Plug-in Performative Optimization

0
🛠️
Sign in to get full access
Overview
- When predictions influence the future, the choice of predictor can impact future observations.
- The goal is to find a predictor with low "performative risk" - good performance on the induced distribution.
- Existing solutions either ignore the structure of performative feedback (slow convergence) or rely on exact feedback models (sensitive to model misspecification).
Plain English Explanation
In many real-world situations, our predictions can actually change the future they're meant to forecast. For example, a credit scoring model that denies loans to certain applicants may lead to fewer of those applicants even applying in the future. This creates a feedback loop where the predictor itself influences the data it's trained on.
The challenge is to find a predictor that performs well even under this "performative" setting, where its predictions impact the future distribution of observations. One family of solutions, like bandits and other derivative-free methods, ignore the structure of this performative feedback, leading to slow convergence. Another family uses explicit models of the performative feedback, like in strategic classification, enabling faster convergence, but relying critically on the feedback model being correct.
This paper studies a general approach called "plug-in performative optimization" that can leverage potentially imperfect models of the performative feedback. As long as the model isn't too far off, this approach can outperform model-agnostic strategies, providing evidence that even imperfect models can help with learning in performative settings.
Technical Explanation
The paper examines the problem of "performative prediction," where the choice of predictor influences the distribution of future observations that the predictor will see. The overarching goal is to find a predictor with low "performative risk" - good performance on the induced distribution.
One family of existing solutions, including bandits and other derivative-free methods, is agnostic to the structure of the performative feedback, leading to slow convergence rates. In contrast, a complementary family of solutions makes use of explicit models of the performative feedback, such as best-response models in strategic classification, enabling faster rates. However, these rates critically rely on the feedback model being correct.
This paper proposes a general protocol called "plug-in performative optimization" that can leverage possibly misspecified models of the performative feedback. The key insight is that as long as the misspecification is not too extreme, this approach can be far superior to model-agnostic strategies. The results support the hypothesis that models, even if imperfect, can indeed help with learning in performative settings.
Critical Analysis
The paper acknowledges that the proposed "plug-in performative optimization" approach relies on the assumption that the model of performative feedback is not too misspecified. If the model is severely wrong, the approach may perform worse than model-agnostic strategies. Additionally, the paper does not address how to determine the degree of model misspecification in practice, which could be a challenge in real-world applications.
Furthermore, the paper focuses on the theoretical analysis and does not provide extensive empirical evaluation. Practical case studies demonstrating the performance of the plug-in approach compared to alternatives would strengthen the conclusions and help readers assess its real-world applicability.
It would also be valuable for the authors to discuss potential pitfalls or unintended consequences of deploying predictors in performative settings. For example, decision-focused predictions via pessimistic bilevel optimization can help address the challenge of strategic behavior, which is an important consideration in performative prediction.
Overall, the paper makes a compelling theoretical contribution, but further empirical validation and discussion of practical considerations would enhance the impact and usefulness of the research.
Conclusion
This paper explores a general approach called "plug-in performative optimization" that can leverage potentially imperfect models of the performative feedback - the phenomenon where the choice of predictor influences the future distribution of observations.
The key insight is that as long as the model misspecification is not too extreme, this approach can outperform model-agnostic strategies, providing evidence that even imperfect models can be helpful in learning for performative settings. This is an important step forward, as existing solutions either ignore the structure of performative feedback (leading to slow convergence) or rely on exact feedback models (which are sensitive to misspecification).
While the theoretical analysis is strong, further empirical validation and discussion of practical considerations would strengthen the real-world applicability of this research. Nonetheless, this work represents a valuable contribution to the challenge of making accurate predictions in settings where the predictions themselves can impact the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Plug-in Performative Optimization
Licong Lin, Tijana Zrnic
When predictions are performative, the choice of which predictor to deploy influences the distribution of future observations. The overarching goal in learning under performativity is to find a predictor that has low emph{performative risk}, that is, good performance on its induced distribution. One family of solutions for optimizing the performative risk, including bandits and other derivative-free methods, is agnostic to any structure in the performative feedback, leading to exceedingly slow convergence rates. A complementary family of solutions makes use of explicit emph{models} for the feedback, such as best-response models in strategic classification, enabling faster rates. However, these rates critically rely on the feedback model being correct. In this work we study a general protocol for making use of possibly misspecified models in performative prediction, called emph{plug-in performative optimization}. We show this solution can be far superior to model-agnostic strategies, as long as the misspecification is not too extreme. Our results support the hypothesis that models, even if misspecified, can indeed help with learning in performative settings.
Read more5/29/2024
🔮
0
Performative Prediction with Neural Networks
Mehrnaz Mofakhami, Ioannis Mitliagkas, Gauthier Gidel
Performative prediction is a framework for learning models that influence the data they intend to predict. We focus on finding classifiers that are performatively stable, i.e. optimal for the data distribution they induce. Standard convergence results for finding a performatively stable classifier with the method of repeated risk minimization assume that the data distribution is Lipschitz continuous to the model's parameters. Under this assumption, the loss must be strongly convex and smooth in these parameters; otherwise, the method will diverge for some problems. In this work, we instead assume that the data distribution is Lipschitz continuous with respect to the model's predictions, a more natural assumption for performative systems. As a result, we are able to significantly relax the assumptions on the loss function. In particular, we do not need to assume convexity with respect to the model's parameters. As an illustration, we introduce a resampling procedure that models realistic distribution shifts and show that it satisfies our assumptions. We support our theory by showing that one can learn performatively stable classifiers with neural networks making predictions about real data that shift according to our proposed procedure.
Read more8/27/2024
🔮
0
Performative Prediction with Bandit Feedback: Learning through Reparameterization
Yatong Chen, Wei Tang, Chien-Ju Ho, Yang Liu
Performative prediction, as introduced by Perdomo et al, is a framework for studying social prediction in which the data distribution itself changes in response to the deployment of a model. Existing work in this field usually hinges on three assumptions that are easily violated in practice: that the performative risk is convex over the deployed model, that the mapping from the model to the data distribution is known to the model designer in advance, and the first-order information of the performative risk is available. In this paper, we initiate the study of performative prediction problems that do not require these assumptions. Specifically, we develop a reparameterization framework that reparametrizes the performative prediction objective as a function of the induced data distribution. We then develop a two-level zeroth-order optimization procedure, where the first level performs iterative optimization on the distribution parameter space, and the second level learns the model that induces a particular target distribution at each iteration. Under mild conditions, this reparameterization allows us to transform the non-convex objective into a convex one and achieve provable regret guarantees. In particular, we provide a regret bound that is sublinear in the total number of performative samples taken and is only polynomial in the dimension of the model parameter.
Read more8/14/2024
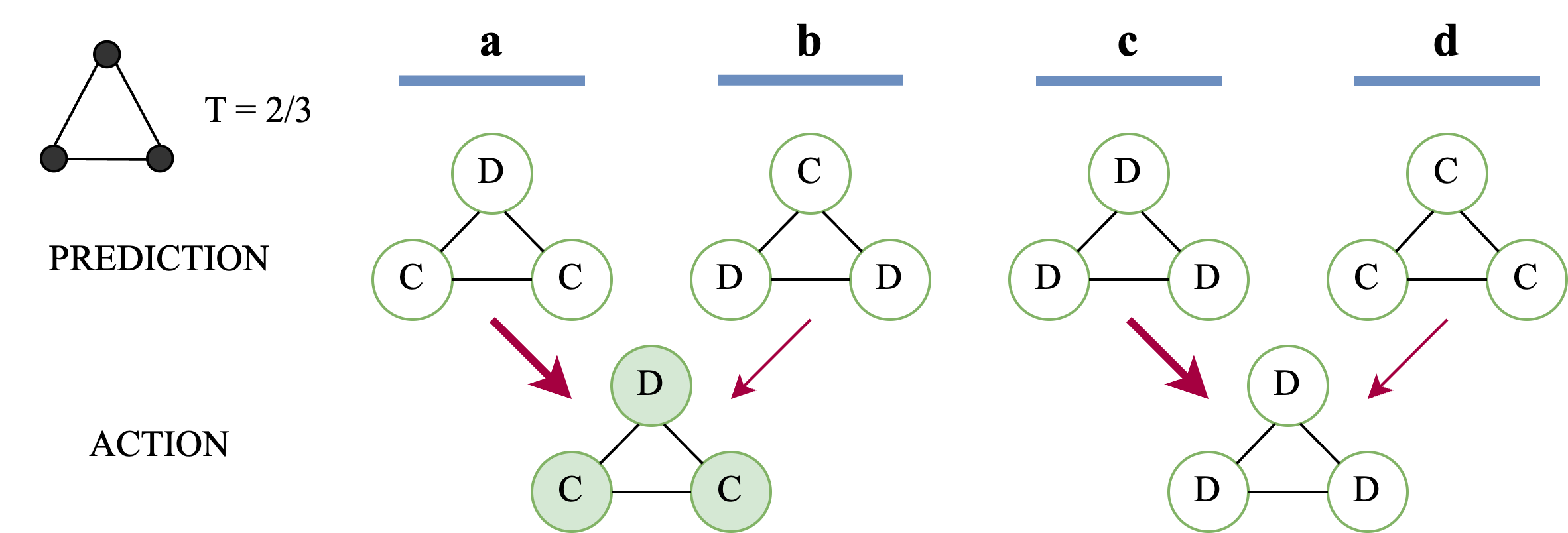
0
Performative Prediction on Games and Mechanism Design
Ant'onio G'ois, Mehrnaz Mofakhami, Fernando P. Santos, Simon Lacoste-Julien, Gauthier Gidel
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.
Read more8/12/2024