PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
2404.04421
0
0

Abstract
Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
Create account to get full access
Overview
- This paper presents PhysAvatar, a system that learns the physics of dressed 3D avatars from visual observations.
- PhysAvatar aims to generate realistic animations of 3D avatars wearing different types of clothing and accessories, such as shirts, skirts, and hats.
- The key idea is to capture the complex physical interactions between the avatar's body and the surrounding clothes/objects through machine learning, allowing for more natural and lifelike animations.
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/3dgs-avatar-animatable-avatars-via-deformable-3d">3DGS</a>, <a href="https://aimodels.fyi/papers/arxiv/gavatar-animatable-3d-gaussian-avatars-implicit-mesh">GAvatar</a>, and <a href="https://aimodels.fyi/papers/arxiv/flashavatar-high-fidelity-head-avatar-efficient-gaussian">FlashAvatar</a> have shown how to create 3D avatars and animate them. However, these avatars often look stiff or unnatural when wearing clothes or accessories.
The PhysAvatar system aims to solve this problem by learning how clothes and objects interact with the 3D avatar's body from visual data. By understanding the physics of these interactions, the system can generate much more realistic animations of 3D avatars wearing different outfits.
For example, imagine a 3D avatar wearing a flowing dress. As the avatar moves, the dress should realistically billow and drape around the body, responding to the avatar's movements. PhysAvatar tries to capture these complex physical effects, allowing for more lifelike and dynamic 3D avatar animations.
This could be useful for a wide range of applications, such as virtual try-on, video games, and even augmented reality experiences where users want to see themselves or others wearing different outfits in a realistic way. <a href="https://aimodels.fyi/papers/arxiv/fashionengine-interactive-generation-editing-3d-clothed-humans">FashionEngine</a> and <a href="https://aimodels.fyi/papers/arxiv/instantavatar-efficient-3d-head-reconstruction-via-surface">InstantAvatar</a> have also explored related problems in this area.
Technical Explanation
The key technical innovation of PhysAvatar is its ability to learn the physics of how 3D avatars interact with clothes and accessories from visual data alone, without requiring explicit physics simulations or complex 3D modeling.
The system takes in videos of people wearing different outfits and uses computer vision techniques to extract the 3D geometry of the person's body and the clothes/objects. It then trains a machine learning model to predict how the clothes and accessories will move and deform in response to the avatar's movements.
This allows PhysAvatar to generate realistic animations of 3D avatars wearing new outfits, even if those outfits have never been seen before. The model has learned the underlying physical rules governing how clothes behave, so it can apply that knowledge to new situations.
The paper describes the model architecture, training process, and extensive evaluation of PhysAvatar's performance on a variety of tasks, including garment reconstruction, motion prediction, and visual realism. The results demonstrate significant improvements over prior state-of-the-art approaches for creating animated 3D avatars.
Critical Analysis
One potential limitation of PhysAvatar is that it relies on having access to a large corpus of visual data showing people wearing different outfits. In practice, gathering and annotating such a dataset could be challenging and time-consuming.
Additionally, the paper does not address how PhysAvatar would handle very complex or unusual garments, such as flowing capes or highly articulated costumes. The learned physical models may struggle to generalize to these more exotic types of clothing and accessories.
Further research could investigate ways to make the system more data-efficient, perhaps by incorporating prior knowledge about physics or leveraging synthetic data generation. Exploring ways to handle a wider range of clothing types would also enhance the system's versatility and real-world applicability.
Overall, though, PhysAvatar represents an exciting step forward in creating more realistic and lifelike 3D avatars, with promising implications for various applications in entertainment, retail, and beyond.
Conclusion
The PhysAvatar system presents a novel approach to generating animated 3D avatars that can realistically wear and interact with a variety of clothes and accessories. By learning the underlying physics of these interactions from visual data, the system can create much more natural and dynamic avatar animations compared to previous methods.
This work has the potential to significantly improve the realism and immersion of various applications, from virtual try-on and video games to augmented reality experiences. As the field of 3D avatar generation continues to evolve, techniques like PhysAvatar will likely play an increasingly important role in making these digital representations feel more human-like and believable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
Siyou Lin, Zhe Li, Zhaoqi Su, Zerong Zheng, Hongwen Zhang, Yebin Liu
0
0
Animatable clothing transfer, aiming at dressing and animating garments across characters, is a challenging problem. Most human avatar works entangle the representations of the human body and clothing together, which leads to difficulties for virtual try-on across identities. What's worse, the entangled representations usually fail to exactly track the sliding motion of garments. To overcome these limitations, we present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multi-view videos. Our representation is built upon the Gaussian map-based avatar for its excellent representation power of garment details. However, the Gaussian map produces unstructured 3D Gaussians distributed around the actual surface. The absence of a smooth explicit surface raises challenges in accurate garment tracking and collision handling between body and garments. Therefore, we propose two-stage training involving single-layer reconstruction and multi-layer fitting. In the single-layer reconstruction stage, we propose a series of geometric constraints to reconstruct smooth surfaces and simultaneously obtain the segmentation between body and clothing. Next, in the multi-layer fitting stage, we train two separate models to represent body and clothing and utilize the reconstructed clothing geometries as 3D supervision for more accurate garment tracking. Furthermore, we propose geometry and rendering layers for both high-quality geometric reconstruction and high-fidelity rendering. Overall, the proposed LayGA realizes photorealistic animations and virtual try-on, and outperforms other baseline methods. Our project page is https://jsnln.github.io/layga/index.html.
5/14/2024
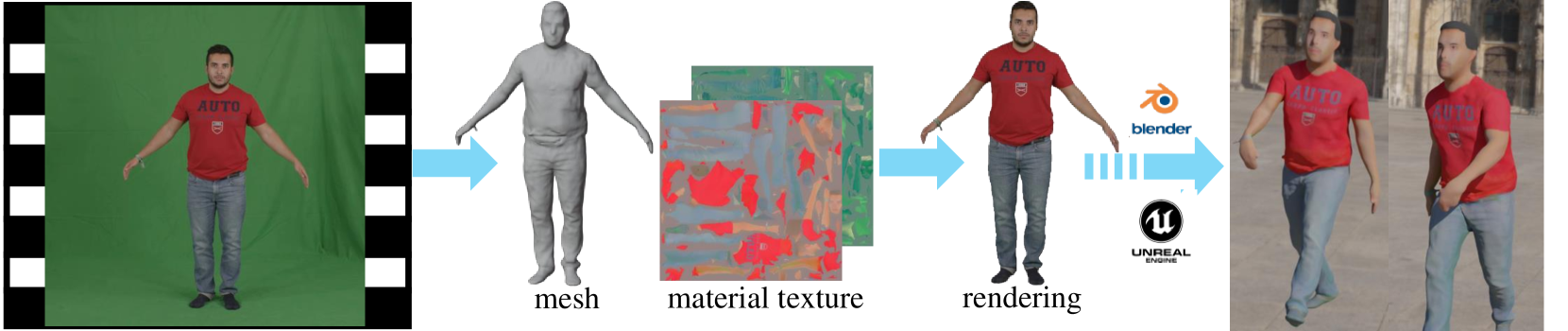
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024
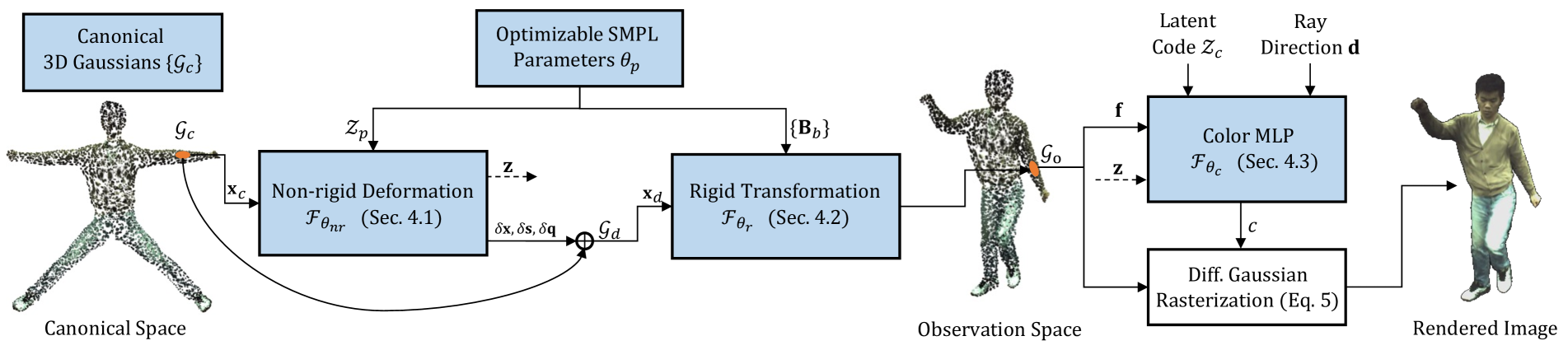
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
0
0
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
4/5/2024
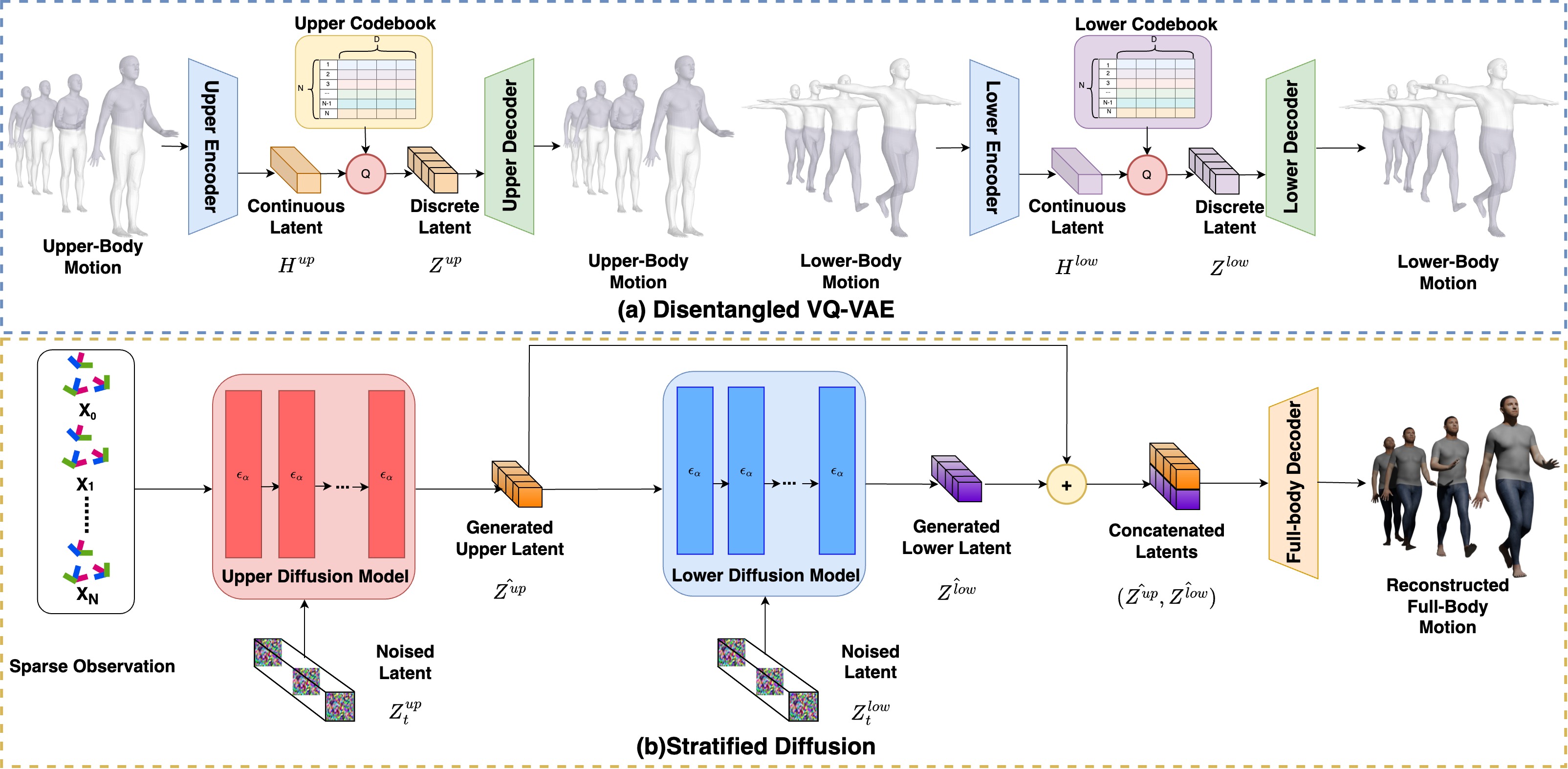
Stratified Avatar Generation from Sparse Observations
Han Feng, Wenchao Ma, Quankai Gao, Xianwei Zheng, Nan Xue, Huijuan Xu
0
0
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
6/4/2024