PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency

0

Sign in to get full access
Introduction
The provided text describes a framework called Prompt-Enhanced Two-stage Text-to-SQL (PET-SQL) that aims to improve the performance of large language models (LLMs) on the task of converting natural language questions into SQL queries.
The key points are:
-
Current approaches on Text-to-SQL focus on representing schema information in prompts, but lack attention to formatting of cell values in tables, which is important for handling conditional statements.
-
The canonical schema-linking module is a separate plugin that produces limited information and is not well-suited for coding LLMs.
-
Existing post-refinement techniques like self-debugging and self-consistency have limitations and do not significantly improve performance.
-
PET-SQL addresses these challenges through: a. A reference-enhanced prompt that includes schema information, sampled cell values, and instructions to minimize SQL execution time. b. A two-stage approach that first generates a preliminary SQL (PreSQL) using few-shot demonstrations, then uses the PreSQL to link the schema and simplify the prompt for the final SQL generation. c. Cross-consistency voting across different LLMs, rather than self-consistency of a single LLM.
The proposed PET-SQL framework achieves state-of-the-art performance of 87.6% execution accuracy on the Spider benchmark, outperforming previous methods.
Related Work
The text discusses the advancements in language models and their impact on the Text2SQL task, which involves translating natural language (NL) questions into structured SQL queries. Early approaches focused on pattern matching and relation-aware self-attention mechanisms to learn representations of questions and schemas. The advent of pre-trained language models and the fine-tuning paradigm subsequently influenced these methods, leading to the use of standard sequence-to-sequence models with transformer architectures for end-to-end NL-to-SQL translation.
The development of large language models (LLMs) has further transformed this field. LLM-based in-context learning methods leverage the semantic understanding, reasoning capabilities, and zero-shot learning ability of LLMs to push the boundaries of performance on Text2SQL evaluation benchmarks. Techniques like decomposing the task into multiple components, in-context learning, and incorporating advanced reasoning methods have been explored to enhance the capabilities of LLMs and improve their performance on Text2SQL tasks.
Methodology
The provided text discusses the objective of LLM-based Text2SQL, which is to translate a natural language question Q on a database D into an executable SQL query s. The likelihood of an LLM M generating a SQL query s can be formally defined as the conditional probability distribution shown in Equation (1).
The text then summarizes the key specifications of the PET-SQL framework, which are:
- An elaborated prompt that uses customized instructions, basic database information, and samples from stored tables.
- Instructing the LLM to generate PreSQL, where demonstrations selected from pools using a question similarity-based strategy are prefixed to the prompt as few-shot in-context.
- Finding question-related tables (schema linking) based on the PreSQL and prompt to yield FinSQL by the linked schema.
- Ensuring consistency in the predicted results across multiple LLMs.
The provided text discusses prompting and SQL query generation for large language models (LLMs). Key points:
-
The use of prompting styles or templates significantly impacts LLMs' performance in generating SQL queries. The paper recommends using a combination of Code Representation and OpenAI Demonstration formats, termed "reference-enhanced representation" (RE).
-
RE includes three modifications: optimization rule (to minimize SQL execution time while ensuring correctness), cell value references (to provide sample data to help LLMs understand the database), and foreign key declarations (to help LLMs understand table relationships).
-
To further improve SQL generation, the paper proposes a "question skeleton-based PreSQL generation" approach. This retrieves similar question-SQL pairs from a training set, uses them as few-shot demonstrations, and prompts the LLM to generate a preliminary SQL query (PreSQL).
-
The paper then describes a "schema linking and FinSQL generation" step. This identifies the relevant tables and columns mentioned in the PreSQL, simplifies the prompt, and feeds it back to the LLM to generate the final SQL query (FinSQL).
-
Lastly, the paper discusses a "cross consistency" approach, which uses multiple LLMs to generate FinSQL queries and applies majority voting on the executed results to improve reliability, with an option to use fine-grained voting based on PreSQL complexity.
Overall, the paper proposes a multi-stage approach to leverage prompting and few-shot learning to improve the SQL generation capabilities of LLMs.
Experiments
The provided text describes the experimental setup and evaluation of the PET-SQL framework for the Text2SQL task on the Spider benchmark.
Key points:
- The Spider benchmark contains 8659 training instances, 1034 development instances, and 2147 test instances across 200 databases.
- Execution accuracy (EX) is used as the evaluation metric, which measures the proportion of questions where the predicted and ground-truth SQL queries produce identical execution results.
- Five large language models (LLMs) are evaluated, including coding-specific (CodeLlama-34B, SQLCoder-34B) and generic (InternLM-70B, SenseChat, GPT4-0613) models.
- PET-SQL achieves the highest EX among non-learning-based methods on the Spider test set, surpassing the second-ranked DAIL-SQL by about 1%.
- Comparisons show PET-SQL consistently outperforms DAIL-SQL across different LLMs on the test set.
- The proposed prompt (RE_p) demonstrates superior performance compared to other prompts, with improvements of 1-7% on the development and test sets.
- Ablation studies reveal the importance of the cell value references component in the prompt.
- Schema linking using GPT4 leads to significant simplification of the input prompts and improves performance across the evaluated LLMs.
- Cross-consistency voting among the five LLMs further boosts performance, outperforming self-consistency.
Conclusion
The PET-SQL framework aims to improve performance on Text2SQL tasks. It enhances the prompt and leverages consistency across large language models (LLMs). The approach achieves an 87.6% execution accuracy on the Spider leaderboard. The framework also includes a PreSQL-based schema linking method to simplify the prompt information, improving the efficiency and accuracy of LLMs in generating SQL queries. Overall, the PET-SQL framework demonstrates promising results and suggests avenues for further advancements in Text2SQL tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Zhishuai Li, Xiang Wang, Jingjing Zhao, Sun Yang, Guoqing Du, Xiaoru Hu, Bin Zhang, Yuxiao Ye, Ziyue Li, Rui Zhao, Hangyu Mao
Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
Read more6/4/2024
0
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
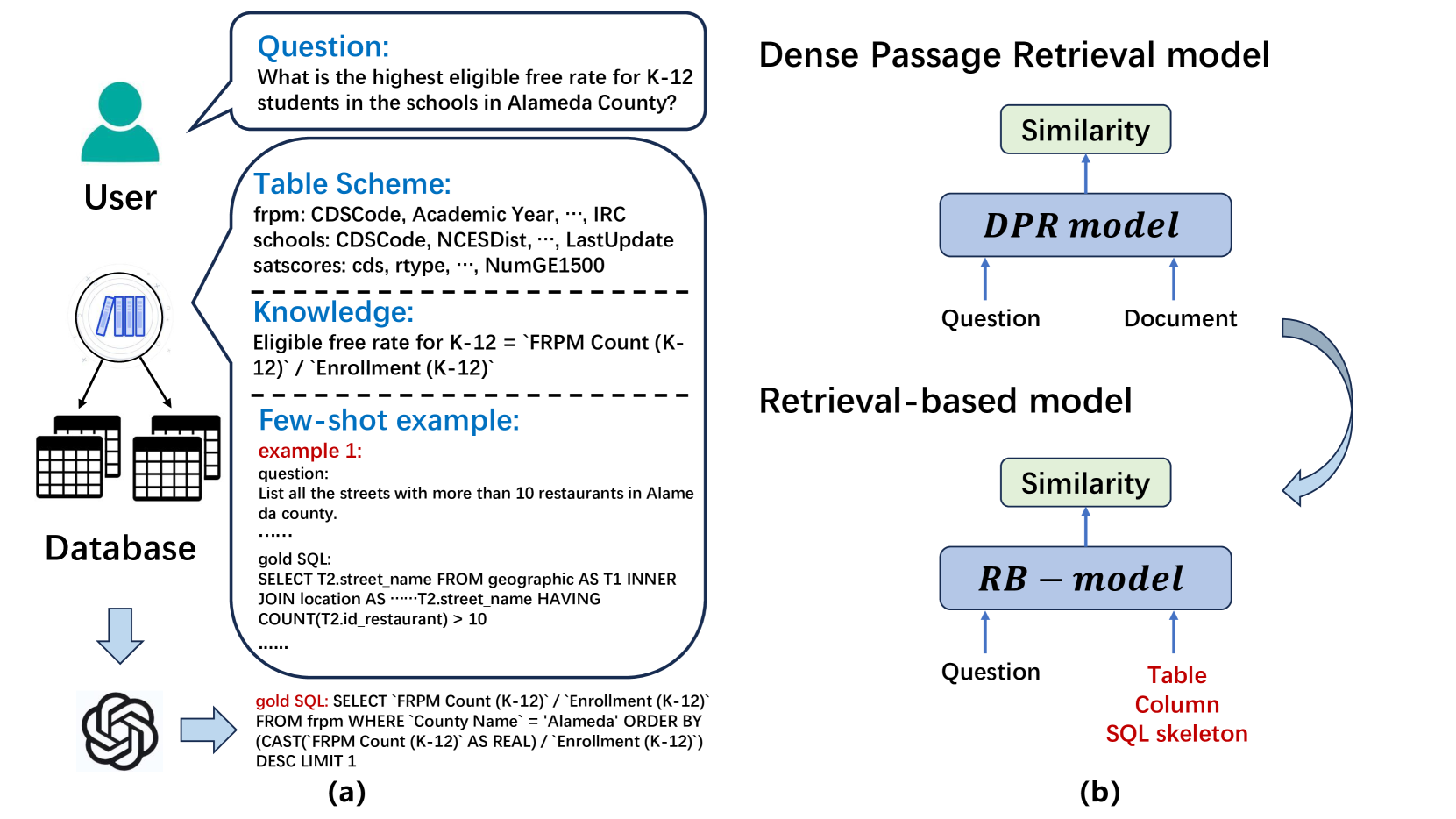
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024
0
MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
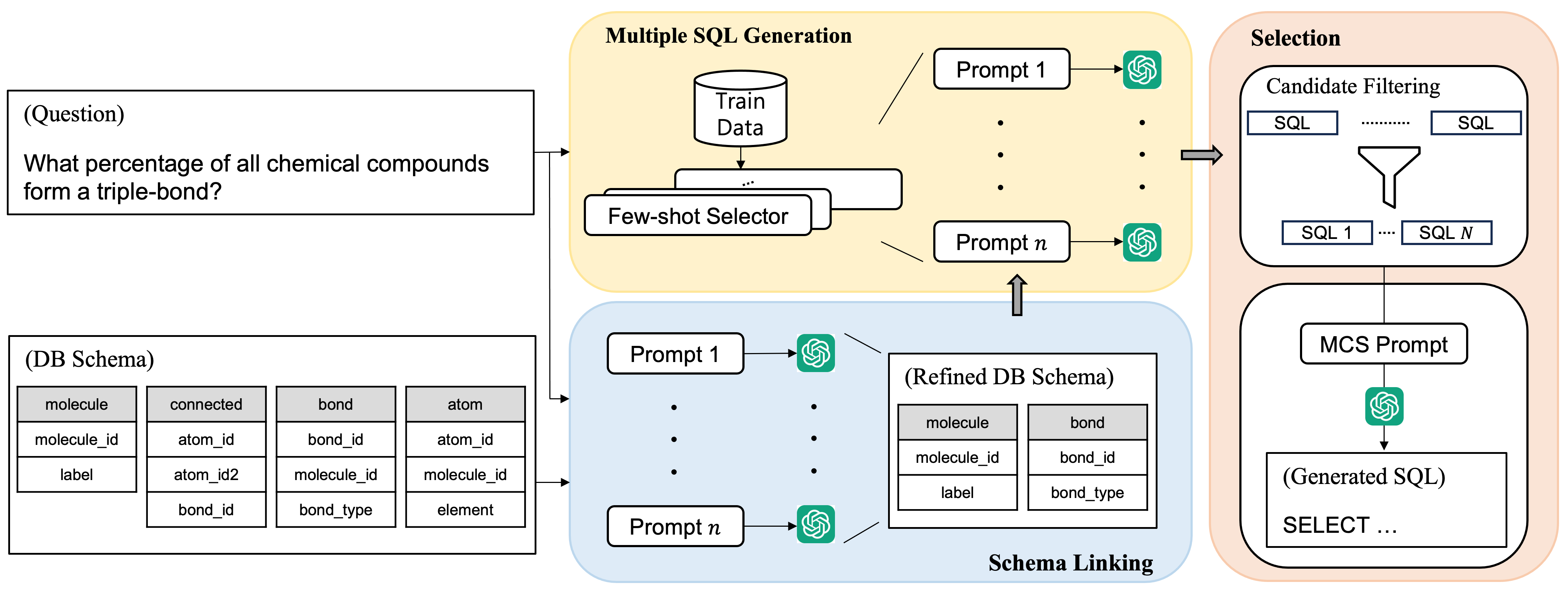
Dongjun Lee, Choongwon Park, Jaehyuk Kim, Heesoo Park
Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5% and 89.6%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.
Read more5/14/2024
0
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, Min Yang
Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as textbf{Variable-length Open DB Schema}, textbf{Target Column Truncation}, and textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54% to 41.04% and Code Llama-7B from 14.54% to 48.24% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35%) on the BIRD-Dev dataset.
Read more5/14/2024