Pixel Is Not A Barrier: An Effective Evasion Attack for Pixel-Domain Diffusion Models

0

Sign in to get full access
Overview
- Presents an effective evasion attack against pixel-domain diffusion models
- Demonstrates that diffusion models can be fooled despite their high performance on standard benchmarks
- Highlights the need for comprehensive security evaluations of diffusion models beyond standard benchmarks
Plain English Explanation
Diffusion models are a type of machine learning model that have shown impressive performance on various tasks, such as image generation and text-to-image synthesis. However, this paper shows that these models can be vulnerable to evasion attacks, where an attacker can create inputs that the model will misclassify or fail to recognize.
The researchers developed a technique that can fool diffusion models by making small, imperceptible changes to the input image. Even though these changes are barely noticeable to the human eye, they're enough to trick the model into failing to recognize the original image. This highlights a weakness in the security of diffusion models, as they may not be as robust as previously thought.
The paper emphasizes the importance of testing the security of these models beyond just standard benchmarks, which may not capture all potential vulnerabilities. By understanding the limitations and weaknesses of diffusion models, researchers and developers can work to improve their robustness and make them more secure against different types of attacks.
Technical Explanation
The paper proposes an evasion attack that can fool pixel-domain diffusion models, which are a type of generative model that works by gradually transforming a random noise input into a realistic-looking image.
The key idea behind the attack is to leverage the iterative nature of the diffusion process. By making small, carefully crafted changes to the input noise at each step of the diffusion process, the researchers were able to steer the model away from generating the intended image and towards producing a different, unintended output.
The researchers conducted extensive experiments on various diffusion models, including popular models like DDPM and GLIDE. They showed that their attack can achieve a high success rate in fooling the models, even when the input changes are barely perceptible to human observers.
The paper also provides insights into the vulnerabilities of diffusion models, suggesting that their high performance on standard benchmarks may not necessarily translate to robust security. The researchers argue that comprehensive security evaluations are needed to fully understand the limitations of these models and develop more secure approaches.
Critical Analysis
One limitation of the research is that it focuses primarily on evasion attacks and does not explore other types of attacks, such as data poisoning or adversarial examples. It would be valuable to investigate the robustness of diffusion models against a wider range of attack vectors to gain a more comprehensive understanding of their security.
Additionally, the paper does not provide detailed recommendations or strategies for mitigating the vulnerabilities it identifies. While the researchers highlight the need for comprehensive security evaluations, they do not offer specific solutions or approaches that can be used to improve the robustness of diffusion models.
Further research may also be needed to explore the generalizability of the proposed attack technique across different domains and applications of diffusion models, such as text-to-image synthesis or differential privacy.
Conclusion
This paper demonstrates that pixel-domain diffusion models can be vulnerable to evasion attacks, where small, imperceptible changes to the input can cause the model to misclassify or fail to recognize the original image. The findings highlight the importance of comprehensive security evaluations for these models, beyond just standard benchmarks.
While the paper focuses on evasion attacks, the insights it provides can motivate further research into the security of diffusion models and the development of more robust and secure approaches. Improving the overall security and reliability of these powerful generative models will be crucial as they continue to find widespread applications in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pixel Is Not A Barrier: An Effective Evasion Attack for Pixel-Domain Diffusion Models
Chun-Yen Shih, Li-Xuan Peng, Jia-Wei Liao, Ernie Chu, Cheng-Fu Chou, Jun-Cheng Chen
Diffusion Models have emerged as powerful generative models for high-quality image synthesis, with many subsequent image editing techniques based on them. However, the ease of text-based image editing introduces significant risks, such as malicious editing for scams or intellectual property infringement. Previous works have attempted to safeguard images from diffusion-based editing by adding imperceptible perturbations. These methods are costly and specifically target prevalent Latent Diffusion Models (LDMs), while Pixel-domain Diffusion Models (PDMs) remain largely unexplored and robust against such attacks. Our work addresses this gap by proposing a novel attacking framework with a feature representation attack loss that exploits vulnerabilities in denoising UNets and a latent optimization strategy to enhance the naturalness of protected images. Extensive experiments demonstrate the effectiveness of our approach in attacking dominant PDM-based editing methods (e.g., SDEdit) while maintaining reasonable protection fidelity and robustness against common defense methods. Additionally, our framework is extensible to LDMs, achieving comparable performance to existing approaches.
Read more8/22/2024
0
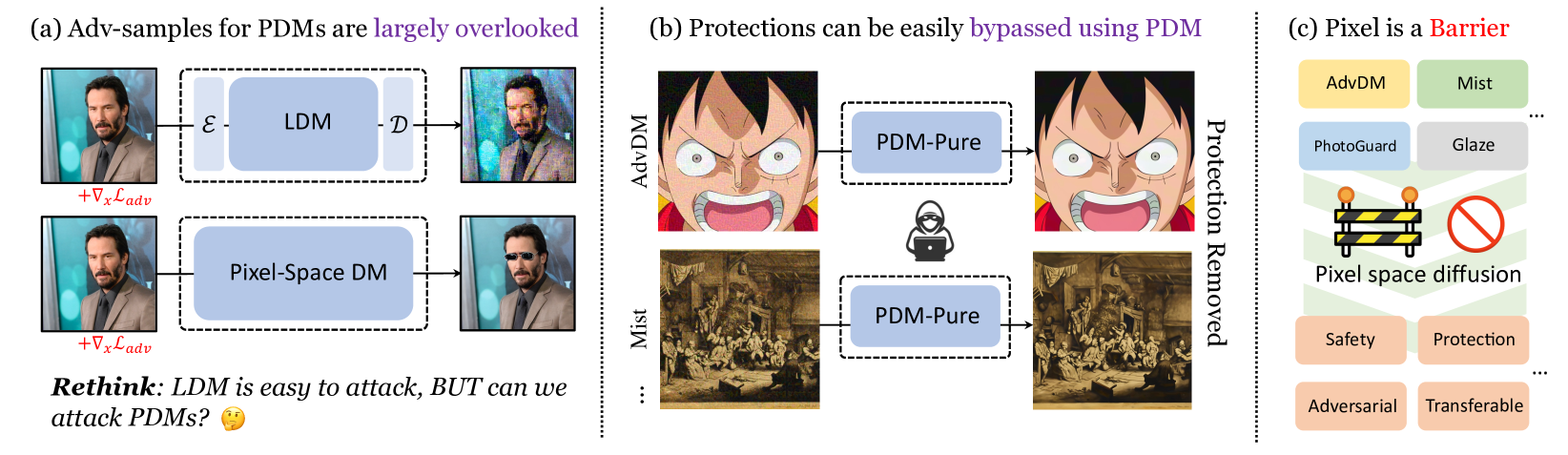
Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think
Haotian Xue, Yongxin Chen
Adversarial examples for diffusion models are widely used as solutions for safety concerns. By adding adversarial perturbations to personal images, attackers can not edit or imitate them easily. However, it is essential to note that all these protections target the latent diffusion model (LDMs), the adversarial examples for diffusion models in the pixel space (PDMs) are largely overlooked. This may mislead us to think that the diffusion models are vulnerable to adversarial attacks like most deep models. In this paper, we show novel findings that: even though gradient-based white-box attacks can be used to attack the LDMs, they fail to attack PDMs. This finding is supported by extensive experiments of almost a wide range of attacking methods on various PDMs and LDMs with different model structures, which means diffusion models are indeed much more robust against adversarial attacks. We also find that PDMs can be used as an off-the-shelf purifier to effectively remove the adversarial patterns that were generated on LDMs to protect the images, which means that most protection methods nowadays, to some extent, cannot protect our images from malicious attacks. We hope that our insights will inspire the community to rethink the adversarial samples for diffusion models as protection methods and move forward to more effective protection. Codes are available in https://github.com/xavihart/PDM-Pure.
Read more5/3/2024
🔮
0
Differentially Private Latent Diffusion Models
Michael F. Liu, Saiyue Lyu, Margarita Vinaroz, Mijung Park
Diffusion models (DMs) are one of the most widely used generative models for producing high quality images. However, a flurry of recent papers points out that DMs are least private forms of image generators, by extracting a significant number of near-identical replicas of training images from DMs. Existing privacy-enhancing techniques for DMs, unfortunately, do not provide a good privacy-utility tradeoff. In this paper, we aim to improve the current state of DMs with differential privacy (DP) by adopting the textit{Latent} Diffusion Models (LDMs). LDMs are equipped with powerful pre-trained autoencoders that map the high-dimensional pixels into lower-dimensional latent representations, in which DMs are trained, yielding a more efficient and fast training of DMs. Rather than fine-tuning the entire LDMs, we fine-tune only the $textit{attention}$ modules of LDMs with DP-SGD, reducing the number of trainable parameters by roughly $90%$ and achieving a better privacy-accuracy trade-off. Our approach allows us to generate realistic, high-dimensional images (256x256) conditioned on text prompts with DP guarantees, which, to the best of our knowledge, has not been attempted before. Our approach provides a promising direction for training more powerful, yet training-efficient differentially private DMs, producing high-quality DP images. Our code is available at https://anonymous.4open.science/r/DP-LDM-4525.
Read more7/22/2024
🌿
0
Intriguing Properties of Diffusion Models: An Empirical Study of the Natural Attack Capability in Text-to-Image Generative Models
Takami Sato, Justin Yue, Nanze Chen, Ningfei Wang, Qi Alfred Chen
Denoising probabilistic diffusion models have shown breakthrough performance to generate more photo-realistic images or human-level illustrations than the prior models such as GANs. This high image-generation capability has stimulated the creation of many downstream applications in various areas. However, we find that this technology is actually a double-edged sword: We identify a new type of attack, called the Natural Denoising Diffusion (NDD) attack based on the finding that state-of-the-art deep neural network (DNN) models still hold their prediction even if we intentionally remove their robust features, which are essential to the human visual system (HVS), through text prompts. The NDD attack shows a significantly high capability to generate low-cost, model-agnostic, and transferable adversarial attacks by exploiting the natural attack capability in diffusion models. To systematically evaluate the risk of the NDD attack, we perform a large-scale empirical study with our newly created dataset, the Natural Denoising Diffusion Attack (NDDA) dataset. We evaluate the natural attack capability by answering 6 research questions. Through a user study, we find that it can achieve an 88% detection rate while being stealthy to 93% of human subjects; we also find that the non-robust features embedded by diffusion models contribute to the natural attack capability. To confirm the model-agnostic and transferable attack capability, we perform the NDD attack against the Tesla Model 3 and find that 73% of the physically printed attacks can be detected as stop signs. Our hope is that the study and dataset can help our community be aware of the risks in diffusion models and facilitate further research toward robust DNN models.
Read more5/3/2024