Improving Dictionary Learning with Gated Sparse Autoencoders

0
Sign in to get full access
Overview
- This paper introduces a new approach called Gated Sparse Autoencoders (GSAEs) to improve dictionary learning, which is a technique used in various machine learning applications.
- The key idea is to incorporate gating mechanisms into sparse autoencoders to better control the sparsity of the learned representations, leading to more efficient and effective dictionary learning.
- The proposed method is evaluated on several benchmark datasets and shows superior performance compared to traditional sparse autoencoder-based dictionary learning approaches.
Plain English Explanation
Dictionaries are an important part of many machine learning models, as they help represent complex data in a more compact and meaningful way. Improving Dictionary Learning with Gated Sparse Autoencoders introduces a new method called Gated Sparse Autoencoders (GSAEs) to learn these dictionaries more effectively.
The key insight is to use a special type of neural network called a "sparse autoencoder" to learn the dictionary. Sparse autoencoders are able to find a compact representation of the input data by only activating a small number of the neurons in the network. The authors take this idea further by adding "gating" mechanisms that allow the network to better control the sparsity of the learned representations.
This improved control over sparsity leads to dictionaries that are more efficient and effective at representing the original data. The authors demonstrate the benefits of their approach on several common benchmark datasets, showing that GSAEs outperform traditional sparse autoencoder-based dictionary learning methods.
In summary, this work provides a new tool for learning more powerful dictionaries, which are a fundamental building block of many machine learning systems. By incorporating gating mechanisms, the authors are able to extract more meaningful representations from data, which could have applications in areas like computer vision, natural language processing, and beyond.
Technical Explanation
The paper introduces a new approach called Gated Sparse Autoencoders (GSAEs) to improve dictionary learning, a common technique used in machine learning to find compact representations of data.
The baseline architecture for a sparse autoencoder consists of an encoder network that maps the input data to a sparse latent representation, and a decoder network that reconstructs the original input from this sparse code. The authors build on this by incorporating gating mechanisms into the encoder, allowing the network to better control the sparsity of the learned representations.
Specifically, the encoder in a GSAE has two pathways: one that generates the sparse code, and another that produces a set of gating weights. These gating weights are then used to modulate the activations in the sparse code, effectively turning some of them on or off. This gating mechanism provides the network with more flexibility in shaping the sparsity pattern of the learned dictionary elements.
The authors evaluate their proposed GSAE approach on several benchmark datasets, including image patches and audio spectrograms. They show that GSAEs consistently outperform traditional sparse autoencoder-based dictionary learning methods in terms of reconstruction quality and the efficiency of the learned dictionaries.
Critical Analysis
The paper makes a compelling case for the benefits of incorporating gating mechanisms into sparse autoencoders for dictionary learning. The authors provide a clear technical explanation of their approach and demonstrate its effectiveness on multiple datasets.
One potential limitation of the work is that it only evaluates the performance of GSAEs on relatively small-scale datasets. It would be interesting to see how the method scales to larger, more complex datasets that are more representative of real-world machine learning problems. Additionally, the authors do not provide much insight into the interpretability or explainability of the learned dictionaries, which could be an important consideration in some applications.
Another area for further research could be to explore the integration of Emergent Language in Symbolic Autoencoders (ELSA) or Masked Autoencoders for Microscopy into the GSAE framework, which could lead to even more powerful and versatile dictionary learning capabilities.
Overall, this paper presents a promising new approach to dictionary learning that could have significant implications for a wide range of machine learning applications. The authors have clearly demonstrated the potential benefits of their method, and further research in this direction could lead to even more significant advancements in the field.
Conclusion
Improving Dictionary Learning with Gated Sparse Autoencoders introduces a novel method called Gated Sparse Autoencoders (GSAEs) that enhances the ability of sparse autoencoders to learn efficient and effective dictionaries. By incorporating gating mechanisms into the encoder network, the authors show that GSAEs can learn sparser and more meaningful representations of data, leading to improved performance on various benchmark tasks.
This work contributes to the ongoing efforts to develop more powerful and versatile dictionary learning techniques, which are crucial for a wide range of machine learning applications, from computer vision to natural language processing. The authors' approach of leveraging gating mechanisms to control sparsity could inspire further innovations in this area, potentially leading to even more efficient and explainable dictionary learning methods in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, J'anos Kram'ar, Rohin Shah, Neel Nanda
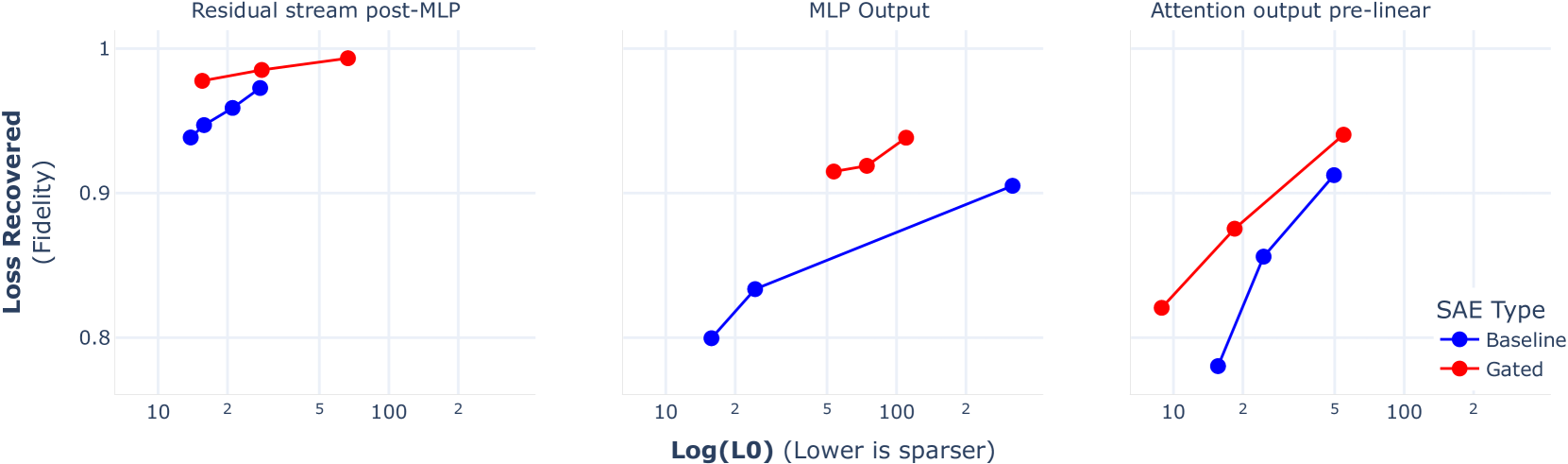
Recent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of LM activations. We introduce the Gated Sparse Autoencoder (Gated SAE), which achieves a Pareto improvement over training with prevailing methods. In SAEs, the L1 penalty used to encourage sparsity introduces many undesirable biases, such as shrinkage -- systematic underestimation of feature activations. The key insight of Gated SAEs is to separate the functionality of (a) determining which directions to use and (b) estimating the magnitudes of those directions: this enables us to apply the L1 penalty only to the former, limiting the scope of undesirable side effects. Through training SAEs on LMs of up to 7B parameters we find that, in typical hyper-parameter ranges, Gated SAEs solve shrinkage, are similarly interpretable, and require half as many firing features to achieve comparable reconstruction fidelity.
Read more5/1/2024

0
Disentangling Dense Embeddings with Sparse Autoencoders
Charles O'Neill, Christine Ye, Kartheik Iyer, John F. Wu
Sparse autoencoders (SAEs) have shown promise in extracting interpretable features from complex neural networks. We present one of the first applications of SAEs to dense text embeddings from large language models, demonstrating their effectiveness in disentangling semantic concepts. By training SAEs on embeddings of over 420,000 scientific paper abstracts from computer science and astronomy, we show that the resulting sparse representations maintain semantic fidelity while offering interpretability. We analyse these learned features, exploring their behaviour across different model capacities and introducing a novel method for identifying ``feature families'' that represent related concepts at varying levels of abstraction. To demonstrate the practical utility of our approach, we show how these interpretable features can be used to precisely steer semantic search, allowing for fine-grained control over query semantics. This work bridges the gap between the semantic richness of dense embeddings and the interpretability of sparse representations. We open source our embeddings, trained sparse autoencoders, and interpreted features, as well as a web app for exploring them.
Read more8/2/2024
0
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr'e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, Jeffrey Wu
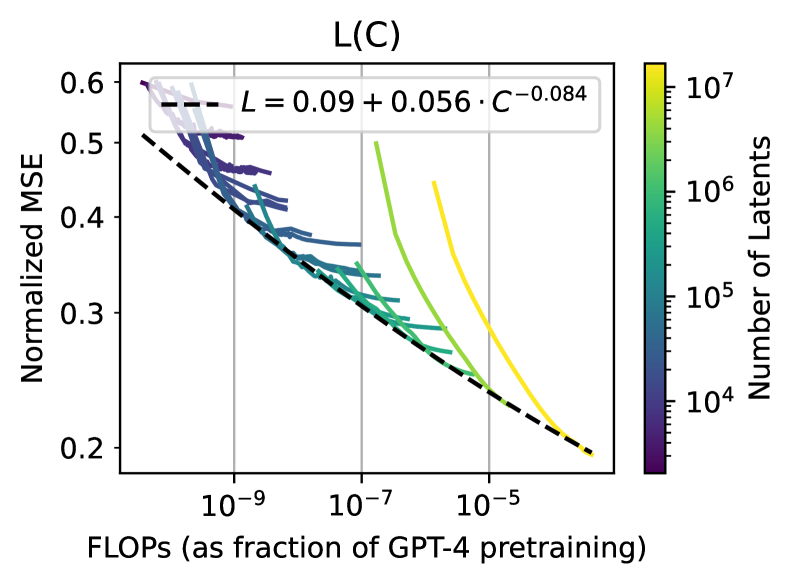
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very large to recover all relevant features. However, studying the properties of autoencoder scaling is difficult due to the need to balance reconstruction and sparsity objectives and the presence of dead latents. We propose using k-sparse autoencoders [Makhzani and Frey, 2013] to directly control sparsity, simplifying tuning and improving the reconstruction-sparsity frontier. Additionally, we find modifications that result in few dead latents, even at the largest scales we tried. Using these techniques, we find clean scaling laws with respect to autoencoder size and sparsity. We also introduce several new metrics for evaluating feature quality based on the recovery of hypothesized features, the explainability of activation patterns, and the sparsity of downstream effects. These metrics all generally improve with autoencoder size. To demonstrate the scalability of our approach, we train a 16 million latent autoencoder on GPT-4 activations for 40 billion tokens. We release training code and autoencoders for open-source models, as well as a visualizer.
Read more6/7/2024

0
Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small
Maheep Chaudhary, Atticus Geiger
A popular new method in mechanistic interpretability is to train high-dimensional sparse autoencoders (SAEs) on neuron activations and use SAE features as the atomic units of analysis. However, the body of evidence on whether SAE feature spaces are useful for causal analysis is underdeveloped. In this work, we use the RAVEL benchmark to evaluate whether SAEs trained on hidden representations of GPT-2 small have sets of features that separately mediate knowledge of which country a city is in and which continent it is in. We evaluate four open-source SAEs for GPT-2 small against each other, with neurons serving as a baseline, and linear features learned via distributed alignment search (DAS) serving as a skyline. For each, we learn a binary mask to select features that will be patched to change the country of a city without changing the continent, or vice versa. Our results show that SAEs struggle to reach the neuron baseline, and none come close to the DAS skyline. We release code here: https://github.com/MaheepChaudhary/SAE-Ravel
Read more9/10/2024