PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
2312.03490
0
0
💬
Abstract
The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Create account to get full access
Overview
- The conventional method of pretraining and then fine-tuning machine learning models faces challenges when diagnosing rare occupational diseases like pneumoconiosis due to limited training data.
- Recent advancements in large language models (LLMs) have shown promising results in conducting multiple tasks through dialogue, suggesting opportunities for disease diagnosis.
- The paper proposes a novel approach that eliminates the text branch and substitutes the dialogue head with a classification head, allowing for more effective use of LLMs with fewer learnable parameters.
- Additionally, the paper introduces the contextual multi-token engine and the information emitter module to balance detailed image information with accurate diagnosis.
Plain English Explanation
The traditional way of training machine learning models involves first pretraining them on a large dataset, then fine-tuning them for a specific task. This approach works well for common diseases with plenty of data, but it struggles when it comes to diagnosing rare occupational diseases like pneumoconiosis, which have limited training data available.
Recently, researchers have been exploring the use of large language models (LLMs) in healthcare applications, including automated clinical data extraction and disease prediction. These models have shown impressive abilities in handling multiple tasks through dialogue, suggesting they could be useful for diagnosing rare diseases.
The researchers in this paper propose a new approach that simplifies the model architecture by removing the text branch and replacing the dialogue head with a classification head. This allows the model to use the power of LLMs more effectively, especially when working with limited training data.
To balance the need for detailed image information with the goal of accurate diagnosis, the researchers introduce two specialized modules: the contextual multi-token engine and the information emitter module. The contextual multi-token engine is designed to generate diagnostic tokens adaptively, while the information emitter module transfers information from image tokens to the diagnostic tokens.
Through comprehensive experiments, the researchers demonstrate the superiority of their methods and the effectiveness of the proposed modules.
Technical Explanation
The paper addresses the challenges faced by the conventional pretraining-and-finetuning approach when diagnosing rare occupational diseases like pneumoconiosis, which often have limited training data available.
To overcome these challenges, the researchers leverage the recent advancements in large language models (LLMs) and their ability to handle multiple tasks through dialogue. However, the researchers note that a common strategy of using adapter layers for vision-language alignment and diagnosis often requires optimization of extensive learnable parameters in the text branch and the dialogue head, which can diminish the LLMs' efficacy, especially with limited training data.
To address this issue, the researchers innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters.
Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, the researchers introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, the researchers propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens.
Comprehensive experiments validate the superiority of the researchers' methods and the effectiveness of the proposed modules.
Critical Analysis
The paper presents a novel approach to leveraging LLMs for the diagnosis of rare occupational diseases, which is a significant challenge in the field of healthcare AI. The researchers' decision to simplify the model architecture by removing the text branch and replacing the dialogue head with a classification head is a pragmatic solution that addresses the limitations of the conventional pretraining-and-finetuning paradigm.
However, the paper could have provided more detailed information on the specific challenges faced when diagnosing rare occupational diseases, as well as the limitations of the current state-of-the-art approaches. Additionally, the researchers could have discussed the potential ethical implications of using LLMs for medical diagnosis, such as concerns around bias, interpretability, and patient privacy.
While the researchers demonstrate the effectiveness of their approach through comprehensive experiments, it would be valuable to see how their model performs on real-world clinical data and in comparison to human experts. This would provide a more realistic assessment of the model's capabilities and limitations.
Furthermore, the researchers could have explored the potential for their approach to be applied to other rare or data-scarce medical conditions, as the principles underlying their innovation may be transferable to other domains.
Conclusion
The paper presents a novel approach to leveraging large language models (LLMs) for the diagnosis of rare occupational diseases, which are challenging to diagnose due to limited training data. The researchers' innovative solution of simplifying the model architecture and introducing specialized modules, such as the contextual multi-token engine and the information emitter module, demonstrates the potential for LLMs to be effectively utilized in healthcare applications with data-scarce scenarios.
The comprehensive experiments conducted by the researchers validate the superiority of their methods and the effectiveness of the proposed modules. While the paper raises interesting questions and provides a promising direction for future research, further exploration of the real-world clinical implications and broader applicability of the approach would be valuable to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
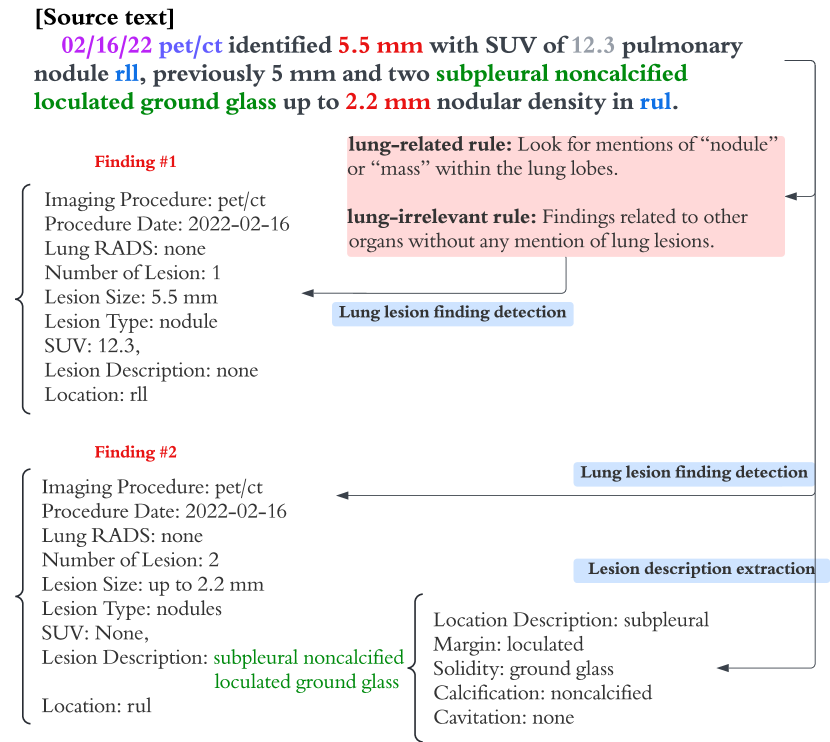
Automated Clinical Data Extraction with Knowledge Conditioned LLMs
Diya Li, Asim Kadav, Aijing Gao, Rui Li, Richard Bourgon
0
0
The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
6/27/2024
💬
Large Language Models for Medicine: A Survey
Yanxin Zheng, Wensheng Gan, Zefeng Chen, Zhenlian Qi, Qian Liang, Philip S. Yu
0
0
To address challenges in the digital economy's landscape of digital intelligence, large language models (LLMs) have been developed. Improvements in computational power and available resources have significantly advanced LLMs, allowing their integration into diverse domains for human life. Medical LLMs are essential application tools with potential across various medical scenarios. In this paper, we review LLM developments, focusing on the requirements and applications of medical LLMs. We provide a concise overview of existing models, aiming to explore advanced research directions and benefit researchers for future medical applications. We emphasize the advantages of medical LLMs in applications, as well as the challenges encountered during their development. Finally, we suggest directions for technical integration to mitigate challenges and potential research directions for the future of medical LLMs, aiming to meet the demands of the medical field better.
5/24/2024

Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
Yubin Kim, Xuhai Xu, Daniel McDuff, Cynthia Breazeal, Hae Won Park
0
0
Large language models (LLMs) are capable of many natural language tasks, yet they are far from perfect. In health applications, grounding and interpreting domain-specific and non-linguistic data is crucial. This paper investigates the capacity of LLMs to make inferences about health based on contextual information (e.g. user demographics, health knowledge) and physiological data (e.g. resting heart rate, sleep minutes). We present a comprehensive evaluation of 12 state-of-the-art LLMs with prompting and fine-tuning techniques on four public health datasets (PMData, LifeSnaps, GLOBEM and AW_FB). Our experiments cover 10 consumer health prediction tasks in mental health, activity, metabolic, and sleep assessment. Our fine-tuned model, HealthAlpaca exhibits comparable performance to much larger models (GPT-3.5, GPT-4 and Gemini-Pro), achieving the best performance in 8 out of 10 tasks. Ablation studies highlight the effectiveness of context enhancement strategies. Notably, we observe that our context enhancement can yield up to 23.8% improvement in performance. While constructing contextually rich prompts (combining user context, health knowledge and temporal information) exhibits synergistic improvement, the inclusion of health knowledge context in prompts significantly enhances overall performance.
4/30/2024