Pipeline Parallelism with Controllable Memory

0

Sign in to get full access
Overview
- This paper explores a technique called "Pipeline Parallelism with Controllable Memory" to improve the performance of deep neural network inference.
- The key idea is to break up the neural network computation into smaller stages that can be executed in parallel, while carefully managing the memory usage to avoid bottlenecks.
- The authors demonstrate the effectiveness of their approach on several real-world deep learning models and workloads.
Plain English Explanation
Deep neural networks have become incredibly powerful for a wide range of tasks, from image recognition to language understanding. However, as these models grow larger and more complex, running them efficiently on hardware can be a significant challenge.
The Pipeline Parallelism with Controllable Memory technique aims to address this by breaking up the neural network computation into smaller, independent stages that can be executed in parallel. This is similar to an assembly line, where each worker is responsible for a specific task rather than having to do the entire process themselves.
By partitioning the network in this way, the authors are able to better utilize the available hardware resources and avoid bottlenecks that can arise when trying to run the entire network at once. Importantly, they also introduce methods to carefully manage the memory usage at each stage, ensuring that the system doesn't run out of memory and become unusable.
Overall, this approach allows deep learning models to run much more efficiently, without sacrificing accuracy or performance. This could have significant implications for deploying powerful AI systems on a wide range of hardware, from powerful servers to resource-constrained edge devices.
Technical Explanation
The key technical contribution of the Pipeline Parallelism with Controllable Memory paper is a novel parallelization strategy for deep neural network inference.
The authors start by dividing the neural network into a series of stages, each of which performs a specific computational task. These stages are then executed in a pipelined fashion, with each stage working on a different input sample simultaneously. This allows for much more efficient utilization of the available hardware resources compared to executing the entire network sequentially.
To enable this pipeline parallelism, the authors introduce techniques to carefully manage the memory usage at each stage. This includes strategies for partitioning and offloading intermediate activations, as well as methods for dynamically adjusting the pipeline depth based on available memory. By controlling the memory footprint, the authors are able to avoid bottlenecks and ensure that the pipeline can run efficiently without running out of memory.
The authors evaluate their approach on a range of real-world deep learning models and workloads, including both computer vision and natural language processing tasks. They show significant performance improvements compared to both sequential execution and other parallelization strategies, such as USP: A Unified Sequence Parallelism Approach for Long Context and Efficient Multi-Processor Scheduling for Increasingly Realistic Models.
Critical Analysis
The Pipeline Parallelism with Controllable Memory paper presents a compelling and well-executed approach to improving the performance of deep neural network inference. The authors have clearly put a lot of thought into the system design and have demonstrated its effectiveness on a range of real-world tasks.
One potential limitation of the approach is that it may not be as effective for very small models or workloads, where the overhead of managing the pipeline and memory usage could outweigh the performance gains. Additionally, the authors note that their techniques work best for models with relatively independent computational stages, and may not be as effective for models with tightly coupled dependencies between layers.
That said, the authors do a good job of addressing these concerns and outlining potential avenues for future research. For example, they discuss ways to further optimize the memory usage and explore the trade-offs between pipeline depth, memory usage, and overall performance.
Overall, this paper represents an important contribution to the field of efficient deep learning inference, and the techniques it introduces could have significant real-world impact, especially for deploying powerful AI systems on resource-constrained edge devices or scaling up transformer-based models.
Conclusion
The Pipeline Parallelism with Controllable Memory paper presents a novel approach to improving the performance of deep neural network inference by leveraging pipeline parallelism and careful memory management.
The key insights and contributions of this work include:
- Partitioning the neural network computation into smaller, independent stages that can be executed in parallel
- Introducing techniques to control the memory usage at each stage of the pipeline to avoid bottlenecks
- Demonstrating significant performance improvements on a range of real-world deep learning models and workloads
Overall, this research represents an important step forward in the quest to deploy powerful AI systems efficiently on a wide range of hardware platforms, from powerful data centers to resource-constrained edge devices. As deep learning models continue to grow in size and complexity, techniques like those introduced in this paper will become increasingly crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pipeline Parallelism with Controllable Memory
Penghui Qi, Xinyi Wan, Nyamdavaa Amar, Min Lin
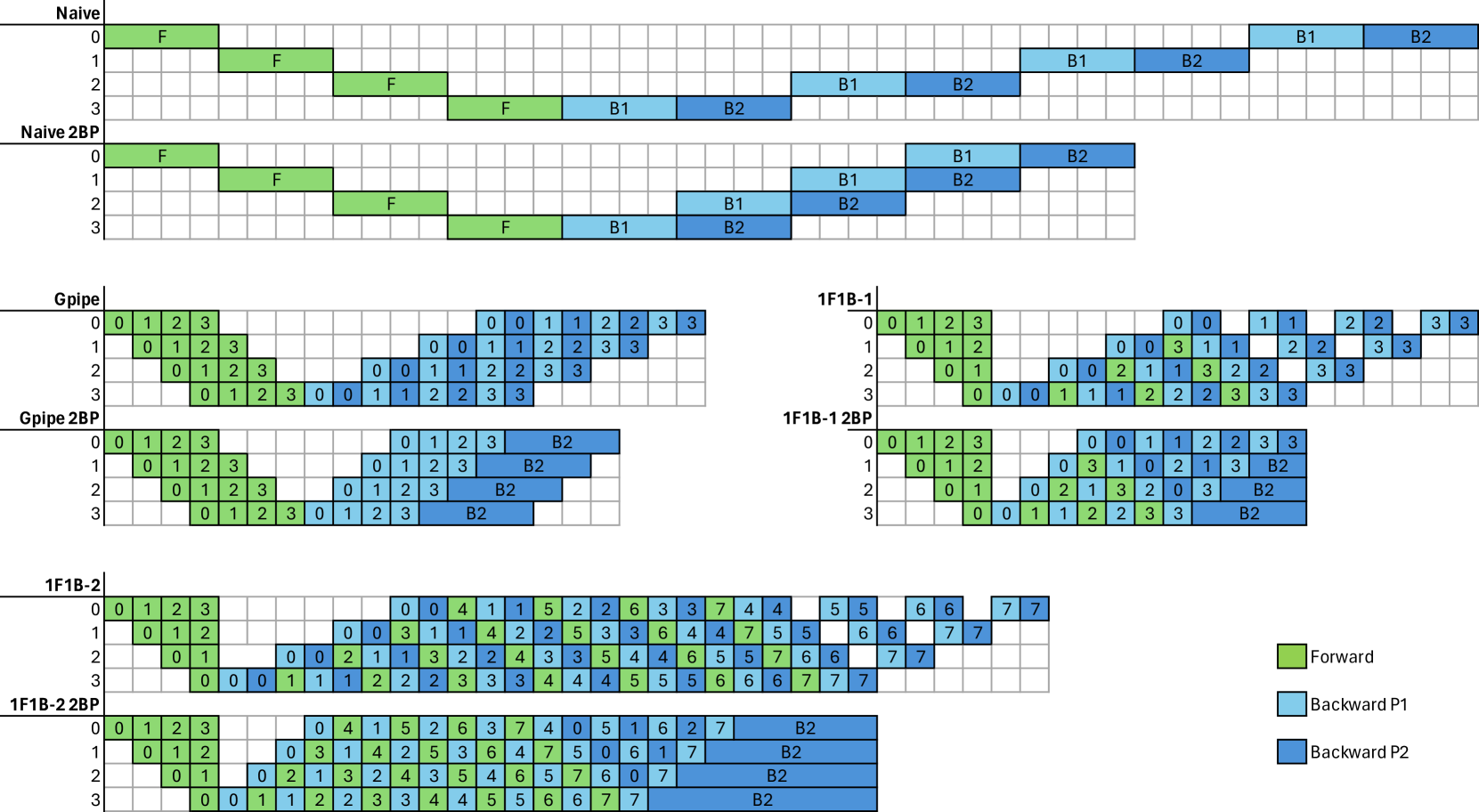
Pipeline parallelism has been widely explored, but most existing schedules lack a systematic methodology. In this paper, we propose a framework to decompose pipeline schedules as repeating a building block and we show that the lifespan of the building block decides the peak activation memory of the pipeline schedule. Guided by the observations, we find that almost all existing pipeline schedules, to the best of our knowledge, are memory inefficient. To address this, we introduce a family of memory efficient building blocks with controllable activation memory, which can reduce the peak activation memory to 1/2 of 1F1B without sacrificing efficiency, and even to 1/3 with comparable throughput. We can also achieve almost zero pipeline bubbles while maintaining the same activation memory as 1F1B. Our evaluations demonstrate that in pure pipeline parallelism settings, our methods outperform 1F1B by from 7% to 55% in terms of throughput. When employing a grid search over hybrid parallelism hyperparameters in practical scenarios, our proposed methods demonstrate a 16% throughput improvement over the 1F1B baseline for large language models.
Read more6/11/2024

0
Seq1F1B: Efficient Sequence-Level Pipeline Parallelism for Large Language Model Training
Ao Sun, Weilin Zhao, Xu Han, Cheng Yang, Xinrong Zhang, Zhiyuan Liu, Chuan Shi, Maosong Sun
The emergence of large language models (LLMs) relies heavily on distributed training strategies, among which pipeline parallelism plays a crucial role. As LLMs' training sequence length extends to 32k or even 128k, the current pipeline parallel methods face severe bottlenecks, including high memory footprints and substantial pipeline bubbles, greatly hindering model scalability and training throughput. To enhance memory efficiency and training throughput, in this work, we introduce an efficient sequence-level one-forward-one-backward (1F1B) pipeline scheduling method tailored for training LLMs on long sequences named Seq1F1B. Seq1F1B decomposes batch-level schedulable units into finer sequence-level units, reducing bubble size and memory footprint. Considering that Seq1F1B may produce slight extra bubbles if sequences are split evenly, we design a computation-wise strategy to partition input sequences and mitigate this side effect. Compared to competitive pipeline baseline methods such as Megatron 1F1B pipeline parallelism, our method achieves higher training throughput with less memory footprint. Notably, Seq1F1B efficiently trains a LLM with 30B parameters on sequences up to 64k using 64 NVIDIA A100 GPUs without recomputation strategies, a feat unachievable with existing methods. Our source code is based on Megatron-LM, and now is avaiable at: https://github.com/MayDomine/Seq1F1B.git.
Read more9/10/2024

0
Hermes: Memory-Efficient Pipeline Inference for Large Models on Edge Devices
Xueyuan Han, Zinuo Cai, Yichu Zhang, Chongxin Fan, Junhan Liu, Ruhui Ma, Rajkumar Buyya
The application of Transformer-based large models has achieved numerous success in recent years. However, the exponential growth in the parameters of large models introduces formidable memory challenge for edge deployment. Prior works to address this challenge mainly focus on optimizing the model structure and adopting memory swapping methods. However, the former reduces the inference accuracy, and the latter raises the inference latency. This paper introduces PIPELOAD, a novel memory-efficient pipeline execution mechanism. It reduces memory usage by incorporating dynamic memory management and minimizes inference latency by employing parallel model loading. Based on PIPELOAD mechanism, we present Hermes, a framework optimized for large model inference on edge devices. We evaluate Hermes on Transformer-based models of different sizes. Our experiments illustrate that Hermes achieves up to 4.24 X increase in inference speed and 86.7% lower memory consumption than the state-of-the-art pipeline mechanism for BERT and ViT models, 2.58 X increase in inference speed and 90.3% lower memory consumption for GPT-style models.
Read more9/11/2024
0
2BP: 2-Stage Backpropagation
Christopher Rae, Joseph K. L. Lee, James Richings
As Deep Neural Networks (DNNs) grow in size and complexity, they often exceed the memory capacity of a single accelerator, necessitating the sharding of model parameters across multiple accelerators. Pipeline parallelism is a commonly used sharding strategy for training large DNNs. However, current implementations of pipeline parallelism are being unintentionally bottlenecked by the automatic differentiation tools provided by ML frameworks. This paper introduces 2-stage backpropagation (2BP). By splitting the backward propagation step into two separate stages, we can reduce idle compute time. We tested 2BP on various model architectures and pipelining schedules, achieving increases in throughput in all cases. Using 2BP, we were able to achieve a 1.70x increase in throughput compared to traditional methods when training a LLaMa-like transformer with 7 billion parameters across 4 GPUs.
Read more5/29/2024