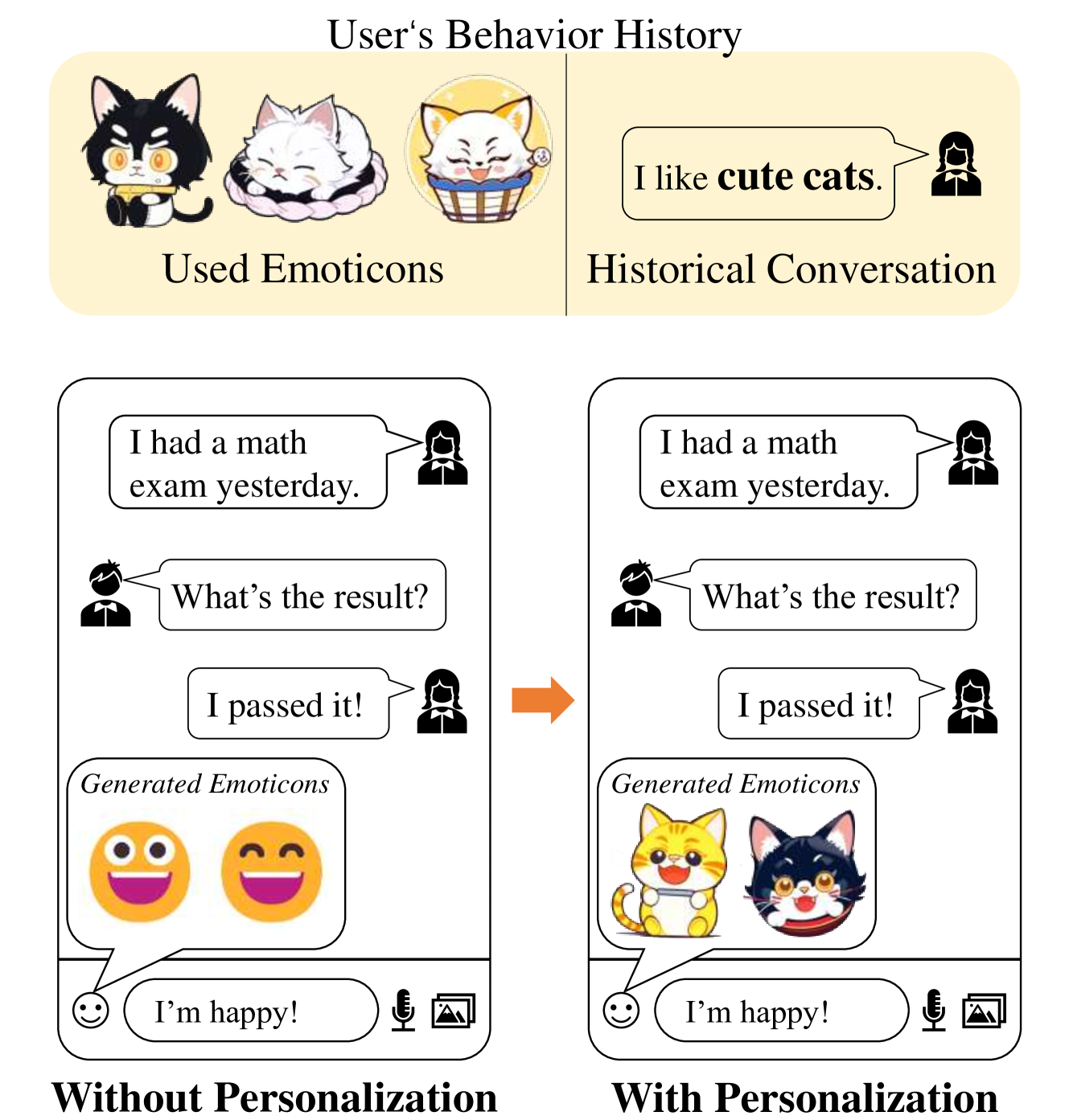
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
4/16/2024
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
0
0
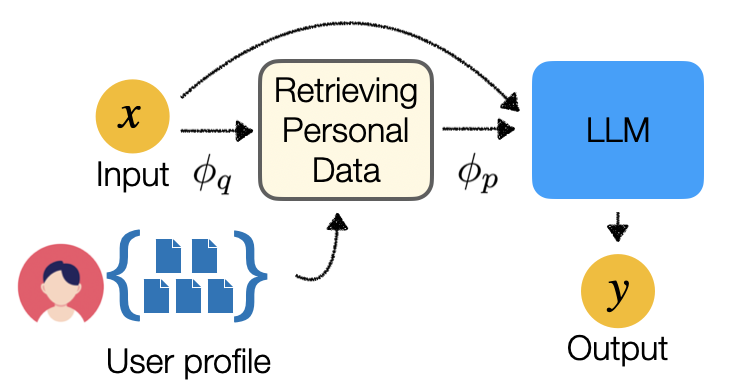
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
4/10/2024