pfl-research: simulation framework for accelerating research in Private Federated Learning
2404.06430
0
0

Abstract
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Create account to get full access
Overview
- The paper presents a simulation framework called "pfl-research" for accelerating research in Private Federated Learning (PFL).
- PFL is a machine learning technique that allows multiple parties to train a shared model without directly sharing their private data.
- The pfl-research framework aims to facilitate PFL research by providing a modular and customizable simulation environment.
Plain English Explanation
pfl-research: simulation framework for accelerating research in Private Federated Learning is a tool that helps researchers study and improve a type of machine learning called "Private Federated Learning" (PFL). In PFL, multiple organizations or individuals can work together to train a shared machine learning model without having to share their private data directly.
The pfl-research framework provides a simulated environment where researchers can experiment with different PFL techniques and scenarios. This allows them to test new ideas and strategies without needing access to real-world, sensitive data. The framework is designed to be flexible and customizable, so researchers can adapt it to their specific research needs.
By providing a standardized platform for PFL research, pfl-research aims to accelerate the development of more effective and privacy-preserving machine learning techniques. This could have important implications for a wide range of applications, from healthcare to finance, where data privacy is a critical concern.
Technical Explanation
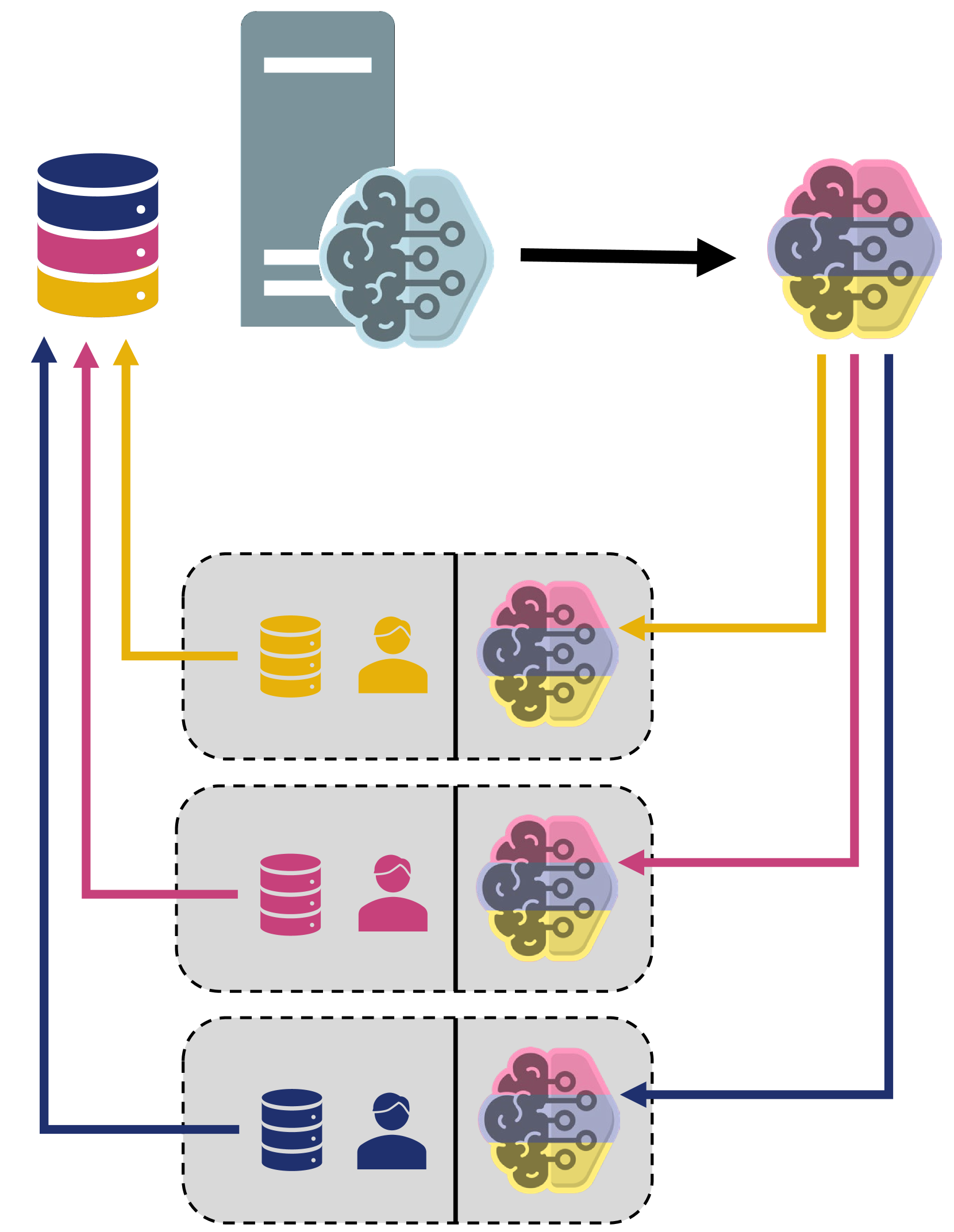
The pfl-research: simulation framework for accelerating research in Private Federated Learning paper presents a modular and customizable simulation framework for Private Federated Learning (PFL) research. PFL is a machine learning approach that allows multiple parties to collaboratively train a shared model without directly sharing their private data.
The pfl-research framework consists of several key components:
- Data Module: Provides mechanisms for simulating realistic data distributions and partitioning data across multiple clients.
- Federated Learning Module: Implements various PFL algorithms, including FedStar, PERADA, and Vertical Federated Learning.
- Communication Module: Simulates the network communication between clients and the server, including constraints such as communication constraints.
- Evaluation Module: Provides tools for assessing the performance of PFL models, including privacy, accuracy, and convergence metrics.
The framework is designed to be highly configurable, allowing researchers to easily modify and extend the various components to suit their specific research needs. This flexibility enables the exploration of a wide range of PFL scenarios and the development of new techniques.
Critical Analysis
The pfl-research framework presents a valuable contribution to the field of PFL research by providing a standardized and customizable simulation environment. This allows researchers to explore and experiment with various PFL algorithms and techniques without the need for access to real-world, sensitive data.
One potential limitation of the framework is that it may not fully capture the complexity and nuances of real-world PFL scenarios. While the authors acknowledge this and emphasize the framework's flexibility, there is a risk that findings from the simulated environment may not translate directly to practical applications.
Additionally, the framework does not currently provide mechanisms for evaluating the fairness or ethical implications of PFL algorithms. As machine learning models become more widely deployed, it is important to consider the potential for unintended biases or discriminatory outcomes, especially in sensitive domains like healthcare or finance.
Future research could explore ways to incorporate fairness and ethics-aware evaluation metrics into the pfl-research framework, helping to ensure that PFL techniques developed using the platform are aligned with important societal values.
Conclusion
The pfl-research: simulation framework for accelerating research in Private Federated Learning paper presents a powerful tool for advancing the state of the art in Private Federated Learning. By providing a modular and customizable simulation environment, the framework enables researchers to quickly prototype and evaluate new PFL algorithms and techniques.
As PFL becomes increasingly important for preserving data privacy in machine learning applications, tools like pfl-research will play a crucial role in driving innovation and ensuring the development of more effective and ethical PFL solutions. By lowering the barriers to PFL research, the framework has the potential to accelerate the adoption of privacy-preserving machine learning techniques across a wide range of industries and application domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024
🏷️
GPT-FL: Generative Pre-trained Model-Assisted Federated Learning
Tuo Zhang, Tiantian Feng, Samiul Alam, Dimitrios Dimitriadis, Sunwoo Lee, Mi Zhang, Shrikanth S. Narayanan, Salman Avestimehr
0
0
In this work, we propose GPT-FL, a generative pre-trained model-assisted federated learning (FL) framework. At its core, GPT-FL leverages generative pre-trained models to generate diversified synthetic data. These generated data are used to train a downstream model on the server, which is then fine-tuned with private client data under the standard FL framework. We show that GPT-FL consistently outperforms state-of-the-art FL methods in terms of model test accuracy, communication efficiency, and client sampling efficiency. Through comprehensive ablation analysis across various data modalities, we discover that the downstream model generated by synthetic data plays a crucial role in controlling the direction of gradient diversity during FL training, which enhances convergence speed and contributes to the notable accuracy boost observed with GPT-FL. Also, regardless of whether the target data falls within or outside the domain of the pre-trained generative model, GPT-FL consistently achieves significant performance gains, surpassing the results obtained by models trained solely with FL or synthetic data. The code is available at https://github.com/AvestimehrResearchGroup/GPT-FL.
6/19/2024