Alternate Diverse Teaching for Semi-supervised Medical Image Segmentation

0
Sign in to get full access
Overview
- This paper proposes an "Alternate Diverse Teaching" (ADT) method for semi-supervised medical image segmentation.
- The goal is to train a segmentation model efficiently using a small set of labeled data and a larger set of unlabeled data.
- The key idea is to have multiple "teacher" models that provide diverse predictions, which are then used to train a single "student" model.
Plain English Explanation
Medical image segmentation is the process of automatically identifying and outlining different structures or regions within medical images, such as organs or tumors. This is an important task for disease diagnosis and treatment planning. However, training accurate segmentation models typically requires a large amount of labeled training data, which can be time-consuming and expensive to collect, especially in the medical domain.
The Alternate Diverse Teaching method introduced in this paper aims to address this challenge by utilizing both a small set of labeled data and a larger set of unlabeled data. The key insight is that having multiple "teacher" models provide diverse predictions can help train a single "student" model more effectively.
Specifically, the authors train several different teacher models, each with its own unique architecture and training approach. These teacher models are then used to generate predictions for the unlabeled data, which are in turn used to train the student model. By combining the diverse predictions from the teachers, the student model can learn a more robust and accurate segmentation without relying solely on the limited labeled data.
This approach builds upon previous work on versatile teacher-student frameworks and adaptive model merging for semi-supervised learning. By leveraging the complementary strengths of multiple teacher models, the Alternate Diverse Teaching method can achieve better performance than traditional single-teacher approaches, especially when the labeled data is scarce.
Technical Explanation
The Alternate Diverse Teaching (ADT) method consists of three main components:
-
Teacher Model Training: The authors train multiple teacher models, each with a different architecture and training approach. These include a U-Net-based model, a nnU-Net-based model, and a self-supervised model pre-trained on a large unlabeled dataset.
-
Prediction Generation: The trained teacher models are used to generate predictions for the unlabeled data. These diverse predictions are then combined to form the "pseudo-labels" that will be used to train the student model.
-
Student Model Training: The student model, which has a similar architecture to the teacher models, is trained using a combination of the limited labeled data and the pseudo-labels generated by the teacher models. The student model learns to mimic the diverse predictions of the teachers, leading to improved segmentation performance.
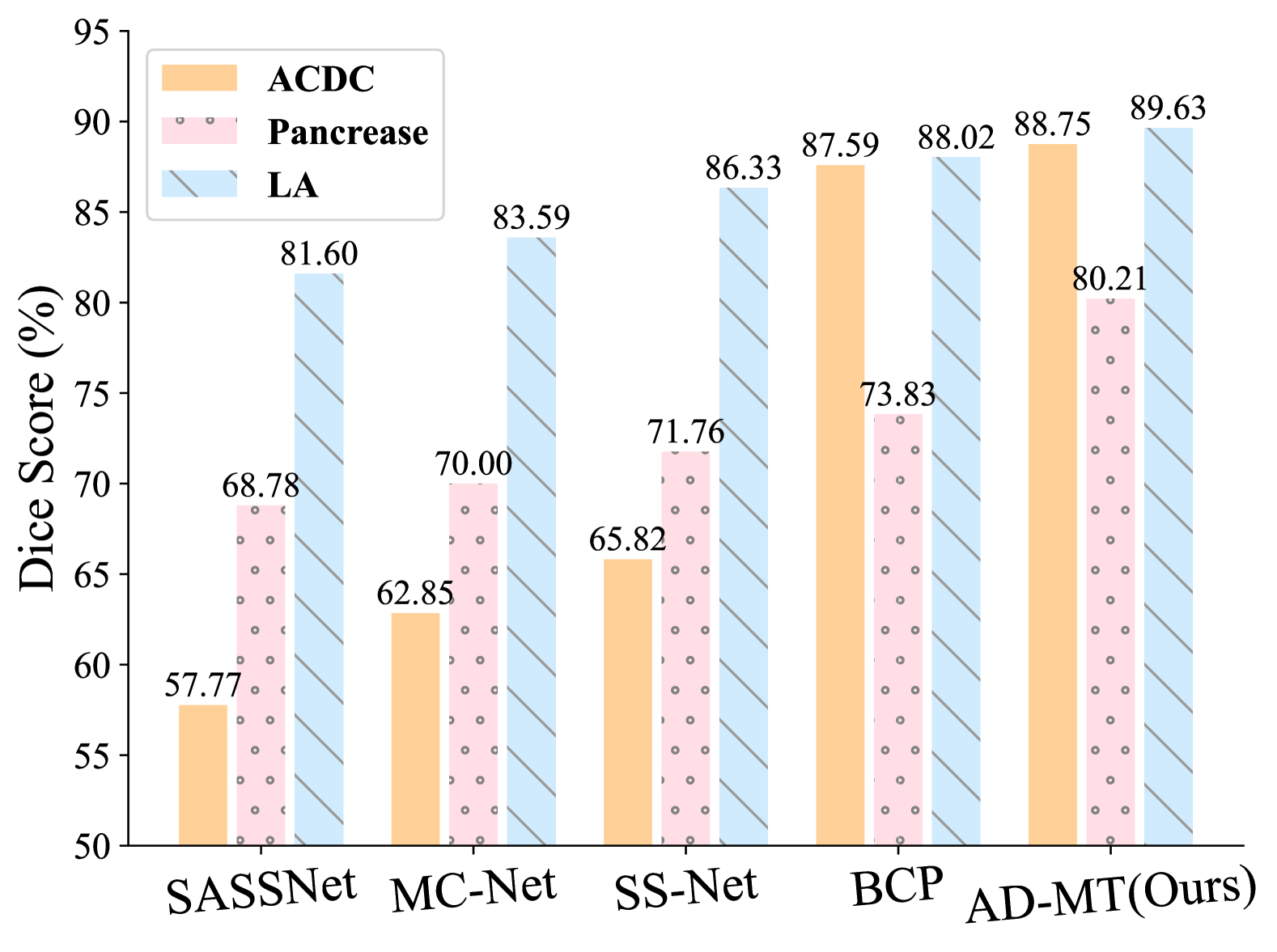
The authors evaluate their method on several medical image segmentation datasets, including brain MRI, cardiac MRI, and abdominal CT scans. They compare the performance of the ADT method to traditional single-teacher approaches, as well as other semi-supervised learning techniques, and demonstrate significant improvements, especially when the amount of labeled data is small.
Critical Analysis
The Alternate Diverse Teaching method presents a promising approach to address the data scarcity challenge in medical image segmentation. By leveraging multiple teacher models with diverse predictions, the method can effectively utilize both labeled and unlabeled data to train a more accurate segmentation model.
One potential limitation of the approach is the computational and storage overhead required to train and maintain multiple teacher models. The authors acknowledge this and suggest that future work could explore strategies to reduce the complexity, such as knowledge distillation or cross-model mutual learning.
Additionally, the authors note that the performance of the ADT method is dependent on the diversity and quality of the teacher models. Carefully designing and selecting the teacher models is crucial for the success of the approach. Further research could investigate automated methods for generating diverse and complementary teacher models.
Overall, the Alternate Diverse Teaching method presents a compelling solution to the semi-supervised medical image segmentation problem and opens up new directions for leveraging the strengths of multiple models in a teacher-student framework.
Conclusion
The Alternate Diverse Teaching (ADT) method proposed in this paper offers a novel approach to training accurate medical image segmentation models using a combination of limited labeled data and abundant unlabeled data. By having multiple teacher models provide diverse predictions, the student model can learn a more robust and generalizable segmentation algorithm, overcoming the challenges of data scarcity in the medical domain.
The results demonstrate the effectiveness of the ADT method, which outperforms traditional single-teacher approaches and other semi-supervised learning techniques, especially when the labeled data is scarce. This work contributes to the growing body of research on leveraging unlabeled data and model diversity for efficient and accurate medical image analysis, with potential applications in disease diagnosis, treatment planning, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Alternate Diverse Teaching for Semi-supervised Medical Image Segmentation
Zhen Zhao, Zicheng Wang, Longyue Wang, Dian Yu, Yixuan Yuan, Luping Zhou
Semi-supervised medical image segmentation studies have shown promise in training models with limited labeled data. However, current dominant teacher-student based approaches can suffer from the confirmation bias. To address this challenge, we propose AD-MT, an alternate diverse teaching approach in a teacher-student framework. It involves a single student model and two non-trainable teacher models that are momentum-updated periodically and randomly in an alternate fashion. To mitigate the confirmation bias from the diverse supervision, the core of AD-MT lies in two proposed modules: the Random Periodic Alternate (RPA) Updating Module and the Conflict-Combating Module (CCM). The RPA schedules the alternating diverse updating process with complementary data batches, distinct data augmentation, and random switching periods to encourage diverse reasoning from different teaching perspectives. The CCM employs an entropy-based ensembling strategy to encourage the model to learn from both the consistent and conflicting predictions between the teachers. Experimental results demonstrate the effectiveness and superiority of our AD-MT on the 2D and 3D medical segmentation benchmarks across various semi-supervised settings.
Read more7/15/2024

0
PMT: Progressive Mean Teacher via Exploring Temporal Consistency for Semi-Supervised Medical Image Segmentation
Ning Gao, Sanping Zhou, Le Wang, Nanning Zheng
Semi-supervised learning has emerged as a widely adopted technique in the field of medical image segmentation. The existing works either focuses on the construction of consistency constraints or the generation of pseudo labels to provide high-quality supervisory signals, whose main challenge mainly comes from how to keep the continuous improvement of model capabilities. In this paper, we propose a simple yet effective semi-supervised learning framework, termed Progressive Mean Teachers (PMT), for medical image segmentation, whose goal is to generate high-fidelity pseudo labels by learning robust and diverse features in the training process. Specifically, our PMT employs a standard mean teacher to penalize the consistency of the current state and utilizes two sets of MT architectures for co-training. The two sets of MT architectures are individually updated for prolonged periods to maintain stable model diversity established through performance gaps generated by iteration differences. Additionally, a difference-driven alignment regularizer is employed to expedite the alignment of lagging models with the representation capabilities of leading models. Furthermore, a simple yet effective pseudo-label filtering algorithm is employed for facile evaluation of models and selection of high-fidelity pseudo-labels outputted when models are operating at high performance for co-training purposes. Experimental results on two datasets with different modalities, i.e., CT and MRI, demonstrate that our method outperforms the state-of-the-art medical image segmentation approaches across various dimensions. The code is available at https://github.com/Axi404/PMT.
Read more9/17/2024

0
Mitigating Accuracy-Robustness Trade-off via Balanced Multi-Teacher Adversarial Distillation
Shiji Zhao, Xizhe Wang, Xingxing Wei
Adversarial Training is a practical approach for improving the robustness of deep neural networks against adversarial attacks. Although bringing reliable robustness, the performance towards clean examples is negatively affected after Adversarial Training, which means a trade-off exists between accuracy and robustness. Recently, some studies have tried to use knowledge distillation methods in Adversarial Training, achieving competitive performance in improving the robustness but the accuracy for clean samples is still limited. In this paper, to mitigate the accuracy-robustness trade-off, we introduce the Balanced Multi-Teacher Adversarial Robustness Distillation (B-MTARD) to guide the model's Adversarial Training process by applying a strong clean teacher and a strong robust teacher to handle the clean examples and adversarial examples, respectively. During the optimization process, to ensure that different teachers show similar knowledge scales, we design the Entropy-Based Balance algorithm to adjust the teacher's temperature and keep the teachers' information entropy consistent. Besides, to ensure that the student has a relatively consistent learning speed from multiple teachers, we propose the Normalization Loss Balance algorithm to adjust the learning weights of different types of knowledge. A series of experiments conducted on three public datasets demonstrate that B-MTARD outperforms the state-of-the-art methods against various adversarial attacks.
Read more6/18/2024

0
Adaptive Mix for Semi-Supervised Medical Image Segmentation
Zhiqiang Shen, Peng Cao, Junming Su, Jinzhu Yang, Osmar R. Zaiane
Mix-up is a key technique for consistency regularization-based semi-supervised learning methods, generating strong-perturbed samples for strong-weak pseudo-supervision. Existing mix-up operations are performed either randomly or with predefined rules, such as replacing low-confidence patches with high-confidence ones. The former lacks control over the perturbation degree, leading to overfitting on randomly perturbed samples, while the latter tends to generate images with trivial perturbations, both of which limit the effectiveness of consistency learning. This paper aims to answer the following question: How can image mix-up perturbation be adaptively performed during training? To this end, we propose an Adaptive Mix algorithm (AdaMix) for image mix-up in a self-paced learning manner. Given that, in general, a model's performance gradually improves during training, AdaMix is equipped with a self-paced curriculum that, in the initial training stage, provides relatively simple perturbed samples and then gradually increases the difficulty of perturbed images by adaptively controlling the perturbation degree based on the model's learning state estimated by a self-paced regularize. We develop three frameworks with our AdaMix, i.e., AdaMix-ST, AdaMix-MT, and AdaMix-CT, for semi-supervised medical image segmentation. Extensive experiments on three public datasets, including both 2D and 3D modalities, show that the proposed frameworks are capable of achieving superior performance. For example, compared with the state-of-the-art, AdaMix-CT achieves relative improvements of 2.62% in Dice and 48.25% in average surface distance on the ACDC dataset with 10% labeled data. The results demonstrate that mix-up operations with dynamically adjusted perturbation strength based on the segmentation model's state can significantly enhance the effectiveness of consistency regularization.
Read more8/1/2024