Automated Clinical Data Extraction with Knowledge Conditioned LLMs
2406.18027
0
0
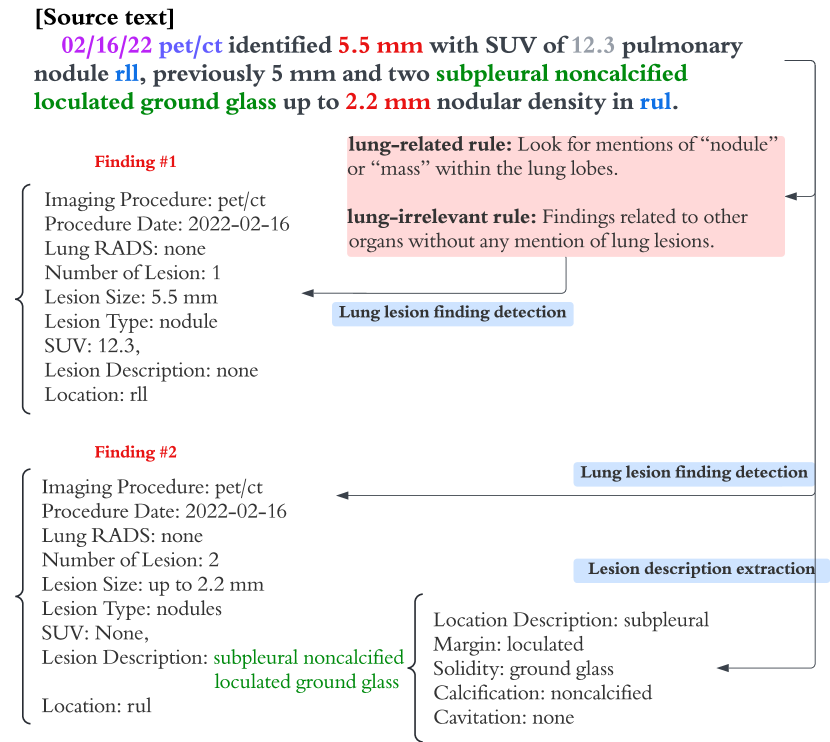
Abstract
The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
Create account to get full access
Overview
- The paper introduces a new approach to automated clinical data extraction using large language models (LLMs) conditioned on medical knowledge.
- The proposed method combines the power of LLMs with targeted domain-specific knowledge to improve the accuracy and reliability of medical data extraction from clinical notes and reports.
- The research explores the benefits of guiding clinical reasoning with LLMs and harnessing knowledge retrieval in LLMs for clinical data extraction tasks.
Plain English Explanation
The paper presents a new way to automatically extract important medical information from clinical documents like doctor's notes and reports. The researchers use large language models (LLMs) - powerful AI systems that can understand and generate human-like text. However, they don't just use the LLM on its own. Instead, they "condition" the LLM by giving it access to medical knowledge and information.
This helps the LLM better understand the clinical context and extract the most relevant data, such as a patient's symptoms, diagnoses, or treatment plans. By combining the LLM's natural language processing capabilities with targeted medical knowledge, the researchers aim to create a more accurate and reliable system for automating the extraction of critical clinical data.
This work builds on previous research exploring how to guide clinical reasoning with LLMs and harness knowledge retrieval in LLMs for clinical tasks. The goal is to develop AI tools that can assist healthcare professionals by automating the tedious process of extracting important information from medical records, allowing them to focus more on patient care.
Technical Explanation
The paper presents a novel approach to automated clinical data extraction that leverages large language models (LLMs) conditioned on medical knowledge. The researchers hypothesize that by equipping LLMs with targeted domain-specific information, the models can more accurately and reliably extract critical data from clinical notes and reports.
The proposed method involves fine-tuning a pretrained LLM on a curated medical knowledge base, which allows the model to develop a deeper understanding of clinical concepts and terminology. This "knowledge-conditioned" LLM is then used to perform various clinical data extraction tasks, such as identifying symptoms, diagnoses, and treatments from unstructured text.
The researchers evaluate their approach on several benchmark datasets and compare its performance to that of other state-of-the-art clinical information extraction systems. The results demonstrate the benefits of the knowledge-conditioned LLM approach, showing improved accuracy and robustness compared to models that do not have access to the same medical knowledge.
This work builds on previous research in the field, including guiding clinical reasoning with LLMs and harnessing knowledge retrieval in LLMs for clinical applications. By integrating domain-specific knowledge with the powerful language understanding capabilities of LLMs, the researchers aim to develop more effective tools for automating the extraction of critical information from clinical data.
Critical Analysis
The paper presents a promising approach to improving the accuracy and reliability of automated clinical data extraction using knowledge-conditioned LLMs. However, the researchers acknowledge several limitations and areas for further investigation.
One key limitation is the reliance on a curated medical knowledge base, which may not capture the full breadth and complexity of clinical knowledge. As noted in the exploration of large language models as clinical reasoners, LLMs can sometimes exhibit biases or inconsistencies in their understanding of medical concepts. Further research is needed to assess the generalizability of the knowledge-conditioning approach across diverse clinical domains and data sources.
Additionally, the paper does not address the potential challenges of deploying such a system in real-world healthcare settings, where data privacy, security, and integration with existing clinical workflows must be carefully considered. Exploring the integration of AI models like this into clinical decision support systems could provide valuable insights in this regard.
Overall, the research presented in the paper represents an important step forward in the development of more accurate and reliable clinical data extraction tools. However, continued innovation and thoughtful implementation will be crucial to ensuring the safe and effective deployment of such technologies in healthcare settings.
Conclusion
This paper introduces a novel approach to automated clinical data extraction that leverages large language models (LLMs) conditioned on medical knowledge. By equipping LLMs with targeted domain-specific information, the researchers demonstrate improved accuracy and reliability in extracting critical data from clinical notes and reports.
The proposed method builds on previous research in guiding clinical reasoning with LLMs and harnessing knowledge retrieval in LLMs for clinical applications. By integrating powerful language understanding capabilities with medical knowledge, the researchers aim to develop more effective tools for automating the extraction of important information from clinical data.
While the paper presents promising results, the researchers also acknowledge several limitations and areas for further investigation, such as the generalizability of the knowledge-conditioning approach and the challenges of deploying such a system in real-world healthcare settings. Continued research and thoughtful implementation will be crucial to ensuring the safe and effective use of these technologies in supporting healthcare professionals and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
XAI4LLM. Let Machine Learning Models and LLMs Collaborate for Enhanced In-Context Learning in Healthcare
Fatemeh Nazary, Yashar Deldjoo, Tommaso Di Noia, Eugenio di Sciascio
0
0
The integration of Large Language Models (LLMs) into healthcare diagnostics offers a promising avenue for clinical decision-making. This study outlines the development of a novel method for zero-shot/few-shot in-context learning (ICL) by integrating medical domain knowledge using a multi-layered structured prompt. We also explore the efficacy of two communication styles between the user and LLMs: the Numerical Conversational (NC) style, which processes data incrementally, and the Natural Language Single-Turn (NL-ST) style, which employs long narrative prompts. Our study systematically evaluates the diagnostic accuracy and risk factors, including gender bias and false negative rates, using a dataset of 920 patient records in various few-shot scenarios. Results indicate that traditional clinical machine learning (ML) models generally outperform LLMs in zero-shot and few-shot settings. However, the performance gap narrows significantly when employing few-shot examples alongside effective explainable AI (XAI) methods as sources of domain knowledge. Moreover, with sufficient time and an increased number of examples, the conversational style (NC) nearly matches the performance of ML models. Most notably, LLMs demonstrate comparable or superior cost-sensitive accuracy relative to ML models. This research confirms that, with appropriate domain knowledge and tailored communication strategies, LLMs can significantly enhance diagnostic processes. The findings highlight the importance of optimizing the number of training examples and communication styles to improve accuracy and reduce biases in LLM applications.
6/4/2024
Harnessing Knowledge Retrieval with Large Language Models for Clinical Report Error Correction
Jinge Wu, Zhaolong Wu, Abul Hasan, Yunsoo Kim, Jason P. Y. Cheung, Teng Zhang, Honghan Wu
0
0
This study proposes an approach for error correction in clinical radiology reports, leveraging large language models (LLMs) and retrieval-augmented generation (RAG) techniques. The proposed framework employs internal and external retrieval mechanisms to extract relevant medical entities and relations from the report and external knowledge sources. A three-stage inference process is introduced, decomposing the task into error detection, localization, and correction subtasks, which enhances the explainability and performance of the system. The effectiveness of the approach is evaluated using a benchmark dataset created by corrupting real-world radiology reports with realistic errors, guided by domain experts. Experimental results demonstrate the benefits of the proposed methods, with the combination of internal and external retrieval significantly improving the accuracy of error detection, localization, and correction across various state-of-the-art LLMs. The findings contribute to the development of more robust and reliable error correction systems for clinical documentation.
6/24/2024

IITK at SemEval-2024 Task 2: Exploring the Capabilities of LLMs for Safe Biomedical Natural Language Inference for Clinical Trials
Shreyasi Mandal, Ashutosh Modi
0
0
Large Language models (LLMs) have demonstrated state-of-the-art performance in various natural language processing (NLP) tasks across multiple domains, yet they are prone to shortcut learning and factual inconsistencies. This research investigates LLMs' robustness, consistency, and faithful reasoning when performing Natural Language Inference (NLI) on breast cancer Clinical Trial Reports (CTRs) in the context of SemEval 2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials. We examine the reasoning capabilities of LLMs and their adeptness at logical problem-solving. A comparative analysis is conducted on pre-trained language models (PLMs), GPT-3.5, and Gemini Pro under zero-shot settings using Retrieval-Augmented Generation (RAG) framework, integrating various reasoning chains. The evaluation yields an F1 score of 0.69, consistency of 0.71, and a faithfulness score of 0.90 on the test dataset.
4/9/2024
💬
New!PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Meiyue Song, Zhihua Yu, Jiaxin Wang, Jiarui Wang, Yuting Lu, Baicun Li, Xiaoxu Wang, Qinghua Huang, Zhijun Li, Nikolaos I. Kanellakis, Jiangfeng Liu, Jing Wang, Binglu Wang, Juntao Yang
0
0
The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
7/2/2024