On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability

0
Sign in to get full access
Overview
- The paper examines the planning abilities of OpenAI's o1 models from three perspectives: feasibility, optimality, and generalizability.
- The researchers conduct experiments to evaluate the models' capabilities in solving complex planning tasks.
- The findings provide insights into the strengths and limitations of current large language models in terms of their planning abilities.
Plain English Explanation
The paper investigates the planning capabilities of a specific type of artificial intelligence (AI) model called "o1" developed by OpenAI. Planning is an essential skill for AI systems to be able to solve complex problems and make decisions.
The researchers looked at the planning abilities of these o1 models from three different angles:
- Feasibility: Can the models actually solve planning tasks, or are they too limited in their capabilities?
- Optimality: If the models can solve planning tasks, do they find the best or most efficient solutions, or are their solutions suboptimal?
- Generalizability: Can the models apply their planning skills to a wide range of problems, or are they limited to specific types of tasks?
To answer these questions, the researchers designed experiments where the o1 models had to solve various planning problems. They then analyzed the models' performance to better understand the current state of AI planning abilities.
The findings from this research provide valuable insights into the strengths and weaknesses of large language models like o1 when it comes to planning and problem-solving. This information can help guide the future development of more capable and versatile AI systems.
Technical Explanation
The paper investigates the planning abilities of OpenAI's o1 models from three key perspectives: feasibility, optimality, and generalizability.
Feasibility: The researchers assess whether the o1 models can solve complex planning tasks at all, or if their capabilities are too limited. They design experiments to test the models' performance on various planning problems.
Optimality: If the o1 models can solve planning tasks, the researchers examine whether their solutions are optimal (i.e., the best possible solutions) or merely suboptimal. They analyze the quality of the models' outputs compared to known optimal solutions.
Generalizability: The paper also investigates the extent to which the o1 models' planning abilities can be applied to a wide range of problems, or if they are confined to specific types of tasks. The researchers test the models' performance across diverse planning scenarios.
Through these experiments and analyses, the paper provides valuable insights into the current state of AI planning capabilities, as represented by OpenAI's o1 models. The findings highlight both the strengths and limitations of these large language models when it comes to solving complex planning problems.
Critical Analysis
The paper acknowledges several caveats and limitations of the research. For example, the experiments are conducted on a relatively small set of planning tasks, and the researchers note that further testing on a broader range of problems would be necessary to fully assess the generalizability of the o1 models' planning abilities.
Additionally, the paper suggests that the models' performance may be influenced by factors such as the specific architecture and training data used, which are not fully explored in this study. More research would be needed to understand how different model designs and training approaches might impact planning capabilities.
The paper also raises the question of whether the observed limitations of the o1 models are inherent to large language models in general, or if alternative approaches (such as reinforcement learning-based models) might be able to overcome these challenges.
Overall, the paper provides a valuable contribution to our understanding of AI planning capabilities, but it also highlights the need for continued research and experimentation to further develop and refine these critical skills.
Conclusion
This paper offers a comprehensive evaluation of the planning abilities of OpenAI's o1 models, examining their feasibility, optimality, and generalizability. The findings suggest that while these large language models can solve certain planning tasks, they face limitations in terms of the quality of their solutions and the breadth of problems they can handle.
The insights gleaned from this research can inform the ongoing development of more capable and versatile AI systems, particularly in the area of planning and decision-making. As the field of artificial intelligence continues to advance, studies like this one will be crucial in guiding the design and training of future models to better emulate human-level planning abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Kevin Wang, Junbo Li, Neel P. Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, Zhangyang Wang
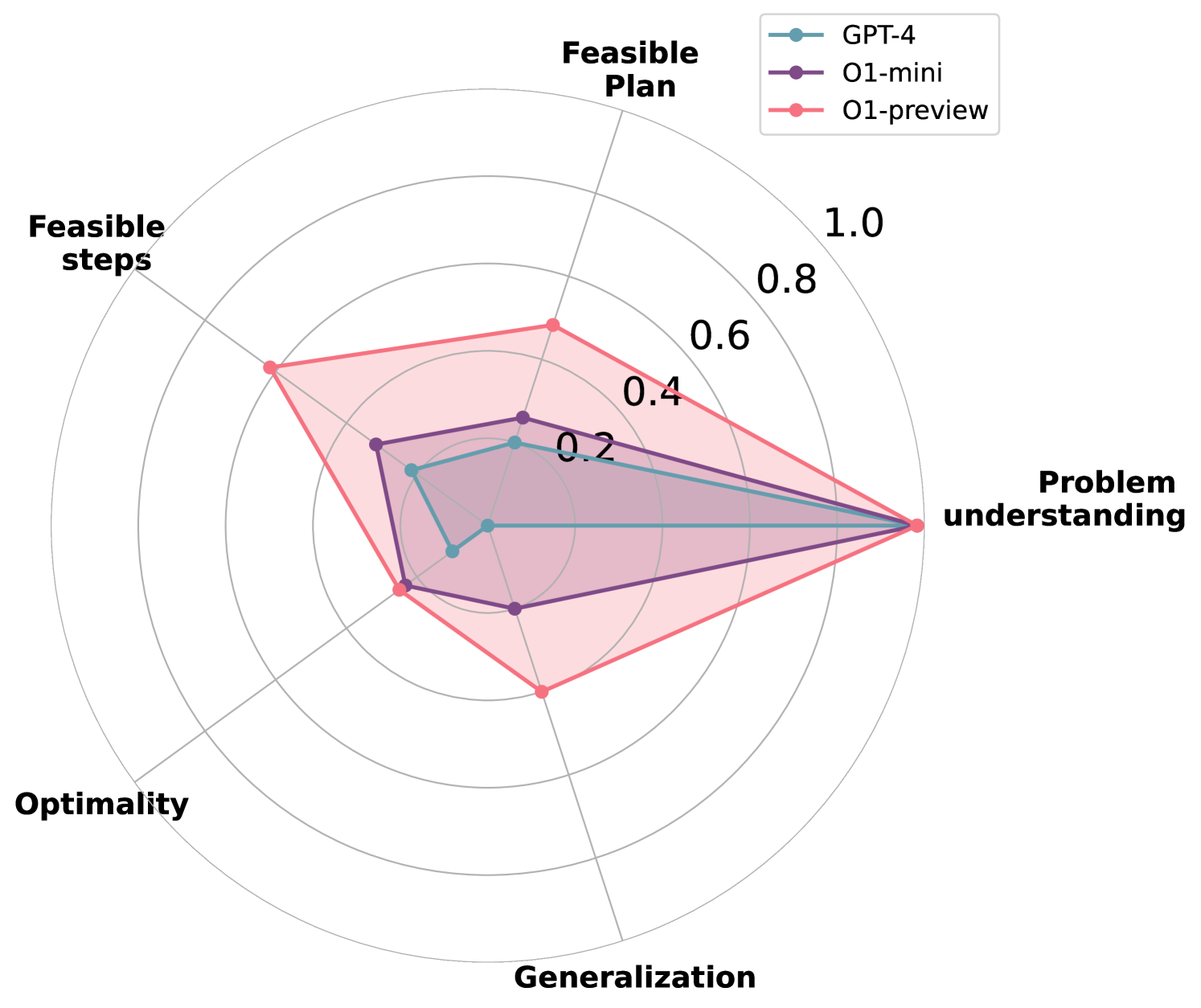
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $textit{Barman}$, $textit{Tyreworld}$) and spatially complex environments (e.g., $textit{Termes}$, $textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
Read more10/2/2024

1
LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
Karthik Valmeekam, Kaya Stechly, Subbarao Kambhampati
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities. PlanBench, an extensible benchmark we developed in 2022, soon after the release of GPT3, has remained an important tool for evaluating the planning abilities of LLMs. Despite the slew of new private and open source LLMs since GPT3, progress on this benchmark has been surprisingly slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs--making it a new kind of model: a Large Reasoning Model (LRM). Using this development as a catalyst, this paper takes a comprehensive look at how well current LLMs and new LRMs do on PlanBench. As we shall see, while o1's performance is a quantum improvement on the benchmark, outpacing the competition, it is still far from saturating it. This improvement also brings to the fore questions about accuracy, efficiency, and guarantees which must be considered before deploying such systems.
Read more9/23/2024

0
New!Planning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1
Karthik Valmeekam, Kaya Stechly, Atharva Gundawar, Subbarao Kambhampati
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities, but -- despite the slew of new private and open source LLMs since GPT3 -- progress has remained slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs -- making it a new kind of model: a Large Reasoning Model (LRM). In this paper, we evaluate the planning capabilities of two LRMs (o1-preview and o1-mini) on both planning and scheduling benchmarks. We see that while o1 does seem to offer significant improvements over autoregressive LLMs, this comes at a steep inference cost, while still failing to provide any guarantees over what it generates. We also show that combining o1 models with external verifiers -- in a so-called LRM-Modulo system -- guarantees the correctness of the combined system's output while further improving performance.
Read more10/4/2024
🏷️
0
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, Chao Cao, Hanqi Jiang, Hanxu Chen, Yiwei Li, Junhao Chen, Huawen Hu, Yihen Liu, Huaqin Zhao, Shaochen Xu, Haixing Dai, Lin Zhao, Ruidong Zhang, Wei Zhao, Zhenyuan Yang, Jingyuan Chen, Peilong Wang, Wei Ruan, Hui Wang, Huan Zhao, Jing Zhang, Yiming Ren, Shihuan Qin, Tong Chen, Jiaxi Li, Arif Hassan Zidan, Afrar Jahin, Minheng Chen, Sichen Xia, Jason Holmes, Yan Zhuang, Jiaqi Wang, Bochen Xu, Weiran Xia, Jichao Yu, Kaibo Tang, Yaxuan Yang, Bolun Sun, Tao Yang, Guoyu Lu, Xianqiao Wang, Lilong Chai, He Li, Jin Lu, Lichao Sun, Xin Zhang, Bao Ge, Xintao Hu, Lian Zhang, Hua Zhou, Lu Zhang, Shu Zhang, Ninghao Liu, Bei Jiang, Linglong Kong, Zhen Xiang, Yudan Ren, Jun Liu, Xi Jiang, Yu Bao, Wei Zhang, Xiang Li, Gang Li, Wei Liu, Dinggang Shen, Andrea Sikora, Xiaoming Zhai, Dajiang Zhu, Tianming Liu
This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Read more9/30/2024