PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel semi-supervised learning method called Progressive Mean Teacher (PMT) for medical image segmentation.
- PMT aims to improve segmentation performance by leveraging unlabeled data through temporal consistency regularization.
- The key idea is to progressively update the model parameters of a "teacher" network to guide the training of a "student" network.
Plain English Explanation
PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation is a research paper that introduces a new approach for improving medical image segmentation, which is the task of automatically identifying and delineating different anatomical structures in medical images.
The main challenge in medical image segmentation is the limited availability of labeled training data, as manually annotating medical images is a time-consuming and expensive process. To address this, the paper proposes a semi-supervised learning method called Progressive Mean Teacher (PMT) that can leverage both labeled and unlabeled data to improve segmentation performance.
The key idea behind PMT is to use a "teacher" network to guide the training of a "student" network. The teacher network is a slowly evolving version of the student network, and its role is to provide temporal consistency information to the student network during training. This means that the student network is encouraged to produce segmentation outputs that are similar to the teacher's predictions over time, even for unlabeled images.
By progressively updating the teacher network to match the student network, PMT is able to gradually refine the segmentation capabilities of the student network and improve its performance on both labeled and unlabeled data. This approach helps to overcome the limitations of traditional supervised learning, which can struggle when there is a lack of labeled training data.
Technical Explanation
PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation introduces a novel semi-supervised learning method called Progressive Mean Teacher (PMT) for medical image segmentation.
The core of PMT is a teacher-student framework, where the teacher network is a slowly evolving version of the student network. During training, the student network is encouraged to produce segmentation outputs that are similar to the teacher's predictions over time, even for unlabeled images. This is achieved through a temporal consistency regularization term in the loss function.
Specifically, the teacher network is updated as a moving average of the student network's parameters, with a gradually decreasing update rate. This progressive update strategy allows the teacher to capture the evolving knowledge of the student network, providing more effective guidance as training progresses.
The authors demonstrate the effectiveness of PMT on several medical image segmentation tasks, including brain tumor, skin lesion, and retinal vessel segmentation. Compared to other semi-supervised learning methods, PMT is shown to achieve superior performance by better leveraging the available unlabeled data through the temporal consistency constraint.
Critical Analysis
The authors provide a thorough evaluation of PMT, including comparisons to state-of-the-art semi-supervised and supervised learning methods. The results show that PMT can significantly improve segmentation performance, especially in scenarios with limited labeled data.
However, the paper does not address some potential limitations of the approach. For example, the effectiveness of PMT may depend on the quality and diversity of the unlabeled data, which is not discussed in detail. Additionally, the computational overhead of maintaining the teacher network and the associated hyperparameter tuning could be a practical concern, especially for large-scale medical image applications.
Further research could explore ways to adaptively adjust the teacher-student update rate or investigate more efficient implementations of the temporal consistency regularization. Exploring the robustness of PMT to different types of distribution shifts in the unlabeled data would also be an interesting direction for future work.
Conclusion
PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation presents a novel semi-supervised learning method called Progressive Mean Teacher (PMT) that leverages temporal consistency regularization to improve medical image segmentation performance.
The key insight of PMT is to use a slowly evolving "teacher" network to guide the training of a "student" network, encouraging the student to produce segmentation outputs that are consistent with the teacher's predictions over time. This approach allows PMT to effectively utilize both labeled and unlabeled data, overcoming the limitations of traditional supervised learning.
The results demonstrate the effectiveness of PMT on various medical image segmentation tasks, particularly in scenarios with limited labeled data. While the paper raises some potential areas for further research, the proposed PMT method represents a significant contribution to the field of semi-supervised learning for medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation
Ning Gao, Sanping Zhou, Le Wang, Nanning Zheng
Semi-supervised learning has emerged as a widely adopted technique in the field of medical image segmentation. The existing works either focuses on the construction of consistency constraints or the generation of pseudo labels to provide high-quality supervisory signals, whose main challenge mainly comes from how to keep the continuous improvement of model capabilities. In this paper, we propose a simple yet effective semi-supervised learning framework, termed Progressive Mean Teachers (PMT), for medical image segmentation, whose goal is to generate high-fidelity pseudo labels by learning robust and diverse features in the training process. Specifically, our PMT employs a standard mean teacher to penalize the consistency of the current state and utilizes two sets of MT architectures for co-training. The two sets of MT architectures are individually updated for prolonged periods to maintain stable model diversity established through performance gaps generated by iteration differences. Additionally, a difference-driven alignment regularizer is employed to expedite the alignment of lagging models with the representation capabilities of leading models. Furthermore, a simple yet effective pseudo-label filtering algorithm is employed for facile evaluation of models and selection of high-fidelity pseudo-labels outputted when models are operating at high performance for co-training purposes. Experimental results on two datasets with different modalities, i.e., CT and MRI, demonstrate that our method outperforms the state-of-the-art medical image segmentation approaches across various dimensions. The code is available at https://github.com/Axi404/PMT.
Read more9/17/2024
0
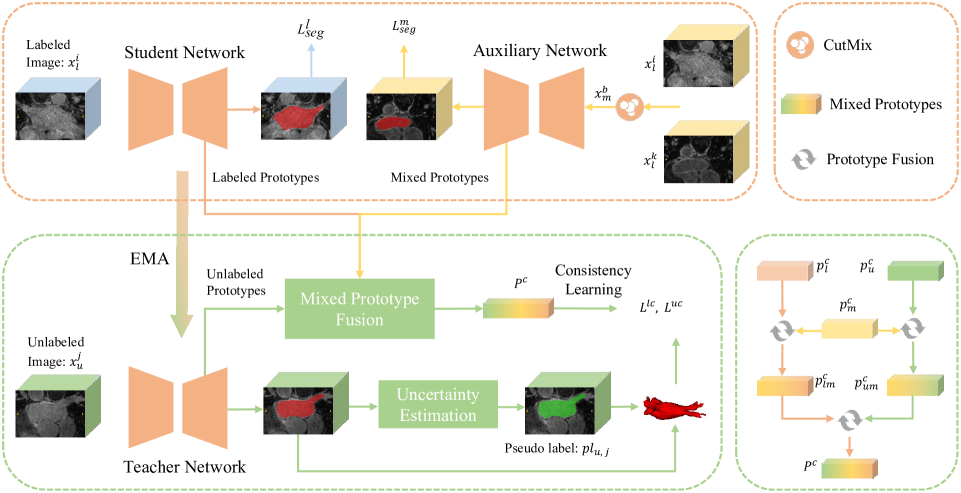
Mixed Prototype Consistency Learning for Semi-supervised Medical Image Segmentation
Lijian Li
Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To address this problem, we propose the Mixed Prototype Consistency Learning (MPCL) framework, which includes a Mean Teacher and an auxiliary network. The Mean Teacher generates prototypes for labeled and unlabeled data, while the auxiliary network produces additional prototypes for mixed data processed by CutMix. Through prototype fusion, mixed prototypes provide extra semantic information to both labeled and unlabeled prototypes. High-quality global prototypes for each class are formed by fusing two enhanced prototypes, optimizing the distribution of hidden embeddings used in consistency learning. Extensive experiments on the left atrium and type B aortic dissection datasets demonstrate MPCL's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
Read more4/17/2024
0
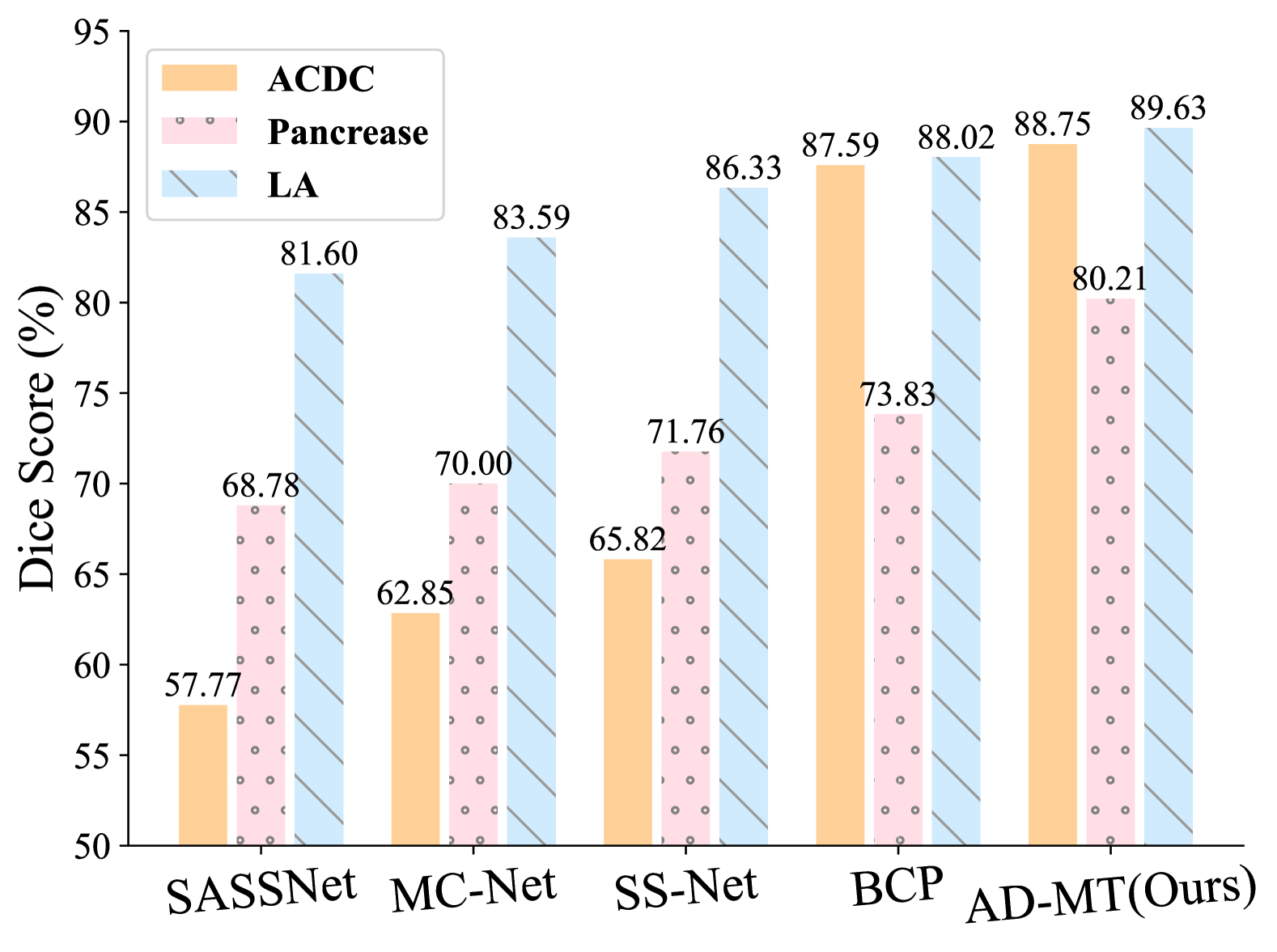
Alternate Diverse Teaching for Semi-supervised Medical Image Segmentation
Zhen Zhao, Zicheng Wang, Longyue Wang, Dian Yu, Yixuan Yuan, Luping Zhou
Semi-supervised medical image segmentation studies have shown promise in training models with limited labeled data. However, current dominant teacher-student based approaches can suffer from the confirmation bias. To address this challenge, we propose AD-MT, an alternate diverse teaching approach in a teacher-student framework. It involves a single student model and two non-trainable teacher models that are momentum-updated periodically and randomly in an alternate fashion. To mitigate the confirmation bias from the diverse supervision, the core of AD-MT lies in two proposed modules: the Random Periodic Alternate (RPA) Updating Module and the Conflict-Combating Module (CCM). The RPA schedules the alternating diverse updating process with complementary data batches, distinct data augmentation, and random switching periods to encourage diverse reasoning from different teaching perspectives. The CCM employs an entropy-based ensembling strategy to encourage the model to learn from both the consistent and conflicting predictions between the teachers. Experimental results demonstrate the effectiveness and superiority of our AD-MT on the 2D and 3D medical segmentation benchmarks across various semi-supervised settings.
Read more7/15/2024

0
Revisiting and Maximizing Temporal Knowledge in Semi-supervised Semantic Segmentation
Wooseok Shin, Hyun Joon Park, Jin Sob Kim, Sung Won Han
In semi-supervised semantic segmentation, the Mean Teacher- and co-training-based approaches are employed to mitigate confirmation bias and coupling problems. However, despite their high performance, these approaches frequently involve complex training pipelines and a substantial computational burden, limiting the scalability and compatibility of these methods. In this paper, we propose a PrevMatch framework that effectively mitigates the aforementioned limitations by maximizing the utilization of the temporal knowledge obtained during the training process. The PrevMatch framework relies on two core strategies: (1) we reconsider the use of temporal knowledge and thus directly utilize previous models obtained during training to generate additional pseudo-label guidance, referred to as previous guidance. (2) we design a highly randomized ensemble strategy to maximize the effectiveness of the previous guidance. Experimental results on four benchmark semantic segmentation datasets confirm that the proposed method consistently outperforms existing methods across various evaluation protocols. In particular, with DeepLabV3+ and ResNet-101 network settings, PrevMatch outperforms the existing state-of-the-art method, Diverse Co-training, by +1.6 mIoU on Pascal VOC with only 92 annotated images, while achieving 2.4 times faster training. Furthermore, the results indicate that PrevMatch induces stable optimization, particularly in benefiting classes that exhibit poor performance. Code is available at https://github.com/wooseok-shin/PrevMatch
Read more6/3/2024