2BP: 2-Stage Backpropagation

0
Sign in to get full access
Overview
- Introduces a novel two-stage backpropagation algorithm called 2BP to improve the training efficiency of neural networks
- Leverages a "coarse-to-fine" approach to training, first learning a coarse model and then refining it in a second stage
- Claims 2BP can achieve better performance than standard backpropagation while requiring less computation
Plain English Explanation
2-Stage Backpropagation (2BP) is a new technique for training neural networks that aims to improve efficiency and performance compared to traditional backpropagation. The key idea is to use a "coarse-to-fine" approach, where the network first learns a rough, high-level model in an initial stage, and then refines that model in a second stage of more detailed training.
The motivation behind this is that the standard backpropagation algorithm can sometimes get stuck in suboptimal regions of the optimization landscape, especially when the network is large and complex. By breaking the training into two stages, 2BP hopes to overcome this challenge and find a better final model.
In the first stage, 2BP trains a coarse version of the network using a simplified loss function and lower computational resources. This gives the model a general sense of the problem and the structure it needs to solve it. Then in the second stage, the coarse model is used as a starting point for fine-tuning with the full loss function and more intensive training.
The authors claim this approach allows 2BP to achieve higher accuracy and faster convergence compared to regular backpropagation, without requiring significantly more computational power. This makes it a potentially valuable tool for training large, high-performance neural networks more efficiently.
Technical Explanation
The 2-Stage Backpropagation (2BP) algorithm proposed in this paper consists of two main phases:
-
Coarse Training Stage: In this initial stage, the network is trained using a simplified or "coarse" version of the original loss function. This could involve reducing the dimensionality of the inputs, using a smaller network architecture, or making other simplifications to make the optimization problem easier. The goal is to obtain a rough, high-level model of the target function.
-
Fine-Tuning Stage: The coarse model learned in the first stage is then used as the starting point for a second, more detailed training phase. Here, the full original loss function is used, and the network is trained to refine and improve the coarse model.
The authors hypothesize that this two-stage approach can help neural networks escape local minima that standard backpropagation might get stuck in. By first learning a coarse, high-level model, the optimization process is guided towards a more promising region of the parameter space, which can then be further refined in the second stage.
The paper presents several experiments evaluating 2BP on various benchmark datasets and neural network architectures. The results indicate that 2BP can indeed outperform standard backpropagation in terms of both final accuracy and training efficiency, requiring fewer iterations and less computation to reach the same performance level.
Critical Analysis
The 2BP approach presented in this paper is an interesting and potentially valuable contribution to the field of neural network optimization. By decomposing the training process into coarse and fine-grained stages, the authors demonstrate a way to potentially overcome some of the limitations of standard backpropagation.
However, the paper does not provide a comprehensive analysis of the underlying mechanisms that allow 2BP to outperform regular backpropagation. More theoretical work may be needed to fully understand the conditions under which 2BP is most effective and the reasons for its improved performance.
Additionally, the paper focuses on relatively simple benchmark tasks and network architectures. It would be valuable to see how 2BP scales and performs on larger, more complex real-world problems and state-of-the-art neural network models. Exploring the sensitivity of 2BP to hyperparameter choices and the specifics of the coarse and fine-tuning stages would also be useful.
Overall, this paper presents a promising new approach to training neural networks more efficiently. Further research and experimentation will be needed to fully assess the capabilities and limitations of 2BP and understand how it can best be applied in practice.
Conclusion
The 2-Stage Backpropagation (2BP) algorithm introduced in this paper offers a novel approach to training neural networks more efficiently. By breaking the training process into a coarse, high-level stage followed by a fine-tuning stage, 2BP aims to help neural networks escape local minima and achieve better performance compared to standard backpropagation.
The experimental results presented in the paper are encouraging, showing that 2BP can outperform regular backpropagation in terms of both final accuracy and training efficiency. This suggests 2BP could be a valuable tool for training large, high-performance neural networks more effectively.
While more research is needed to fully understand the underlying mechanisms and limitations of 2BP, this paper represents an important contribution to the ongoing efforts to improve the training and optimization of deep learning models. As the field of AI continues to advance, techniques like 2BP that enhance the efficiency and effectiveness of neural network training will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
2BP: 2-Stage Backpropagation
Christopher Rae, Joseph K. L. Lee, James Richings
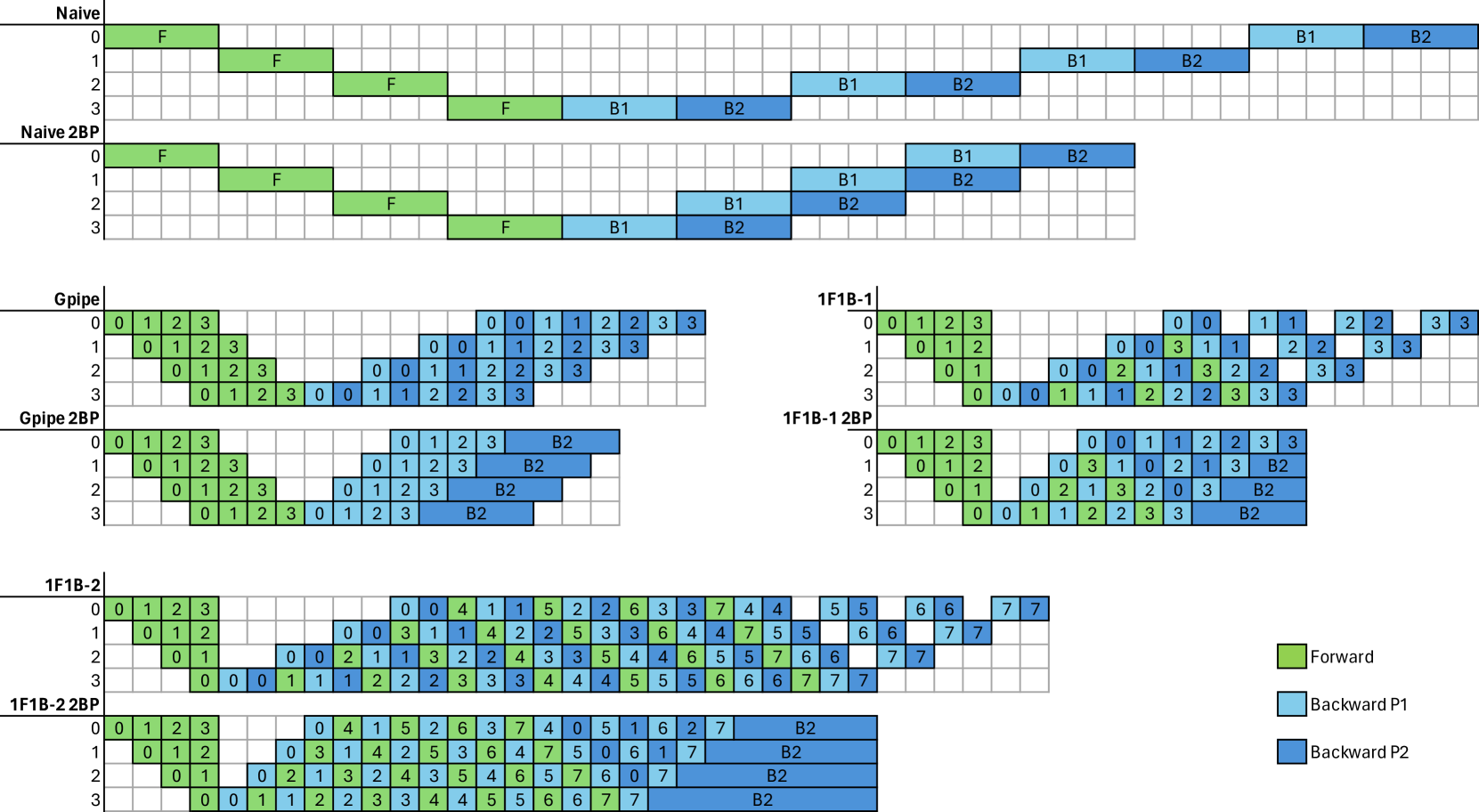
As Deep Neural Networks (DNNs) grow in size and complexity, they often exceed the memory capacity of a single accelerator, necessitating the sharding of model parameters across multiple accelerators. Pipeline parallelism is a commonly used sharding strategy for training large DNNs. However, current implementations of pipeline parallelism are being unintentionally bottlenecked by the automatic differentiation tools provided by ML frameworks. This paper introduces 2-stage backpropagation (2BP). By splitting the backward propagation step into two separate stages, we can reduce idle compute time. We tested 2BP on various model architectures and pipelining schedules, achieving increases in throughput in all cases. Using 2BP, we were able to achieve a 1.70x increase in throughput compared to traditional methods when training a LLaMa-like transformer with 7 billion parameters across 4 GPUs.
Read more5/29/2024
🤿
0
Effective Learning with Node Perturbation in Deep Neural Networks
Sander Dalm, Marcel van Gerven, Nasir Ahmad
Backpropagation (BP) remains the dominant and most successful method for training parameters of deep neural network models. However, BP relies on two computationally distinct phases, does not provide a satisfactory explanation of biological learning, and can be challenging to apply for training of networks with discontinuities or noisy node dynamics. By comparison, node perturbation (NP) proposes learning by the injection of noise into network activations, and subsequent measurement of the induced loss change. NP relies on two forward (inference) passes, does not make use of network derivatives, and has been proposed as a model for learning in biological systems. However, standard NP is highly data inefficient and unstable due to its unguided noise-based search process. In this work, we investigate different formulations of NP and relate it to the concept of directional derivatives as well as combining it with a decorrelating mechanism for layer-wise inputs. We find that a closer alignment with directional derivatives together with input decorrelation at every layer strongly enhances performance of NP learning with large improvements in parameter convergence and much higher performance on the test data, approaching that of BP. Furthermore, our novel formulation allows for application to noisy systems in which the noise process itself is inaccessible.
Read more5/28/2024

0
ssProp: Energy-Efficient Training for Convolutional Neural Networks with Scheduled Sparse Back Propagation
Lujia Zhong, Shuo Huang, Yonggang Shi
Recently, deep learning has made remarkable strides, especially with generative modeling, such as large language models and probabilistic diffusion models. However, training these models often involves significant computational resources, requiring billions of petaFLOPs. This high resource consumption results in substantial energy usage and a large carbon footprint, raising critical environmental concerns. Back-propagation (BP) is a major source of computational expense during training deep learning models. To advance research on energy-efficient training and allow for sparse learning on any machine and device, we propose a general, energy-efficient convolution module that can be seamlessly integrated into any deep learning architecture. Specifically, we introduce channel-wise sparsity with additional gradient selection schedulers during backward based on the assumption that BP is often dense and inefficient, which can lead to over-fitting and high computational consumption. Our experiments demonstrate that our approach reduces 40% computations while potentially improving model performance, validated on image classification and generation tasks. This reduction can lead to significant energy savings and a lower carbon footprint during the research and development phases of large-scale AI systems. Additionally, our method mitigates over-fitting in a manner distinct from Dropout, allowing it to be combined with Dropout to further enhance model performance and reduce computational resource usage. Extensive experiments validate that our method generalizes to a variety of datasets and tasks and is compatible with a wide range of deep learning architectures and modules. Code is publicly available at https://github.com/lujiazho/ssProp.
Read more8/23/2024
0
Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
Yuchen Yang, Yingdong Shi, Cheems Wang, Xiantong Zhen, Yuxuan Shi, Jun Xu
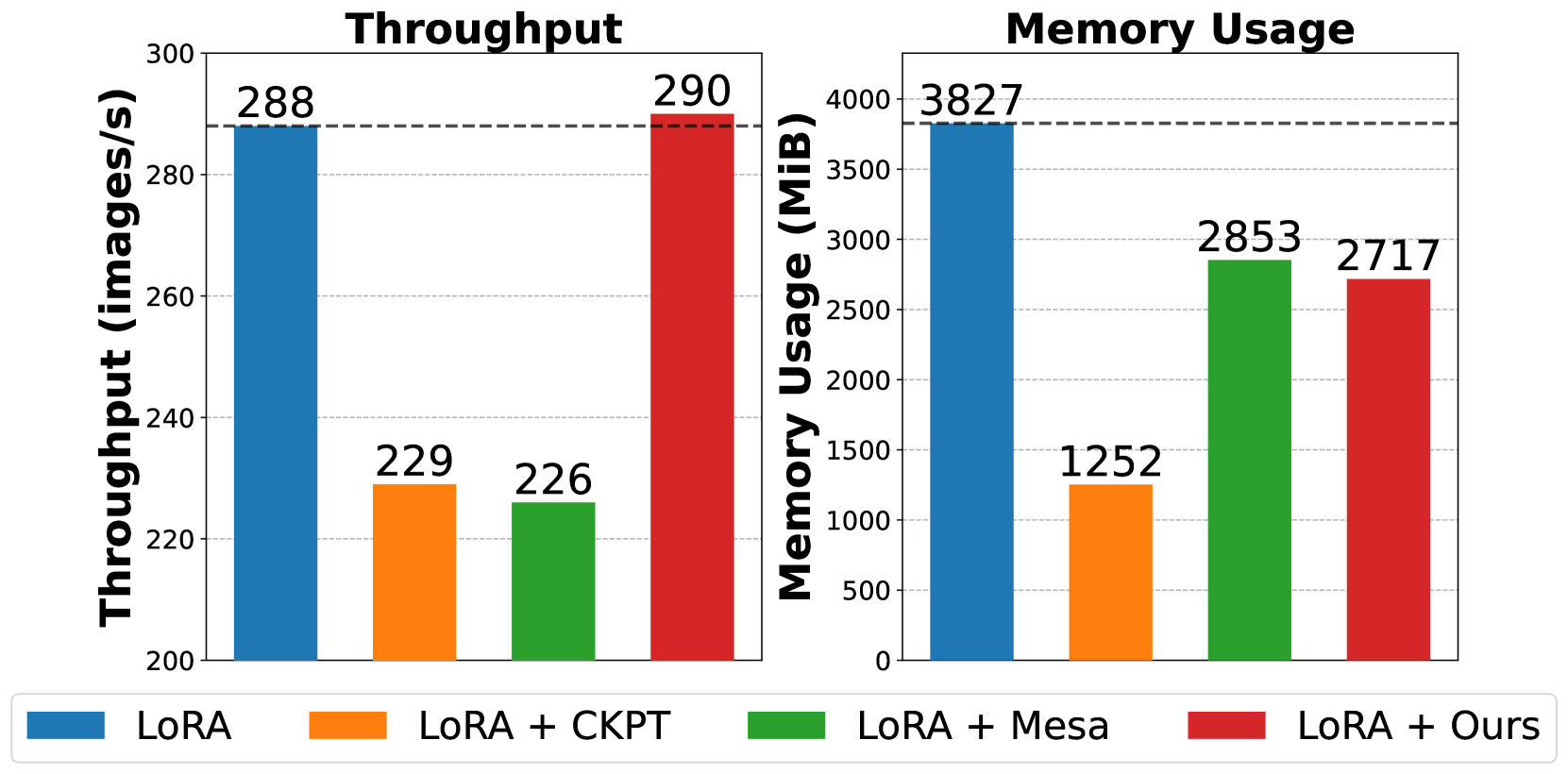
Fine-tuning pretrained large models to downstream tasks is an important problem, which however suffers from huge memory overhead due to large-scale parameters. This work strives to reduce memory overhead in fine-tuning from perspectives of activation function and layer normalization. To this end, we propose the Approximate Backpropagation (Approx-BP) theory, which provides the theoretical feasibility of decoupling the forward and backward passes. We apply our Approx-BP theory to backpropagation training and derive memory-efficient alternatives of GELU and SiLU activation functions, which use derivative functions of ReLUs in the backward pass while keeping their forward pass unchanged. In addition, we introduce a Memory-Sharing Backpropagation strategy, which enables the activation memory to be shared by two adjacent layers, thereby removing activation memory usage redundancy. Our method neither induces extra computation nor reduces training efficiency. We conduct extensive experiments with pretrained vision and language models, and the results demonstrate that our proposal can reduce up to $sim$$30%$ of the peak memory usage. Our code is released at https://github.com/yyyyychen/LowMemoryBP.
Read more6/26/2024