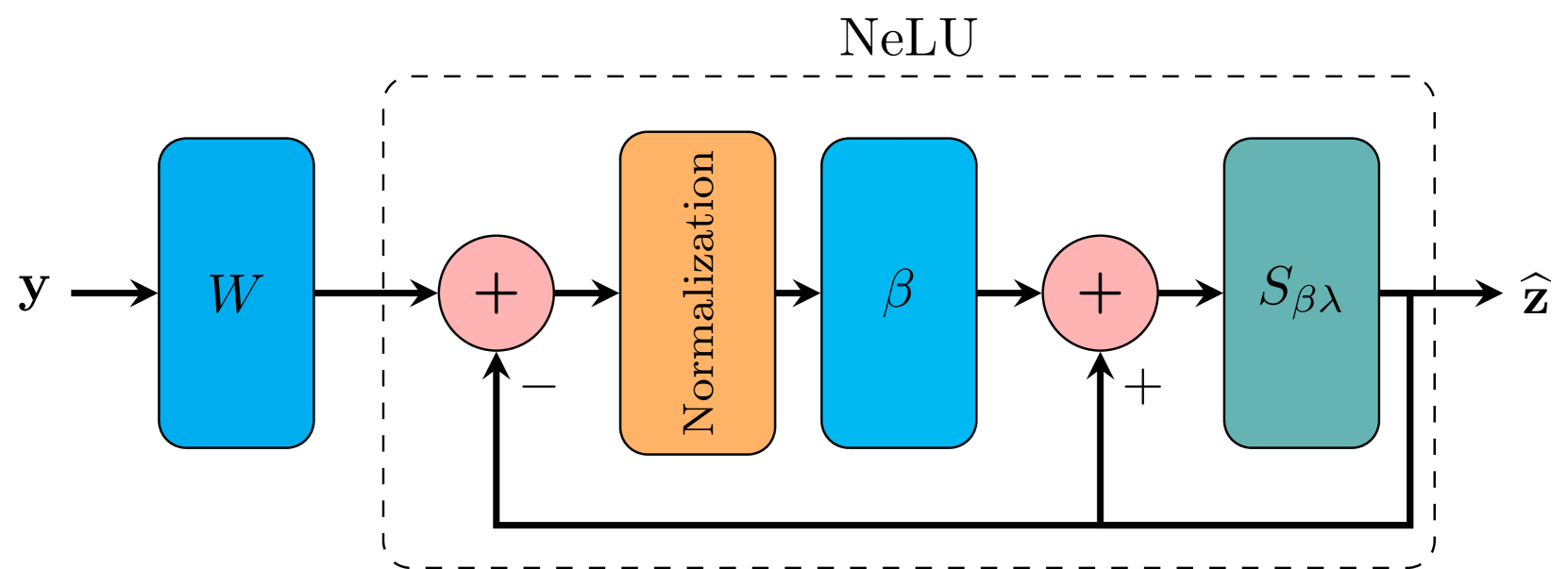
Pivotal Auto-Encoder via Self-Normalizing ReLU

0
Sign in to get full access
Overview
- This paper introduces a new auto-encoder architecture called the Pivotal Auto-Encoder (PAE) that uses a self-normalizing activation function to improve the performance of sparse auto-encoders.
- The key contributions include a novel training algorithm that leverages the self-normalizing properties of the ReLU activation function, as well as a theoretical analysis of the proposed method.
- The authors demonstrate the effectiveness of PAE on a range of benchmark tasks, showing improvements over standard sparse auto-encoder approaches.
Plain English Explanation
The paper describes a new type of auto-encoder called a Pivotal Auto-Encoder (PAE) that is designed to work better than existing sparse auto-encoder models. Auto-encoders are a type of neural network that can learn to compress and decompress data efficiently, with applications in areas like image compression and feature extraction.
The key innovation in PAE is the use of a "self-normalizing" activation function, which helps stabilize the training process and allows the model to learn better representations of the input data. This is especially important for sparse auto-encoders, which aim to learn a compact, sparse encoding of the input.
The authors show that PAE outperforms standard sparse auto-encoder approaches on several benchmark tasks, demonstrating the benefits of their self-normalizing activation function and training algorithm. This suggests that PAE could be a useful tool for applications that require efficient data representation, such as scientific data compression or reliable circuit identification.
Technical Explanation
The authors propose a new auto-encoder architecture called the Pivotal Auto-Encoder (PAE) that leverages the self-normalizing properties of the ReLU activation function to improve the performance of sparse auto-encoders. Sparse auto-encoders are a class of auto-encoders that aim to learn a compressed, sparse representation of the input data.
The key innovations in PAE are:
- A novel training algorithm that exploits the self-normalizing properties of the ReLU activation function to stabilize the training process and improve the quality of the learned representations.
- A theoretical analysis that provides insights into the properties of the learned representations and the convergence of the training algorithm.
The authors evaluate PAE on a range of benchmark tasks, including image reconstruction and feature extraction, and show that it outperforms standard sparse auto-encoder approaches. This suggests that the self-normalizing properties of the ReLU activation function can be effectively leveraged to improve the performance of sparse auto-encoders, with potential applications in areas like scientific data compression and reliable circuit identification.
Critical Analysis
The authors provide a thorough theoretical analysis of the PAE architecture and its training algorithm, which is a strength of the paper. However, the practical implications of the proposed method are not fully explored. While the authors demonstrate improved performance on benchmark tasks, it would be helpful to see more discussion of the potential real-world applications and limitations of PAE.
Additionally, the paper does not address potential issues with the scalability or robustness of PAE, such as its performance on larger or more complex datasets, or its sensitivity to hyperparameter choices. Exploring these aspects could help provide a more comprehensive understanding of the method's strengths and weaknesses.
It would also be valuable to see how PAE compares to other recent advancements in sparse auto-encoder and transform learning approaches. A more thorough comparative analysis could help position PAE within the broader context of the field and identify its unique contributions.
Conclusion
The Pivotal Auto-Encoder (PAE) proposed in this paper represents an interesting advance in the field of sparse auto-encoders. By leveraging the self-normalizing properties of the ReLU activation function, the authors have developed a training algorithm that can learn more effective sparse representations of input data.
The theoretical analysis and empirical results presented in the paper suggest that PAE could be a useful tool for applications that require efficient data representation, such as scientific data compression or reliable circuit identification. However, further research is needed to fully understand the practical implications and limitations of the method, as well as how it compares to other state-of-the-art approaches in transform learning and sparse auto-encoders.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pivotal Auto-Encoder via Self-Normalizing ReLU
Nelson Goldenstein, Jeremias Sulam, Yaniv Romano
Sparse auto-encoders are useful for extracting low-dimensional representations from high-dimensional data. However, their performance degrades sharply when the input noise at test time differs from the noise employed during training. This limitation hinders the applicability of auto-encoders in real-world scenarios where the level of noise in the input is unpredictable. In this paper, we formalize single hidden layer sparse auto-encoders as a transform learning problem. Leveraging the transform modeling interpretation, we propose an optimization problem that leads to a predictive model invariant to the noise level at test time. In other words, the same pre-trained model is able to generalize to different noise levels. The proposed optimization algorithm, derived from the square root lasso, is translated into a new, computationally efficient auto-encoding architecture. After proving that our new method is invariant to the noise level, we evaluate our approach by training networks using the proposed architecture for denoising tasks. Our experimental results demonstrate that the trained models yield a significant improvement in stability against varying types of noise compared to commonly used architectures.
Read more6/26/2024
0
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr'e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, Jeffrey Wu
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very large to recover all relevant features. However, studying the properties of autoencoder scaling is difficult due to the need to balance reconstruction and sparsity objectives and the presence of dead latents. We propose using k-sparse autoencoders [Makhzani and Frey, 2013] to directly control sparsity, simplifying tuning and improving the reconstruction-sparsity frontier. Additionally, we find modifications that result in few dead latents, even at the largest scales we tried. Using these techniques, we find clean scaling laws with respect to autoencoder size and sparsity. We also introduce several new metrics for evaluating feature quality based on the recovery of hypothesized features, the explainability of activation patterns, and the sparsity of downstream effects. These metrics all generally improve with autoencoder size. To demonstrate the scalability of our approach, we train a 16 million latent autoencoder on GPT-4 activations for 40 billion tokens. We release training code and autoencoders for open-source models, as well as a visualizer.
Read more6/7/2024
📊
0
Sparse $L^1$-Autoencoders for Scientific Data Compression
Matthias Chung, Rick Archibald, Paul Atzberger, Jack Michael Solomon
Scientific datasets present unique challenges for machine learning-driven compression methods, including more stringent requirements on accuracy and mitigation of potential invalidating artifacts. Drawing on results from compressed sensing and rate-distortion theory, we introduce effective data compression methods by developing autoencoders using high dimensional latent spaces that are $L^1$-regularized to obtain sparse low dimensional representations. We show how these information-rich latent spaces can be used to mitigate blurring and other artifacts to obtain highly effective data compression methods for scientific data. We demonstrate our methods for short angle scattering (SAS) datasets showing they can achieve compression ratios around two orders of magnitude and in some cases better. Our compression methods show promise for use in addressing current bottlenecks in transmission, storage, and analysis in high-performance distributed computing environments. This is central to processing the large volume of SAS data being generated at shared experimental facilities around the world to support scientific investigations. Our approaches provide general ways for obtaining specialized compression methods for targeted scientific datasets.
Read more5/24/2024
💬
0
Sparse Autoencoders Enable Scalable and Reliable Circuit Identification in Language Models
Charles O'Neill, Thang Bui
This paper introduces an efficient and robust method for discovering interpretable circuits in large language models using discrete sparse autoencoders. Our approach addresses key limitations of existing techniques, namely computational complexity and sensitivity to hyperparameters. We propose training sparse autoencoders on carefully designed positive and negative examples, where the model can only correctly predict the next token for the positive examples. We hypothesise that learned representations of attention head outputs will signal when a head is engaged in specific computations. By discretising the learned representations into integer codes and measuring the overlap between codes unique to positive examples for each head, we enable direct identification of attention heads involved in circuits without the need for expensive ablations or architectural modifications. On three well-studied tasks - indirect object identification, greater-than comparisons, and docstring completion - the proposed method achieves higher precision and recall in recovering ground-truth circuits compared to state-of-the-art baselines, while reducing runtime from hours to seconds. Notably, we require only 5-10 text examples for each task to learn robust representations. Our findings highlight the promise of discrete sparse autoencoders for scalable and efficient mechanistic interpretability, offering a new direction for analysing the inner workings of large language models.
Read more5/22/2024