Physics-Informed Critic in an Actor-Critic Reinforcement Learning for Swimming in Turbulence
2406.10242
0
0

Abstract
Turbulent diffusion causes particles placed in proximity to separate. We investigate the required swimming efforts to maintain a particle close to its passively advected counterpart. We explore optimally balancing these efforts with the intended goal by developing and comparing a novel Physics-Informed Reinforcement Learning (PIRL) strategy with prescribed control (PC) and standard physics-agnostic Reinforcement Learning strategies. Our PIRL scheme, coined the Actor-Physicist, is an adaptation of the Actor-Critic algorithm in which the Neural Network parameterized Critic is replaced with an analytically derived physical heuristic function (the physicist). This strategy is then compared with an analytically computed optimal PC policy derived from a stochastic optimal control formulation and standard physics-agnostic Actor-Critic type algorithms.
Create account to get full access
Overview
- This paper presents a novel actor-critic reinforcement learning approach that incorporates physics-informed knowledge into the critic network to improve the performance of an agent swimming in a turbulent fluid environment.
- The proposed method, called Physics-Informed Critic in an Actor-Critic Reinforcement Learning (PICAC), aims to learn a more accurate value function by leveraging the underlying physics of the system, leading to more efficient and effective swimming behavior.
- The approach is evaluated on a simulated swimming task in a turbulent fluid, demonstrating significant improvements in terms of swimming speed and energy efficiency compared to a standard actor-critic method.
Plain English Explanation
The researchers have developed a new way of training an artificial intelligence (AI) system to control the movements of a simulated swimming creature. The key idea is to incorporate knowledge about the physics of fluids (like water) into the "critic" part of the AI system, which evaluates the quality of the creature's actions.
By doing this, the AI can learn more effectively how to swim efficiently in a turbulent (chaotic) fluid environment, rather than relying solely on trial-and-error learning. The researchers call their approach the "Physics-Informed Critic in an Actor-Critic Reinforcement Learning" (PICAC) method.
In the simulations, the PICAC-trained swimmer was able to swim faster and more efficiently compared to a standard actor-critic method that didn't use the physics-based critic. This suggests that incorporating domain-specific knowledge, like the physics of fluids, can be a powerful way to improve the performance of AI systems in complex physical environments.
The PDP: Physics-based Character Animation via Diffusion and PI-Fusion: Physics-Informed Diffusion Model Learning papers also explore ways of incorporating physical principles into machine learning models, which could be relevant to this research.
Technical Explanation
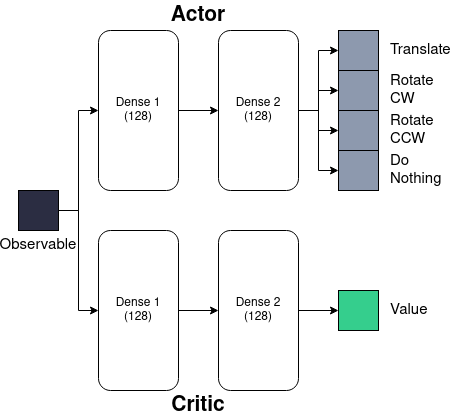
The key innovation in this paper is the integration of physics-informed knowledge into the critic network of an actor-critic reinforcement learning (RL) framework. The PICAC method aims to learn a more accurate value function by leveraging the underlying physics of the fluid environment, which the agent (i.e., the swimming creature) needs to navigate.
The PICAC architecture consists of an actor network that produces the agent's actions (i.e., swimming motions) and a critic network that evaluates the quality of those actions. The critic network is designed to incorporate physics-based constraints and principles, such as the Navier-Stokes equations governing fluid dynamics.
During training, the PICAC agent learns to optimize its swimming behavior by maximizing the rewards received from the physics-informed critic, which provides a more reliable and informative evaluation of the agent's actions compared to a standard critic network.
The researchers evaluate the PICAC approach on a simulated swimming task in a turbulent fluid environment. The results show that the PICAC agent significantly outperforms a standard actor-critic RL agent in terms of swimming speed and energy efficiency.
This work builds upon prior research in Emergence of Chemotactic Strategies in Multi-Agent Reinforcement Learning and Adaptive Actor-Critic Based Optimal Regulation of Drift, which have explored ways of incorporating domain-specific knowledge into RL agents.
Critical Analysis
The PICAC approach represents a promising step towards more effective and efficient reinforcement learning in complex physical environments. By integrating physics-informed constraints and principles into the critic network, the researchers have demonstrated significant performance improvements compared to a standard actor-critic method.
However, the paper does not provide a detailed analysis of the limitations and potential drawbacks of the PICAC approach. For example, it is unclear how sensitive the method is to the accuracy of the physics-based models used in the critic network, and how well it would generalize to different fluid environments or swimming tasks.
Additionally, the paper does not address the computational overhead and training complexity of the PICAC method, which may be higher than a standard actor-critic approach due to the additional physics-based components. Further research is needed to understand the trade-offs and practical considerations of deploying PICAC in real-world applications.
The PIRD: Physics-Informed Residual Diffusion for Flow Field Prediction paper explores a related approach of incorporating physics constraints into a diffusion-based machine learning model, which could provide useful insights for improving the PICAC method.
Conclusion
The PICAC approach presented in this paper represents a significant advancement in the field of reinforcement learning for physical systems. By incorporating physics-informed knowledge into the critic network, the researchers have demonstrated that agents can learn more effective and efficient swimming behaviors in turbulent fluid environments.
The success of the PICAC method highlights the potential benefits of leveraging domain-specific knowledge to enhance the performance of AI systems in complex physical tasks. As the field of reinforcement learning continues to evolve, incorporating such physics-based constraints and principles could become an increasingly important strategy for developing robust and capable agents capable of operating in the real world.
Future research in this area could explore the generalization of the PICAC approach to a wider range of physical environments and tasks, as well as ways to further optimize the computational and training efficiency of the method. Nonetheless, this work represents an important step forward in the quest to create AI systems that can seamlessly interact with and navigate the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Emergence of Chemotactic Strategies with Multi-Agent Reinforcement Learning
Samuel Tovey, Christoph Lohrmann, Christian Holm
0
0
Reinforcement learning (RL) is a flexible and efficient method for programming micro-robots in complex environments. Here we investigate whether reinforcement learning can provide insights into biological systems when trained to perform chemotaxis. Namely, whether we can learn about how intelligent agents process given information in order to swim towards a target. We run simulations covering a range of agent shapes, sizes, and swim speeds to determine if the physical constraints on biological swimmers, namely Brownian motion, lead to regions where reinforcement learners' training fails. We find that the RL agents can perform chemotaxis as soon as it is physically possible and, in some cases, even before the active swimming overpowers the stochastic environment. We study the efficiency of the emergent policy and identify convergence in agent size and swim speeds. Finally, we study the strategy adopted by the reinforcement learning algorithm to explain how the agents perform their tasks. To this end, we identify three emerging dominant strategies and several rare approaches taken. These strategies, whilst producing almost identical trajectories in simulation, are distinct and give insight into the possible mechanisms behind which biological agents explore their environment and respond to changing conditions.
4/3/2024
Adaptive Actor-Critic Based Optimal Regulation for Drift-Free Uncertain Nonlinear Systems
Ashwin P. Dani, Shubhendu Bhasin
0
0
In this paper, a continuous-time adaptive actor-critic reinforcement learning (RL) controller is developed for drift-free nonlinear systems. Practical examples of such systems are image-based visual servoing (IBVS) and wheeled mobile robots (WMR), where the system dynamics includes a parametric uncertainty in the control effectiveness matrix with no drift term. The uncertainty in the input term poses a challenge for developing a continuous-time RL controller using existing methods. In this paper, an actor-critic or synchronous policy iteration (PI)-based RL controller is presented with a concurrent learning (CL)-based parameter update law for estimating the unknown parameters of the control effectiveness matrix. An infinite-horizon value function minimization objective is achieved by regulating the current states to the desired with near-optimal control efforts. The proposed controller guarantees closed-loop stability and simulation results validate the proposed theory using IBVS and WMR examples.
6/14/2024

Pi-fusion: Physics-informed diffusion model for learning fluid dynamics
Jing Qiu, Jiancheng Huang, Xiangdong Zhang, Zeng Lin, Minglei Pan, Zengding Liu, Fen Miao
0
0
Physics-informed deep learning has been developed as a novel paradigm for learning physical dynamics recently. While general physics-informed deep learning methods have shown early promise in learning fluid dynamics, they are difficult to generalize in arbitrary time instants in real-world scenario, where the fluid motion can be considered as a time-variant trajectory involved large-scale particles. Inspired by the advantage of diffusion model in learning the distribution of data, we first propose Pi-fusion, a physics-informed diffusion model for predicting the temporal evolution of velocity and pressure field in fluid dynamics. Physics-informed guidance sampling is proposed in the inference procedure of Pi-fusion to improve the accuracy and interpretability of learning fluid dynamics. Furthermore, we introduce a training strategy based on reciprocal learning to learn the quasiperiodical pattern of fluid motion and thus improve the generalizability of the model. The proposed approach are then evaluated on both synthetic and real-world dataset, by comparing it with state-of-the-art physics-informed deep learning methods. Experimental results show that the proposed approach significantly outperforms existing methods for predicting temporal evolution of velocity and pressure field, confirming its strong generalization by drawing probabilistic inference of forward process and physics-informed guidance sampling. The proposed Pi-fusion can also be generalized in learning other physical dynamics governed by partial differential equations.
6/7/2024

PDP: Physics-Based Character Animation via Diffusion Policy
Takara E. Truong, Michael Piseno, Zhaoming Xie, C. Karen Liu
0
0
Generating diverse and realistic human motion that can physically interact with an environment remains a challenging research area in character animation. Meanwhile, diffusion-based methods, as proposed by the robotics community, have demonstrated the ability to capture highly diverse and multi-modal skills. However, naively training a diffusion policy often results in unstable motions for high-frequency, under-actuated control tasks like bipedal locomotion due to rapidly accumulating compounding errors, pushing the agent away from optimal training trajectories. The key idea lies in using RL policies not just for providing optimal trajectories but for providing corrective actions in sub-optimal states, giving the policy a chance to correct for errors caused by environmental stimulus, model errors, or numerical errors in simulation. Our method, Physics-Based Character Animation via Diffusion Policy (PDP), combines reinforcement learning (RL) and behavior cloning (BC) to create a robust diffusion policy for physics-based character animation. We demonstrate PDP on perturbation recovery, universal motion tracking, and physics-based text-to-motion synthesis.
6/4/2024