GPT-FL: Generative Pre-trained Model-Assisted Federated Learning

0
🏷️
Sign in to get full access
Overview
- Proposes a new federated learning (FL) framework called GPT-FL that leverages generative pre-trained models to generate synthetic data
- The synthetic data is used to train a downstream model on the server, which is then fine-tuned with private client data under the standard FL framework
- Claims GPT-FL consistently outperforms state-of-the-art FL methods in terms of model test accuracy, communication efficiency, and client sampling efficiency
Plain English Explanation
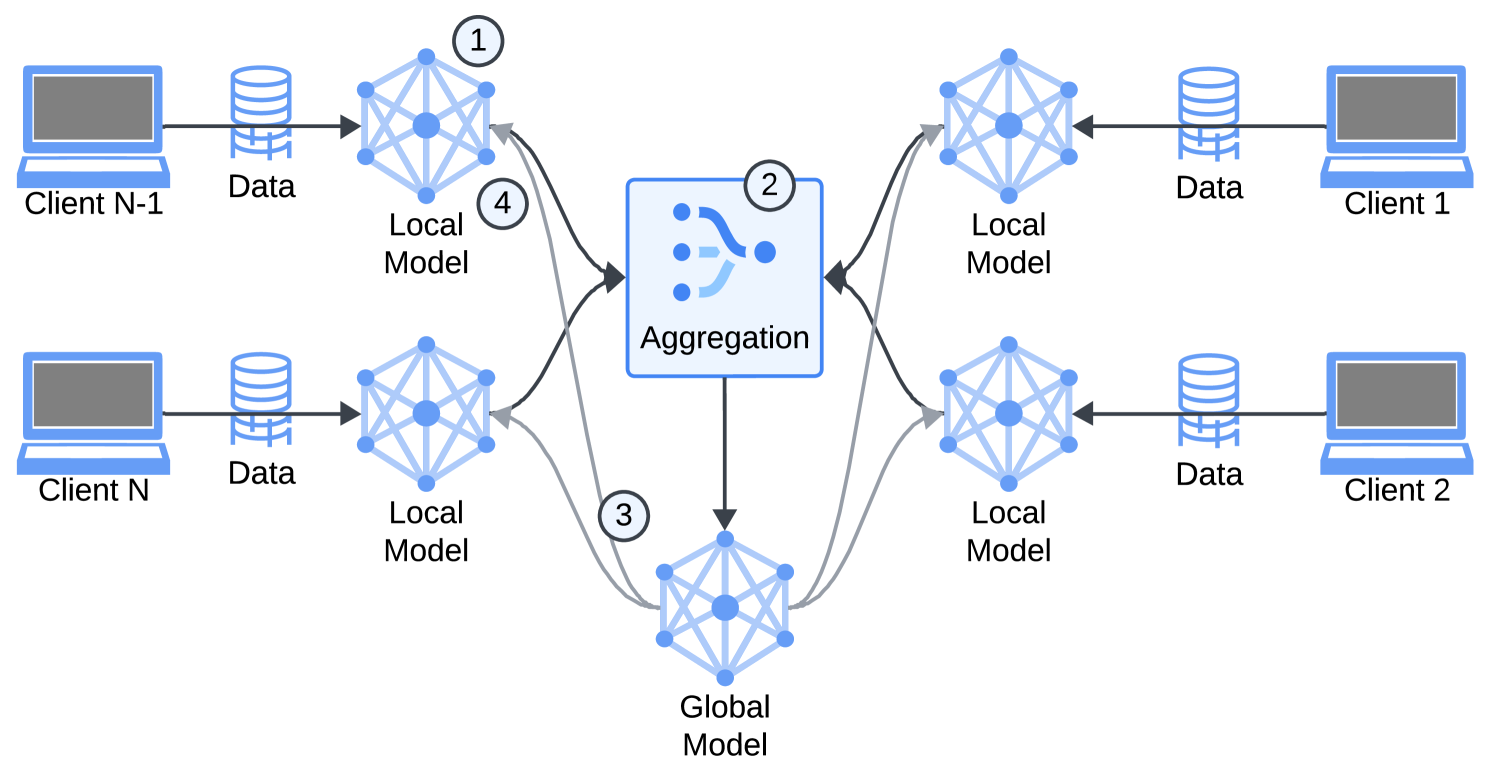
GPT-FL is a new approach to federated learning that aims to improve the performance and efficiency of the learning process. The core idea is to leverage generative pre-trained models to generate synthetic data, which is then used to train a downstream model on the central server. This downstream model is then fine-tuned using the private data from individual clients, following the standard federated learning framework.
The researchers claim that this approach, called GPT-FL, consistently outperforms other state-of-the-art federated learning methods in terms of model accuracy, communication efficiency, and the efficiency of sampling clients. They attribute this to the way the synthetic data generated by the pre-trained model helps control the diversity of gradients during the federated learning process, which in turn boosts the speed of convergence and leads to improved accuracy.
Importantly, the researchers find that GPT-FL can achieve significant performance gains regardless of whether the target data falls within or outside the domain of the pre-trained generative model. This suggests the approach is quite robust and versatile.
Technical Explanation
The key technical elements of the GPT-FL framework are:
-
Generative Pre-trained Model: GPT-FL leverages a pre-trained generative model, such as a GPT model, to generate synthetic data. This synthetic data is used to train a downstream model on the central server.
-
Federated Learning: The downstream model trained on the synthetic data is then fine-tuned using the private data from individual clients, following the standard federated learning framework. This allows the model to learn from distributed data sources without exposing the private client data.
-
Gradient Diversity Control: The researchers discover that the synthetic data generated by the pre-trained model plays a crucial role in controlling the direction of gradient diversity during the federated learning process. This enhanced gradient diversity leads to faster convergence and improved model accuracy.
The researchers conduct comprehensive experiments across various data modalities, including image, text, and tabular data. They show that GPT-FL consistently outperforms state-of-the-art federated learning methods in terms of model test accuracy, communication efficiency, and client sampling efficiency.
Critical Analysis
The researchers acknowledge several caveats and limitations of the GPT-FL approach:
- The performance of GPT-FL is dependent on the quality and relevance of the pre-trained generative model used. If the pre-trained model is not well-suited to the target task or data domain, the synthetic data generated may not be as beneficial.
- The training of the generative pre-trained model and the downstream model in GPT-FL adds additional computational and storage overhead compared to standard federated learning approaches.
- The paper does not explore the impact of different hyperparameter settings or architectural choices on the performance of GPT-FL.
Additionally, it would be interesting to see the researchers address the following potential concerns:
- How well does GPT-FL scale to larger, more complex datasets and model architectures?
- What are the privacy implications of using synthetic data generated from private client data during the federated learning process?
- How does GPT-FL compare to other approaches that leverage generative models in federated learning, such as federated generative learning or collaborative pre-training?
Overall, the GPT-FL framework presents an intriguing approach to improving the performance and efficiency of federated learning, but further research is needed to fully understand its strengths, limitations, and potential implications.
Conclusion
The proposed GPT-FL framework demonstrates a novel way to leverage generative pre-trained models to enhance the performance of federated learning. By generating synthetic data to train a downstream model, which is then fine-tuned on private client data, GPT-FL is able to consistently outperform state-of-the-art federated learning methods in terms of model accuracy, communication efficiency, and client sampling efficiency.
This research highlights the potential of integrating powerful generative models into federated learning pipelines to better control the direction of gradient diversity and boost the overall learning process. As large language models and other advanced generative techniques continue to evolve, the GPT-FL approach may pave the way for further advancements in efficient and accurate federated learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
GPT-FL: Generative Pre-trained Model-Assisted Federated Learning
Tuo Zhang, Tiantian Feng, Samiul Alam, Dimitrios Dimitriadis, Sunwoo Lee, Mi Zhang, Shrikanth S. Narayanan, Salman Avestimehr
In this work, we propose GPT-FL, a generative pre-trained model-assisted federated learning (FL) framework. At its core, GPT-FL leverages generative pre-trained models to generate diversified synthetic data. These generated data are used to train a downstream model on the server, which is then fine-tuned with private client data under the standard FL framework. We show that GPT-FL consistently outperforms state-of-the-art FL methods in terms of model test accuracy, communication efficiency, and client sampling efficiency. Through comprehensive ablation analysis across various data modalities, we discover that the downstream model generated by synthetic data plays a crucial role in controlling the direction of gradient diversity during FL training, which enhances convergence speed and contributes to the notable accuracy boost observed with GPT-FL. Also, regardless of whether the target data falls within or outside the domain of the pre-trained generative model, GPT-FL consistently achieves significant performance gains, surpassing the results obtained by models trained solely with FL or synthetic data. The code is available at https://github.com/AvestimehrResearchGroup/GPT-FL.
Read more6/19/2024
0
A Systematic Review of Federated Generative Models
Ashkan Vedadi Gargary, Emiliano De Cristofaro
Federated Learning (FL) has emerged as a solution for distributed systems that allow clients to train models on their data and only share models instead of local data. Generative Models are designed to learn the distribution of a dataset and generate new data samples that are similar to the original data. Many prior works have tried proposing Federated Generative Models. Using Federated Learning and Generative Models together can be susceptible to attacks, and designing the optimal architecture remains challenging. This survey covers the growing interest in the intersection of FL and Generative Models by comprehensively reviewing research conducted from 2019 to 2024. We systematically compare nearly 100 papers, focusing on their FL and Generative Model methods and privacy considerations. To make this field more accessible to newcomers, we highlight the state-of-the-art advancements and identify unresolved challenges, offering insights for future research in this evolving field.
Read more5/28/2024

0
Federated Generative Learning with Foundation Models
Jie Zhang, Xiaohua Qi, Bo Zhao
Existing approaches in Federated Learning (FL) mainly focus on sending model parameters or gradients from clients to a server. However, these methods are plagued by significant inefficiency, privacy, and security concerns. Thanks to the emerging foundation generative models, we propose a novel federated learning framework, namely Federated Generative Learning. In this framework, each client can create text embeddings that are tailored to their local data, and send embeddings to the server. Then the informative training data can be synthesized remotely on the server using foundation generative models with these embeddings, which can benefit FL tasks. Our proposed framework offers several advantages, including increased communication efficiency, robustness to data heterogeneity, substantial performance improvements, and enhanced privacy protection. We validate these benefits through extensive experiments conducted on 12 datasets. For example, on the ImageNet100 dataset with a highly skewed data distribution, our method outperforms FedAvg by 12% in a single communication round, compared to FedAvg's performance over 200 communication rounds. We have released the code for all experiments conducted in this study.
Read more6/4/2024

0
MLLM-FL: Multimodal Large Language Model Assisted Federated Learning on Heterogeneous and Long-tailed Data
Jianyi Zhang, Hao Frank Yang, Ang Li, Xin Guo, Pu Wang, Haiming Wang, Yiran Chen, Hai Li
Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-FL), which which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, prior to local training on local datasets of clients, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of multimodal large language models. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.
Read more9/11/2024