Planning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1

0

Sign in to get full access
Overview
- The paper evaluates and aims to improve the planning and scheduling capabilities of the large language model LRM o1.
- It explores how well LRM o1 can handle planning tasks in the domain of strawberry farming.
- The researchers conduct various experiments to assess LRM o1's planning abilities and suggest ways to enhance its performance.
Plain English Explanation
The paper examines the planning and scheduling skills of a large language model called LRM o1. The researchers are interested in understanding how well LRM o1 can handle planning tasks in the context of strawberry farming. They conduct a series of experiments to evaluate LRM o1's capabilities and identify ways to improve its performance.
Planning and scheduling are essential skills for many real-world tasks, such as managing a farm or running a business. Large language models like LRM o1 have shown impressive capabilities in various areas, but their planning abilities are not well understood. This paper aims to shed light on this aspect of LRM o1's skills.
By testing LRM o1 in the domain of strawberry farming, the researchers can explore how the model handles tasks like scheduling planting, harvesting, and other operations. They analyze the model's decision-making processes, its ability to optimize plans, and its adaptability to changes in the environment or new information.
The findings from this research can help inform the development of more capable planning and scheduling systems, which could have practical applications in agriculture, logistics, and other domains. Additionally, understanding the limitations and strengths of large language models in this area can guide future research and the design of more effective AI-powered planning tools.
Technical Explanation
The paper presents a detailed evaluation of the planning and scheduling capabilities of the large language model LRM o1. The researchers designed a series of experiments to assess how well LRM o1 can handle planning tasks in the context of strawberry farming.
The experimental setup involved simulating a strawberry farm and tasking LRM o1 with various planning and scheduling challenges, such as:
- Determining the optimal planting and harvesting schedules
- Adapting plans in response to changes in environmental conditions or new information
- Optimizing resource allocation and labor utilization
The researchers analyzed LRM o1's decision-making processes, the quality of the plans it generated, and its ability to adapt to dynamic situations. They also explored ways to improve LRM o1's planning performance, such as incorporating additional training data, modifying the model architecture, or introducing specialized planning modules.
The results of the experiments provide insights into the strengths and limitations of LRM o1's planning abilities. The paper discusses the implications of these findings for the development of more capable planning and scheduling systems, which could have practical applications in various domains, including agriculture, logistics, and resource management.
Critical Analysis
The paper offers a thorough evaluation of LRM o1's planning and scheduling capabilities, which is a valuable contribution to the understanding of large language models' abilities in this domain. The researchers' experimental design, involving a simulated strawberry farm environment, provides a realistic and well-controlled setting to assess the model's performance.
However, the paper does not address some potential limitations or caveats of the research. For example, the study is focused solely on the strawberry farming domain, and it's unclear how well the findings would generalize to other planning and scheduling tasks. Additionally, the paper does not discuss the computational resources and time required to train and run the LRM o1 model, which could be an important consideration for real-world applications.
The paper also does not explore the ethical implications of using large language models for planning and decision-making in sensitive domains, such as resource allocation or environmental management. As these models become more advanced, it will be critical to consider their potential biases, transparency, and accountability.
Overall, the paper presents a solid technical evaluation of LRM o1's planning and scheduling capabilities, but there are opportunities for further research to address the limitations and expand the scope of the investigation.
Conclusion
The research in this paper provides valuable insights into the planning and scheduling abilities of the large language model LRM o1. By testing the model in the context of strawberry farming, the researchers have gained a better understanding of its strengths, weaknesses, and potential areas for improvement.
The findings suggest that LRM o1 has some promising planning capabilities, but there is still room for enhancement. The paper outlines several approaches to improve the model's performance, which could lead to the development of more capable planning and scheduling systems. These advancements could have significant practical applications in agriculture, logistics, and other domains that require effective resource management and decision-making.
As large language models continue to evolve, it will be crucial to thoroughly evaluate their abilities and limitations, particularly in high-stakes areas like planning and decision-making. The insights from this research contribute to the ongoing efforts to understand the capabilities and potential of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Planning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1
Karthik Valmeekam, Kaya Stechly, Atharva Gundawar, Subbarao Kambhampati
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities, but -- despite the slew of new private and open source LLMs since GPT3 -- progress has remained slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs -- making it a new kind of model: a Large Reasoning Model (LRM). In this paper, we evaluate the planning capabilities of two LRMs (o1-preview and o1-mini) on both planning and scheduling benchmarks. We see that while o1 does seem to offer significant improvements over autoregressive LLMs, this comes at a steep inference cost, while still failing to provide any guarantees over what it generates. We also show that combining o1 models with external verifiers -- in a so-called LRM-Modulo system -- guarantees the correctness of the combined system's output while further improving performance.
Read more10/4/2024

1
LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
Karthik Valmeekam, Kaya Stechly, Subbarao Kambhampati
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities. PlanBench, an extensible benchmark we developed in 2022, soon after the release of GPT3, has remained an important tool for evaluating the planning abilities of LLMs. Despite the slew of new private and open source LLMs since GPT3, progress on this benchmark has been surprisingly slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs--making it a new kind of model: a Large Reasoning Model (LRM). Using this development as a catalyst, this paper takes a comprehensive look at how well current LLMs and new LRMs do on PlanBench. As we shall see, while o1's performance is a quantum improvement on the benchmark, outpacing the competition, it is still far from saturating it. This improvement also brings to the fore questions about accuracy, efficiency, and guarantees which must be considered before deploying such systems.
Read more9/23/2024
0
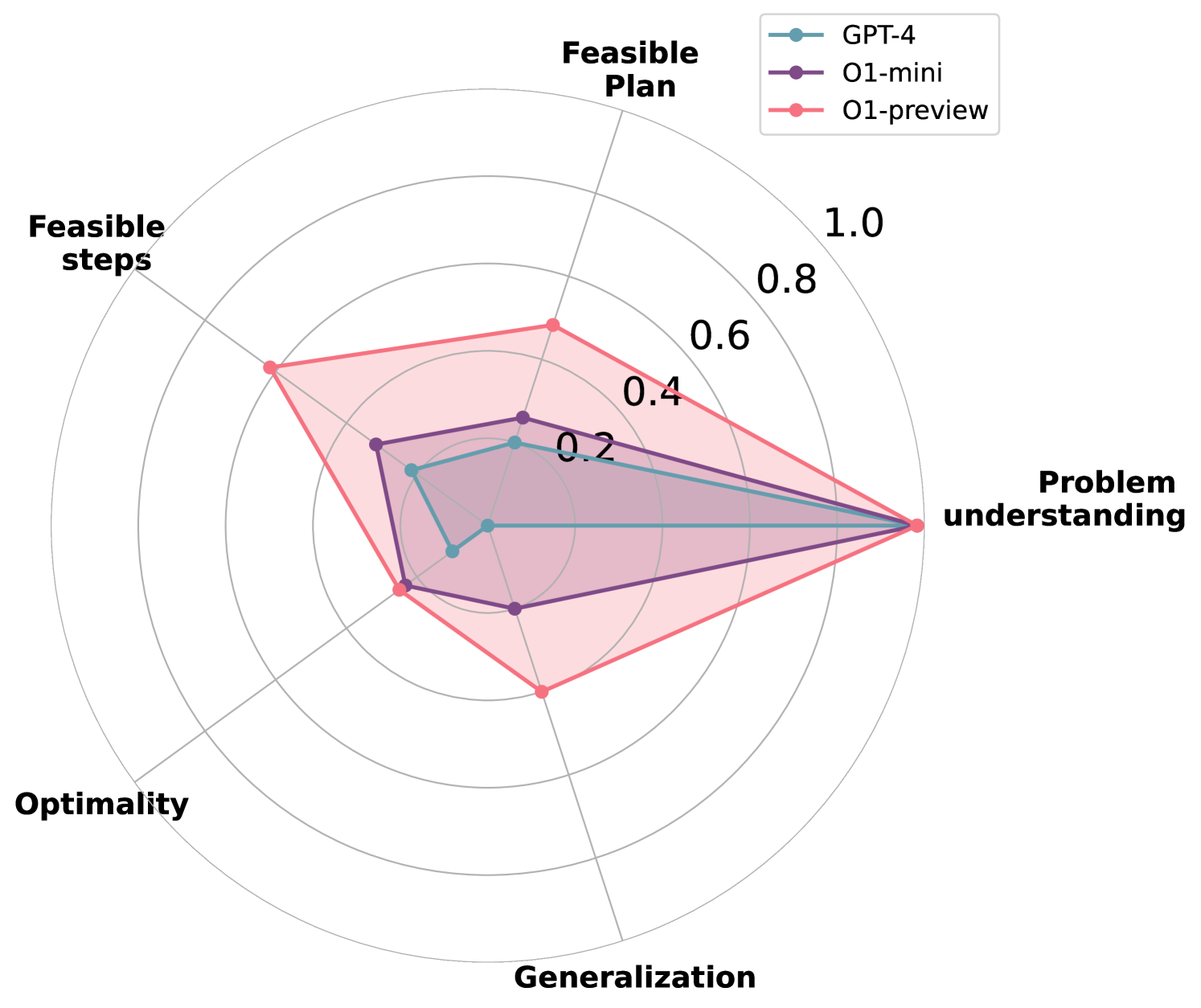
New!On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Kevin Wang, Junbo Li, Neel P. Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, Zhangyang Wang
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $textit{Barman}$, $textit{Tyreworld}$) and spatially complex environments (e.g., $textit{Termes}$, $textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
Read more10/2/2024

0
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, Anil Murthy
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
Read more6/13/2024