Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
2404.02726
0
0
Abstract
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
Create account to get full access
Overview
- This paper explores the use of large vision-language models (VLMs) for detecting synthetic images.
- The researchers investigate how VLMs can be leveraged to identify AI-generated or manipulated images, which is an important task in the fight against misinformation and deepfakes.
- The paper presents a novel approach that combines VLM-based image classification with additional techniques to enhance synthetic image detection performance.
Plain English Explanation
The paper focuses on using powerful vision-language models to detect synthetic or manipulated images. These types of AI-generated or edited images are a growing concern, as they can be used to spread misinformation or create deepfakes - misleading media that appears real.
The researchers explore how these large vision-language models can be leveraged to identify synthetic images. They propose a novel approach that combines the image classification capabilities of VLMs with additional techniques to enhance the detection of these kinds of manipulated or generated images.
The goal is to harness the power of these advanced vision-language models to help combat the growing problem of synthetic and misleading media, which can have serious societal implications if left unchecked.
Technical Explanation
The paper's key contribution is a novel approach that utilizes large vision-language models for synthetic image detection. The researchers leverage the powerful multimodal capabilities of VLMs, which are trained on vast amounts of image and text data, to classify images as either synthetic or real.
The proposed method combines VLM-based image classification with additional techniques to further enhance the detection performance. This includes incorporating vision-language features into the model, as well as leveraging anomaly detection and outlier analysis approaches to identify images that are likely to be synthetic.
Through extensive experiments, the researchers demonstrate the effectiveness of their approach in accurately detecting synthetic images across a range of datasets and scenarios. The results highlight the potential of large VLMs to play a crucial role in addressing the growing challenge of misinformation and deepfakes in the digital age.
Critical Analysis
The paper presents a promising approach for utilizing advanced vision-language models to detect synthetic images. However, the researchers acknowledge that their method has some limitations, such as the potential for overfitting to specific datasets or types of synthetic images.
Additionally, the paper does not address the potential for adversarial attacks, where synthetic image generators may adapt to evade the detection system. Further research would be needed to understand the robustness of the proposed approach in the face of evolving synthetic image generation techniques.
It's also important to consider the ethical implications of this technology, as the ability to accurately detect synthetic media could have significant societal and political implications. The researchers should thoughtfully consider the responsible development and deployment of such systems to ensure they are not misused or abused.
Conclusion
This paper presents a novel approach that leverages large vision-language models for the detection of synthetic images. The researchers demonstrate the effectiveness of their method in accurately identifying AI-generated or manipulated media, which is a crucial step in addressing the growing challenge of misinformation and deepfakes.
The findings of this study highlight the potential of advanced multimodal vision-language models to play a vital role in combating the spread of synthetic and misleading content online. As the technology continues to evolve, this research could have significant implications for a wide range of applications, from social media monitoring to forensic image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
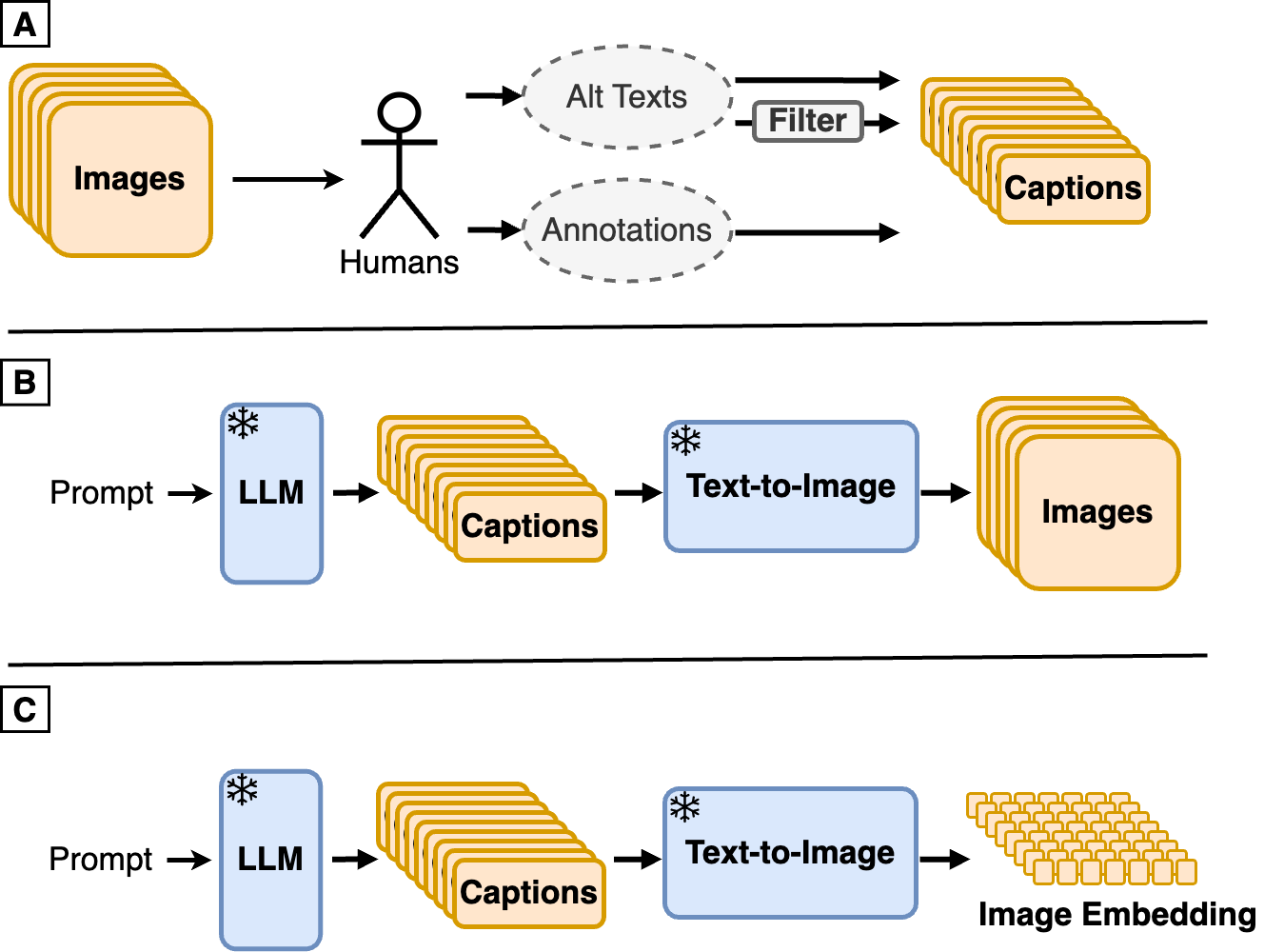
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024

Bi-LORA: A Vision-Language Approach for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hessen Bougueffa Eutamene, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
Advancements in deep image synthesis techniques, such as generative adversarial networks (GANs) and diffusion models (DMs), have ushered in an era of generating highly realistic images. While this technological progress has captured significant interest, it has also raised concerns about the potential difficulty in distinguishing real images from their synthetic counterparts. This paper takes inspiration from the potent convergence capabilities between vision and language, coupled with the zero-shot nature of vision-language models (VLMs). We introduce an innovative method called Bi-LORA that leverages VLMs, combined with low-rank adaptation (LORA) tuning techniques, to enhance the precision of synthetic image detection for unseen model-generated images. The pivotal conceptual shift in our methodology revolves around reframing binary classification as an image captioning task, leveraging the distinctive capabilities of cutting-edge VLM, notably bootstrapping language image pre-training (BLIP2). Rigorous and comprehensive experiments are conducted to validate the effectiveness of our proposed approach, particularly in detecting unseen diffusion-generated images from unknown diffusion-based generative models during training, showcasing robustness to noise, and demonstrating generalization capabilities to GANs. The obtained results showcase an impressive average accuracy of 93.41% in synthetic image detection on unseen generation models. The code and models associated with this research can be publicly accessed at https://github.com/Mamadou-Keita/VLM-DETECT.
4/9/2024
📊
ALLaVA: Harnessing GPT4V-Synthesized Data for Lite Vision-Language Models
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, Benyou Wang
0
0
Large vision-language models (LVLMs) have shown premise in a broad range of vision-language tasks with their strong reasoning and generalization capabilities. However, they require considerable computational resources for training and deployment. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To this end, we propose a comprehensive pipeline for generating a synthetic dataset. The key idea is to leverage strong proprietary models to generate (i) fine-grained image annotations for vision-language alignment and (ii) complex reasoning visual question-answering pairs for visual instruction fine-tuning, yielding 1.3M samples in total. We train a series of lite VLMs on the synthetic dataset and experimental results demonstrate the effectiveness of the proposed scheme, where they achieve competitive performance on 17 benchmarks among 4B LVLMs, and even perform on par with 7B/13B-scale models on various benchmarks. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. We name our dataset textit{ALLaVA}, and open-source it to research community for developing better resource-efficient LVLMs for wider usage.
6/18/2024

An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
0
0
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
5/28/2024