Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
2401.09407
0
1

Abstract
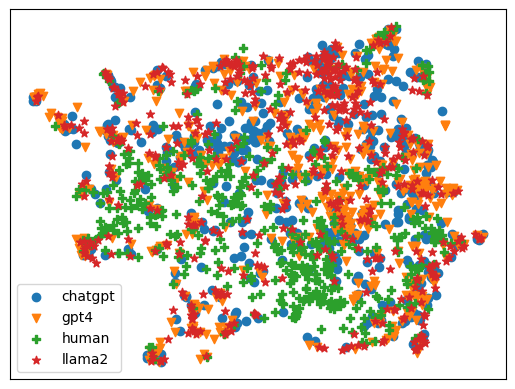
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a generalized strategy for detecting whether a given text was generated by a human or by a machine learning model, such as a large language model.
- The authors propose using the semantics of large language models to capture the unique patterns and nuances of human-generated text, which can then be used to distinguish it from machine-generated text.
- The paper explores various approaches to this problem, including auditing large language models, AI-generated text boundary detection, and distinguishing machine-generated from user-generated content.
Plain English Explanation
The paper presents a new way to tell whether a piece of text was written by a human or generated by a machine learning model, such as a large language model. The key idea is to use the unique patterns and nuances of human language, as captured by the semantics of large language models, to distinguish human-written text from machine-generated text.
For example, humans often use language in subtle and complex ways, with implicit meanings, humorous turns of phrase, and personal touches that can be hard for machines to replicate. By analyzing the semantics of a piece of text, the authors argue that it's possible to detect these human-like patterns and use them to determine whether the text was written by a person or generated by a computer program.
The paper explores different approaches to this problem, building on previous research in areas like auditing large language models, detecting the boundaries of AI-generated text, and distinguishing machine-generated from user-generated content. The goal is to develop a more general and effective way to identify whether a given piece of text was written by a human or produced by a machine.
Technical Explanation
The paper proposes a generalized strategy for detecting whether a given text was generated by a human or a machine learning model, such as a large language model. The authors leverage the semantics of large language models to capture the unique patterns and nuances of human-generated text, which can then be used to distinguish it from machine-generated text.
The authors explore various approaches to this problem, building on previous research in related areas. For example, they discuss techniques for auditing large language models to understand their biases and limitations, as well as methods for detecting the boundaries of AI-generated text and distinguishing machine-generated from user-generated content.
The key insight of the paper is that human language use often involves subtle patterns, implicit meanings, and personal touches that can be difficult for machines to replicate. By analyzing the semantics of a piece of text, the authors argue that it's possible to identify these human-like characteristics and use them to determine whether the text was written by a person or generated by a computer program.
The paper presents a generalized framework for this task, which can be applied to a variety of text-based applications and domains. The authors discuss the potential implications of their approach, including its use in combating the spread of misinformation and humanizing machine-generated content.
Critical Analysis
The paper presents a promising approach for detecting whether a given text was generated by a human or a machine learning model. The authors make a strong case for the importance of this problem and the potential impact of their proposed solution.
One potential limitation of the approach is the reliance on the semantics of large language models, which may themselves be biased or have limitations. The authors acknowledge this issue and discuss the need for further research into auditing large language models to understand their biases and flaws.
Additionally, the paper does not provide a comprehensive evaluation of the proposed strategy across different domains and datasets. It would be valuable to see how the approach performs in a wider range of scenarios, including different genres of text, languages, and types of machine-generated content.
Another area for further exploration is the potential for adversarial attacks, where machine-generated text is intentionally designed to evade detection. The authors mention this challenge but do not delve deeply into potential countermeasures or approaches to make the detection system more robust.
Overall, the paper presents a compelling and well-researched approach to a important problem in the field of natural language processing. The authors have made a significant contribution, but there is still room for further refinement and exploration of the proposed strategy.
Conclusion
This paper introduces a generalized strategy for distinguishing human-generated text from machine-generated text, leveraging the semantics of large language models to capture the unique patterns and nuances of human language use. The authors explore various approaches to this problem, building on previous research in related areas, and discuss the potential implications of their work, including its use in combating misinformation and humanizing machine-generated content.
While the proposed strategy shows promise, the authors acknowledge the need for further research to address potential limitations, such as the biases and flaws of large language models, and to evaluate the approach across a wider range of scenarios. Nevertheless, this paper represents an important step forward in the ongoing effort to develop more effective and reliable methods for detecting textual authenticity in the age of advanced language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
New!Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text
Muhammad Farid Adilazuarda
0
0
Significant progress has been made on text generation by pre-trained language models (PLMs), yet distinguishing between human and machine-generated text poses an escalating challenge. This paper offers an in-depth evaluation of three distinct methods used to address this task: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning. These approaches are rigorously tested on a wide range of machine-generated texts, providing a benchmark of their competence in distinguishing between human-authored and machine-authored linguistic constructs. The results reveal considerable differences in performance across methods, thus emphasizing the continued need for advancement in this crucial area of NLP. This study offers valuable insights and paves the way for future research aimed at creating robust and highly discriminative models.
5/16/2024
🎲
A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F. Wong, Lidia S. Chao
0
0
The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, statistics-based detectors, neural-base detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, real-world data issues and the lack of effective evaluation framework. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection. The useful resources are publicly available at: https://github.com/NLP2CT/LLM-generated-Text-Detection.
4/22/2024
Few-Shot Detection of Machine-Generated Text using Style Representations
Rafael Rivera Soto, Kailin Koch, Aleem Khan, Barry Chen, Marcus Bishop, Nicholas Andrews
0
0
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human author. Some previous approaches to this problem have relied on supervised methods by training on corpora of confirmed human- and machine- written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of newer language models producing still more fluent text than the models used to train the detectors. Other approaches require access to the models that may have generated a document in question, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state-of-the-art large language models like Llama-2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document. The code and data to reproduce our experiments are available at https://github.com/LLNL/LUAR/tree/main/fewshot_iclr2024.
5/9/2024
MUGC: Machine Generated versus User Generated Content Detection
Yaqi Xie, Anjali Rawal, Yujing Cen, Dixuan Zhao, Sunil K Narang, Shanu Sushmita
0
0
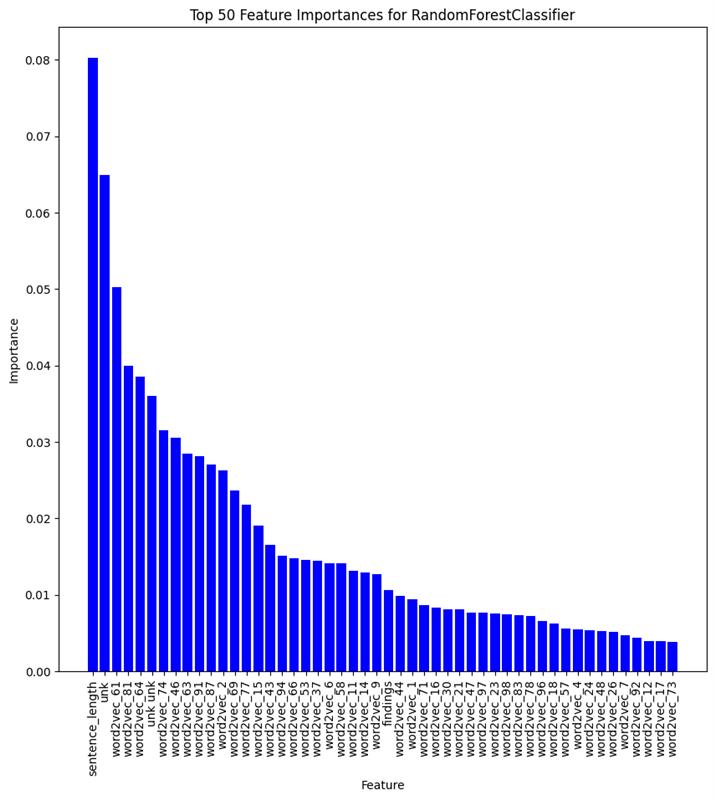
As advanced modern systems like deep neural networks (DNNs) and generative AI continue to enhance their capabilities in producing convincing and realistic content, the need to distinguish between user-generated and machine generated content is becoming increasingly evident. In this research, we undertake a comparative evaluation of eight traditional machine-learning algorithms to distinguish between machine-generated and human-generated data across three diverse datasets: Poems, Abstracts, and Essays. Our results indicate that traditional methods demonstrate a high level of accuracy in identifying machine-generated data, reflecting the documented effectiveness of popular pre-trained models like RoBERT. We note that machine-generated texts tend to be shorter and exhibit less word variety compared to human-generated content. While specific domain-related keywords commonly utilized by humans, albeit disregarded by current LLMs (Large Language Models), may contribute to this high detection accuracy, we show that deeper word representations like word2vec can capture subtle semantic variances. Furthermore, readability, bias, moral, and affect comparisons reveal a discernible contrast between machine-generated and human generated content. There are variations in expression styles and potentially underlying biases in the data sources (human and machine-generated). This study provides valuable insights into the advancing capacities and challenges associated with machine-generated content across various domains.
4/1/2024