Phikon-v2, A large and public feature extractor for biomarker prediction

0
Sign in to get full access
Overview
- Phikon-v2 is a large and publicly available feature extractor for biomarker prediction.
- It is designed to serve as a foundational model for a variety of biomedical and healthcare applications.
- The paper describes the development and evaluation of Phikon-v2, highlighting its performance and potential applications.
Plain English Explanation
Phikon-v2 is a powerful AI model that can be used to extract important features from medical data, such as medical images or patient records. These extracted features can then be used to predict biomarkers, which are measurable indicators of some biological state or condition.
The researchers who created Phikon-v2 wanted to develop a model that could be widely used by other researchers and healthcare professionals in their own projects. They trained the model on a large amount of diverse medical data, so that it could be applied to a variety of different tasks and datasets.
One of the key advantages of Phikon-v2 is that it is publicly available, meaning that anyone can access and use the model for their own research or applications. This can help to accelerate the development of new medical technologies and treatments, as researchers can build upon the work of others instead of having to start from scratch.
The paper describes the performance of Phikon-v2 on a range of biomedical tasks, and shows that it outperforms other state-of-the-art models in many cases. This suggests that Phikon-v2 could be a valuable tool for researchers and clinicians working in fields like disease diagnosis, drug discovery, and personalized medicine.
Technical Explanation
The Phikon-v2 paper presents the development and evaluation of a large, publicly available feature extractor for biomedical applications. The model is designed to serve as a foundational model for a variety of downstream tasks, such as biomarker prediction, disease diagnosis, and drug discovery.
The researchers trained Phikon-v2 on a diverse dataset of medical images, text, and structured data, using a self-supervised learning approach to learn general-purpose features. They then evaluated the model's performance on a range of biomedical benchmarks, including disease classification, patient outcome prediction, and drug response prediction.
The results show that Phikon-v2 outperforms other state-of-the-art models in many of these tasks, even when fine-tuned on smaller datasets. This suggests that the features learned by Phikon-v2 are highly transferable and can be effectively leveraged for a variety of biomedical applications.
Furthermore, the researchers made Phikon-v2 publicly available, allowing other researchers and developers to use and build upon the model in their own work. This can help to accelerate the development of new medical technologies and facilitate collaboration across the field.
Critical Analysis
The Phikon-v2 paper presents a comprehensive and well-designed study, showcasing the potential of large, public feature extractors for advancing biomedical research and applications.
One potential limitation of the study is the reliance on retrospective datasets, which may not fully capture the complexity and diversity of real-world clinical scenarios. Additionally, the paper does not delve into the potential ethical and privacy considerations associated with the use of large-scale medical data for model training and deployment.
It would be interesting to see further research on the interpretability and explainability of the features learned by Phikon-v2, as well as their robustness to distributional shift and noise in real-world clinical settings. Exploring the model's performance on more diverse and challenging biomedical tasks could also provide valuable insights.
Overall, the Phikon-v2 paper demonstrates the power of large-scale, publicly available feature extractors and highlights the importance of fostering collaboration and shared resources in the biomedical AI community.
Conclusion
The Phikon-v2 paper presents a significant contribution to the field of biomedical AI, with the development of a large and publicly available feature extractor that can be leveraged for a variety of important applications. By making Phikon-v2 freely available, the researchers have taken an important step towards democratizing access to powerful AI tools and accelerating innovation in the healthcare and life sciences domains.
The strong performance of Phikon-v2 on a range of biomedical benchmarks suggests that it could be a valuable resource for researchers and developers working on disease diagnosis, drug discovery, and personalized medicine. As the field of biomedical AI continues to evolve, tools like Phikon-v2 will likely play an increasingly important role in driving progress and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Phikon-v2, A large and public feature extractor for biomarker prediction
Alexandre Filiot, Paul Jacob, Alice Mac Kain, Charlie Saillard
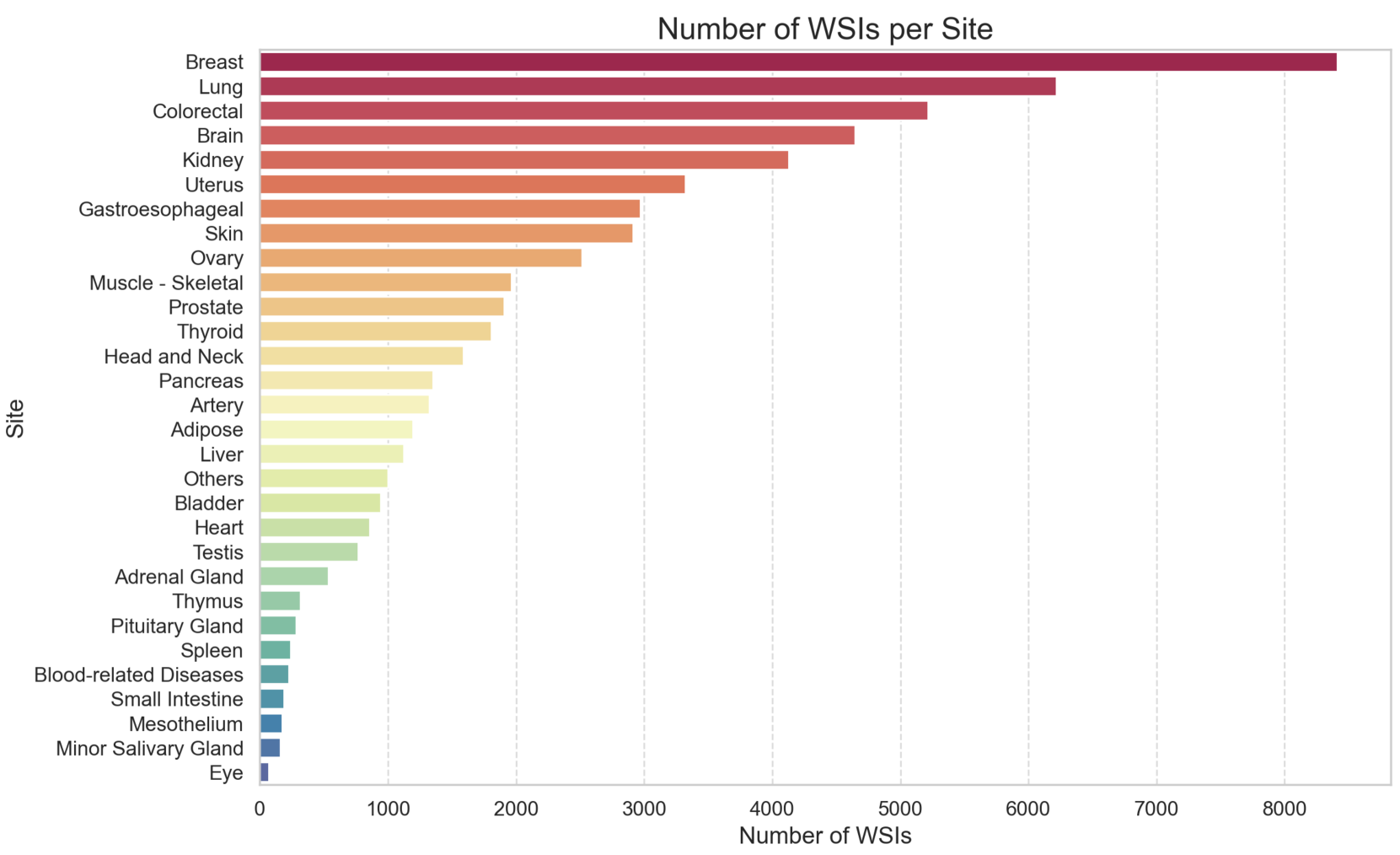
Gathering histopathology slides from over 100 publicly available cohorts, we compile a diverse dataset of 460 million pathology tiles covering more than 30 cancer sites. Using this dataset, we train a large self-supervised vision transformer using DINOv2 and publicly release one iteration of this model for further experimentation, coined Phikon-v2. While trained on publicly available histology slides, Phikon-v2 surpasses our previously released model (Phikon) and performs on par with other histopathology foundation models (FM) trained on proprietary data. Our benchmarks include eight slide-level tasks with results reported on external validation cohorts avoiding any data contamination between pre-training and evaluation datasets. Our downstream training procedure follows a simple yet robust ensembling strategy yielding a +1.75 AUC increase across tasks and models compared to one-shot retraining (p<0.001). We compare Phikon (ViT-B) and Phikon-v2 (ViT-L) against 14 different histology feature extractors, making our evaluation the most comprehensive to date. Our result support evidences that DINOv2 handles joint model and data scaling better than iBOT. Also, we show that recent scaling efforts are overall beneficial to downstream performance in the context of biomarker prediction with GigaPath and H-Optimus-0 (two ViT-g with 1.1B parameters each) standing out. However, the statistical margins between the latest top-performing FMs remain mostly non-significant; some even underperform on specific indications or tasks such as MSI prediction - deposed by a 13x smaller model developed internally. While latest foundation models may exhibit limitations for clinical deployment, they nonetheless offer excellent grounds for the development of more specialized and cost-efficient histology encoders fueling AI-guided diagnostic tools.
Read more9/17/2024

0
Virchow 2: Scaling Self-Supervised Mixed Magnification Models in Pathology
Eric Zimmermann, Eugene Vorontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, Thomas Fuchs, Nicolo Fusi, Siqi Liu, Kristen Severson
Foundation models are rapidly being developed for computational pathology applications. However, it remains an open question which factors are most important for downstream performance with data scale and diversity, model size, and training algorithm all playing a role. In this work, we propose algorithmic modifications, tailored for pathology, and we present the result of scaling both data and model size, surpassing previous studies in both dimensions. We introduce two new models: Virchow2, a 632 million parameter vision transformer, and Virchow2G, a 1.9 billion parameter vision transformer, each trained with 3.1 million histopathology whole slide images, with diverse tissues, originating institutions, and stains. We achieve state of the art performance on 12 tile-level tasks, as compared to the top performing competing models. Our results suggest that data diversity and domain-specific methods can outperform models that only scale in the number of parameters, but, on average, performance benefits from the combination of domain-specific methods, data scale, and model scale.
Read more8/16/2024
0
Hibou: A Family of Foundational Vision Transformers for Pathology
Dmitry Nechaev, Alexey Pchelnikov, Ekaterina Ivanova
Pathology, the microscopic examination of diseased tissue, is critical for diagnosing various medical conditions, particularly cancers. Traditional methods are labor-intensive and prone to human error. Digital pathology, which converts glass slides into high-resolution digital images for analysis by computer algorithms, revolutionizes the field by enhancing diagnostic accuracy, consistency, and efficiency through automated image analysis and large-scale data processing. Foundational transformer pretraining is crucial for developing robust, generalizable models as it enables learning from vast amounts of unannotated data. This paper introduces the Hibou family of foundational vision transformers for pathology, leveraging the DINOv2 framework to pretrain two model variants, Hibou-B and Hibou-L, on a proprietary dataset of over 1 million whole slide images (WSIs) representing diverse tissue types and staining techniques. Our pretrained models demonstrate superior performance on both patch-level and slide-level benchmarks, surpassing existing state-of-the-art methods. Notably, Hibou-L achieves the highest average accuracy across multiple benchmark datasets. To support further research and application in the field, we have open-sourced the Hibou models, which can be accessed at https://github.com/HistAI/hibou.
Read more8/21/2024
✨
0
Benchmarking foundation models as feature extractors for weakly-supervised computational pathology
Peter Neidlinger, Omar S. M. El Nahhas, Hannah Sophie Muti, Tim Lenz, Michael Hoffmeister, Hermann Brenner, Marko van Treeck, Rupert Langer, Bastian Dislich, Hans Michael Behrens, Christoph Rocken, Sebastian Foersch, Daniel Truhn, Antonio Marra, Oliver Lester Saldanha, Jakob Nikolas Kather
Advancements in artificial intelligence have driven the development of numerous pathology foundation models capable of extracting clinically relevant information. However, there is currently limited literature independently evaluating these foundation models on truly external cohorts and clinically-relevant tasks to uncover adjustments for future improvements. In this study, we benchmarked ten histopathology foundation models on 13 patient cohorts with 6,791 patients and 9,493 slides from lung, colorectal, gastric, and breast cancers. The models were evaluated on weakly-supervised tasks related to biomarkers, morphological properties, and prognostic outcomes. We show that a vision-language foundation model, CONCH, yielded the highest performance in 42% of tasks when compared to vision-only foundation models. The experiments reveal that foundation models trained on distinct cohorts learn complementary features to predict the same label, and can be fused to outperform the current state of the art. Creating an ensemble of complementary foundation models outperformed CONCH in 66% of tasks. Moreover, our findings suggest that data diversity outweighs data volume for foundation models. Our work highlights actionable adjustments to improve pathology foundation models.
Read more8/29/2024