Emergence of Chemotactic Strategies with Multi-Agent Reinforcement Learning
2404.01999
0
0
Abstract
Reinforcement learning (RL) is a flexible and efficient method for programming micro-robots in complex environments. Here we investigate whether reinforcement learning can provide insights into biological systems when trained to perform chemotaxis. Namely, whether we can learn about how intelligent agents process given information in order to swim towards a target. We run simulations covering a range of agent shapes, sizes, and swim speeds to determine if the physical constraints on biological swimmers, namely Brownian motion, lead to regions where reinforcement learners' training fails. We find that the RL agents can perform chemotaxis as soon as it is physically possible and, in some cases, even before the active swimming overpowers the stochastic environment. We study the efficiency of the emergent policy and identify convergence in agent size and swim speeds. Finally, we study the strategy adopted by the reinforcement learning algorithm to explain how the agents perform their tasks. To this end, we identify three emerging dominant strategies and several rare approaches taken. These strategies, whilst producing almost identical trajectories in simulation, are distinct and give insight into the possible mechanisms behind which biological agents explore their environment and respond to changing conditions.
Create account to get full access
Overview
- Researchers used reinforcement learning to train a group of artificial agents to develop chemotactic (movement toward or away from a chemical stimulus) strategies.
- The agents were able to learn effective chemotactic behaviors without being explicitly programmed with that capability.
- This demonstrates how complex behaviors can emerge through multi-agent reinforcement learning in simulated environments.
Plain English Explanation
The paper describes an experiment where a group of artificial agents, similar to simple computer programs, were trained to move around and respond to chemical stimuli in their environment. These agents did not have any pre-programmed understanding of chemotaxis - the ability to sense and move towards or away from chemical gradients. Instead, the agents were trained using a reinforcement learning approach, where they received rewards for taking actions that helped them achieve a goal.
Over time, the agents were able to learn effective chemotactic strategies on their own, without being explicitly told how to do it. They discovered ways to sense the chemical gradients in their environment and adjust their movements accordingly, either toward or away from the chemical source. This emergent behavior demonstrates the power of reinforcement learning, where complex behaviors can arise from simple rules and reward signals, without the need for detailed programming.
The researchers suggest this type of approach could be useful for developing autonomous systems that can adapt to their environment and learn new skills on their own, rather than relying on pre-programmed responses. It also provides insights into how natural organisms may have developed their own chemotactic abilities through evolutionary processes.
Technical Explanation
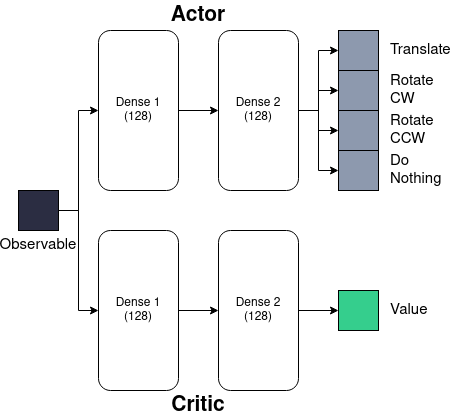
The paper presents a multi-agent reinforcement learning framework to study the emergence of chemotactic strategies. The researchers developed a simulation environment where a group of agents, represented as points in a 2D space, could sense and move in response to a simulated chemical gradient.
Each agent was equipped with sensors to detect the local chemical concentration and a set of possible actions (e.g., move left, right, up, down) that it could take. The agents were then trained using a reward-based reinforcement learning algorithm, where they received positive rewards for moving towards higher concentrations of the chemical and negative rewards for moving away.
Over the course of many training episodes, the agents were able to learn effective chemotactic behaviors without being explicitly programmed with that capability. The researchers analyzed the agents' learned strategies and found that they developed a variety of chemotactic approaches, including gradient climbing, spiral searching, and even collective behaviors.
The paper also explores how the number of agents, the complexity of the chemical gradient, and other environmental factors influenced the emergence and effectiveness of the learned chemotactic strategies. The results demonstrate the power of multi-agent reinforcement learning to give rise to complex adaptive behaviors in simulated environments.
Critical Analysis
The paper provides a compelling demonstration of how reinforcement learning can be used to develop chemotactic behaviors in a multi-agent system. The researchers have designed a well-structured simulation environment and reward structure that allows the agents to discover effective strategies through trial and error.
One potential limitation of the work is the simplicity of the agents and their environment. The agents are represented as simple points with limited sensing and movement capabilities, which may not fully capture the complexities of real-world chemotaxis in biological systems. Additionally, the chemical gradient used in the simulation is relatively straightforward, and it would be interesting to see how the agents would perform in more complex or dynamic environments.
Furthermore, the paper does not explore the scalability of this approach to larger, more diverse agent populations or more complicated tasks. It would be valuable to understand how the emergence of chemotactic strategies might be affected by factors such as agent heterogeneity, communication, or the presence of obstacles or predators.
Despite these potential limitations, the paper makes a significant contribution by showcasing the potential of multi-agent reinforcement learning to give rise to complex adaptive behaviors. The insights gained from this research could inform the development of more sophisticated autonomous systems and provide new perspectives on the evolution of chemotactic abilities in natural organisms.
Conclusion
This paper demonstrates the remarkable capacity of multi-agent reinforcement learning to enable the emergence of chemotactic behaviors in a simulated environment. By training a group of artificial agents to navigate chemical gradients, the researchers have shown how complex adaptive strategies can arise without explicit programming.
The findings suggest that reinforcement learning-based approaches could be a powerful tool for developing autonomous systems that can adapt to their environment and learn new skills on their own. Additionally, the insights gained from this work may shed light on the evolutionary processes that gave rise to chemotactic abilities in natural organisms.
While the current study has some limitations, it paves the way for further exploration of more complex multi-agent systems and their potential to uncover new forms of emergent behavior. As the field of artificial intelligence continues to advance, research like this will likely play an increasingly important role in our understanding of how complex intelligence can arise from simple rules and interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deep Dive into Model-free Reinforcement Learning for Biological and Robotic Systems: Theory and Practice
Yusheng Jiao, Feng Ling, Sina Heydari, Nicolas Heess, Josh Merel, Eva Kanso
0
0
Animals and robots exist in a physical world and must coordinate their bodies to achieve behavioral objectives. With recent developments in deep reinforcement learning, it is now possible for scientists and engineers to obtain sensorimotor strategies (policies) for specific tasks using physically simulated bodies and environments. However, the utility of these methods goes beyond the constraints of a specific task; they offer an exciting framework for understanding the organization of an animal sensorimotor system in connection to its morphology and physical interaction with the environment, as well as for deriving general design rules for sensing and actuation in robotic systems. Algorithms and code implementing both learning agents and environments are increasingly available, but the basic assumptions and choices that go into the formulation of an embodied feedback control problem using deep reinforcement learning may not be immediately apparent. Here, we present a concise exposition of the mathematical and algorithmic aspects of model-free reinforcement learning, specifically through the use of textit{actor-critic} methods, as a tool for investigating the feedback control underlying animal and robotic behavior.
5/21/2024

Locomotion Generation for a Rat Robot based on Environmental Changes via Reinforcement Learning
Xinhui Shan, Yuhong Huang, Zhenshan Bing, Zitao Zhang, Xiangtong Yao, Kai Huang, Alois Knoll
0
0
This research focuses on developing reinforcement learning approaches for the locomotion generation of small-size quadruped robots. The rat robot NeRmo is employed as the experimental platform. Due to the constrained volume, small-size quadruped robots typically possess fewer and weaker sensors, resulting in difficulty in accurately perceiving and responding to environmental changes. In this context, insufficient and imprecise feedback data from sensors makes it difficult to generate adaptive locomotion based on reinforcement learning. To overcome these challenges, this paper proposes a novel reinforcement learning approach that focuses on extracting effective perceptual information to enhance the environmental adaptability of small-size quadruped robots. According to the frequency of a robot's gait stride, key information of sensor data is analyzed utilizing sinusoidal functions derived from Fourier transform results. Additionally, a multifunctional reward mechanism is proposed to generate adaptive locomotion in different tasks. Extensive simulations are conducted to assess the effectiveness of the proposed reinforcement learning approach in generating rat robot locomotion in various environments. The experiment results illustrate the capability of the proposed approach to maintain stable locomotion of a rat robot across different terrains, including ramps, stairs, and spiral stairs.
4/16/2024
🎲
Q-Learning to navigate turbulence without a map
Marco Rando, Martin James, Alessandro Verri, Lorenzo Rosasco, Agnese Seminara
0
0
We consider the problem of olfactory searches in a turbulent environment. We focus on agents that respond solely to odor stimuli, with no access to spatial perception nor prior information about the odor location. We ask whether navigation strategies to a target can be learned robustly within a sequential decision making framework. We develop a reinforcement learning algorithm using a small set of interpretable olfactory states and train it with realistic turbulent odor cues. By introducing a temporal memory, we demonstrate that two salient features of odor traces, discretized in few olfactory states, are sufficient to learn navigation in a realistic odor plume. Performance is dictated by the sparse nature of turbulent plumes. An optimal memory exists which ignores blanks within the plume and activates a recovery strategy outside the plume. We obtain the best performance by letting agents learn their recovery strategy and show that it is mostly casting cross wind, similar to behavior observed in flying insects. The optimal strategy is robust to substantial changes in the odor plumes, suggesting minor parameter tuning may be sufficient to adapt to different environments.
4/29/2024

Physics-Informed Critic in an Actor-Critic Reinforcement Learning for Swimming in Turbulence
Christopher Koh, Laurent Pagnier, Michael Chertkov
0
0
Turbulent diffusion causes particles placed in proximity to separate. We investigate the required swimming efforts to maintain a particle close to its passively advected counterpart. We explore optimally balancing these efforts with the intended goal by developing and comparing a novel Physics-Informed Reinforcement Learning (PIRL) strategy with prescribed control (PC) and standard physics-agnostic Reinforcement Learning strategies. Our PIRL scheme, coined the Actor-Physicist, is an adaptation of the Actor-Critic algorithm in which the Neural Network parameterized Critic is replaced with an analytically derived physical heuristic function (the physicist). This strategy is then compared with an analytically computed optimal PC policy derived from a stochastic optimal control formulation and standard physics-agnostic Actor-Critic type algorithms.
6/18/2024