PointSeg: A Training-Free Paradigm for 3D Scene Segmentation via Foundation Models

0

Sign in to get full access
Overview
- Introduces a novel 3D scene segmentation method called PointSeg that uses foundation models instead of requiring training
- Leverages pretrained language models and point cloud encoders to perform segmentation without any task-specific training
- Achieves state-of-the-art performance on several 3D segmentation benchmarks, outperforming supervised methods
Plain English Explanation
The paper presents PointSeg, a new approach to 3D scene segmentation that doesn't require any task-specific training. Instead, it relies on foundation models - pre-trained language models and point cloud encoders - to perform the segmentation in a
The key idea is to use the rich semantic understanding captured by these foundation models to connect and group points in the 3D scene, without the need for specialized training on segmentation datasets. The method works by first encoding the 3D point cloud using a pre-trained point cloud encoder, then using a bidirectional matching process to associate points with semantic concepts. An iterative post-refinement step and an affinity-aware merging algorithm are then used to generate the final segmentation.
By avoiding the need for task-specific training, PointSeg can be readily applied to new scenes and datasets without the burden of data collection and annotation. This makes it a promising approach for real-world applications that require rapid deployment and adaptation to diverse environments.
Technical Explanation
The PointSeg method first encodes the input 3D point cloud using a pre-trained point cloud encoder (e.g., PointNet or DGCNN). This produces a set of feature embeddings for each point in the scene.
Next, a bidirectional matching process is used to associate the point features with semantic concepts from a pre-trained language model (e.g., BERT or GPT). This allows the method to leverage the rich semantic knowledge encoded in the language model to understand the 3D scene.
An iterative post-refinement step is then applied to refine the point-concept associations, gradually improving the segmentation quality. Finally, an affinity-aware merging algorithm is used to group the points into the final segmented regions, taking into account both the semantic and spatial affinities between points.
The key advantages of PointSeg are its ability to perform 3D scene segmentation without any task-specific training, and its strong performance on several benchmark datasets, outperforming supervised methods in many cases.
Critical Analysis
The paper provides a thorough evaluation of PointSeg, demonstrating its effectiveness on a range of 3D segmentation benchmarks. However, the authors acknowledge several limitations and areas for future work:
- The method's performance is still lower than the best supervised methods in certain challenging scenarios, suggesting room for improvement.
- The reliance on pre-trained foundation models means the performance is inherently limited by the quality and coverage of these models, which may not generalize well to all types of 3D scenes.
- The iterative post-refinement and affinity-aware merging steps are computationally expensive, which could limit the method's scalability to large-scale scenes.
Additionally, while the training-free aspect of PointSeg is a significant strength, it also raises questions about the method's ability to adapt to novel environments or specific user requirements. The authors do not extensively discuss how the foundation models could be fine-tuned or adapted for such scenarios.
Overall, PointSeg represents an exciting step towards more flexible and efficient 3D scene understanding, but further research is needed to address the identified limitations and expand the method's applicability.
Conclusion
The PointSeg paper introduces a novel approach to 3D scene segmentation that leverages pre-trained foundation models to perform the task in a training-free manner. By avoiding the need for specialized training data and annotation, the method offers a more flexible and scalable solution compared to traditional supervised techniques.
The strong performance of PointSeg on several benchmarks, outperforming state-of-the-art supervised methods, highlights the potential of this training-free paradigm for 3D scene understanding. This work contributes to the ongoing efforts to develop more adaptable and efficient AI systems for real-world applications, where rapid deployment and adaptation to diverse environments are crucial.
While the method has some limitations that require further research, the PointSeg paper represents an important step forward in the field of 3D scene segmentation and the broader goal of building more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PointSeg: A Training-Free Paradigm for 3D Scene Segmentation via Foundation Models
Qingdong He, Jinlong Peng, Zhengkai Jiang, Xiaobin Hu, Jiangning Zhang, Qiang Nie, Yabiao Wang, Chengjie Wang
Recent success of vision foundation models have shown promising performance for the 2D perception tasks. However, it is difficult to train a 3D foundation network directly due to the limited dataset and it remains under explored whether existing foundation models can be lifted to 3D space seamlessly. In this paper, we present PointSeg, a novel training-free paradigm that leverages off-the-shelf vision foundation models to address 3D scene perception tasks. PointSeg can segment anything in 3D scene by acquiring accurate 3D prompts to align their corresponding pixels across frames. Concretely, we design a two-branch prompts learning structure to construct the 3D point-box prompts pairs, combining with the bidirectional matching strategy for accurate point and proposal prompts generation. Then, we perform the iterative post-refinement adaptively when cooperated with different vision foundation models. Moreover, we design a affinity-aware merging algorithm to improve the final ensemble masks. PointSeg demonstrates impressive segmentation performance across various datasets, all without training. Specifically, our approach significantly surpasses the state-of-the-art specialist training-free model by 14.1$%$, 12.3$%$, and 12.6$%$ mAP on ScanNet, ScanNet++, and KITTI-360 datasets, respectively. On top of that, PointSeg can incorporate with various foundation models and even surpasses the specialist training-based methods by 3.4$%$-5.4$%$ mAP across various datasets, serving as an effective generalist model.
Read more7/19/2024

0
SegPoint: Segment Any Point Cloud via Large Language Model
Shuting He, Henghui Ding, Xudong Jiang, Bihan Wen
Despite significant progress in 3D point cloud segmentation, existing methods primarily address specific tasks and depend on explicit instructions to identify targets, lacking the capability to infer and understand implicit user intentions in a unified framework. In this work, we propose a model, called SegPoint, that leverages the reasoning capabilities of a multi-modal Large Language Model (LLM) to produce point-wise segmentation masks across a diverse range of tasks: 1) 3D instruction segmentation, 2) 3D referring segmentation, 3) 3D semantic segmentation, and 4) 3D open-vocabulary semantic segmentation. To advance 3D instruction research, we introduce a new benchmark, Instruct3D, designed to evaluate segmentation performance from complex and implicit instructional texts, featuring 2,565 point cloud-instruction pairs. Our experimental results demonstrate that SegPoint achieves competitive performance on established benchmarks such as ScanRefer for referring segmentation and ScanNet for semantic segmentation, while delivering outstanding outcomes on the Instruct3D dataset. To our knowledge, SegPoint is the first model to address these varied segmentation tasks within a single framework, achieving satisfactory performance.
Read more7/19/2024
🖼️
0
Towards Training-free Open-world Segmentation via Image Prompt Foundation Models
Lv Tang, Peng-Tao Jiang, Hao-Ke Xiao, Bo Li
The realm of computer vision has witnessed a paradigm shift with the advent of foundational models, mirroring the transformative influence of large language models in the domain of natural language processing. This paper delves into the exploration of open-world segmentation, presenting a novel approach called Image Prompt Segmentation (IPSeg) that harnesses the power of vision foundational models. IPSeg lies the principle of a training-free paradigm, which capitalizes on image prompt techniques. Specifically, IPSeg utilizes a single image containing a subjective visual concept as a flexible prompt to query vision foundation models like DINOv2 and Stable Diffusion. Our approach extracts robust features for the prompt image and input image, then matches the input representations to the prompt representations via a novel feature interaction module to generate point prompts highlighting target objects in the input image. The generated point prompts are further utilized to guide the Segment Anything Model to segment the target object in the input image. The proposed method stands out by eliminating the need for exhaustive training sessions, thereby offering a more efficient and scalable solution. Experiments on COCO, PASCAL VOC, and other datasets demonstrate IPSeg's efficacy for flexible open-world segmentation using intuitive image prompts. This work pioneers tapping foundation models for open-world understanding through visual concepts conveyed in images.
Read more6/27/2024
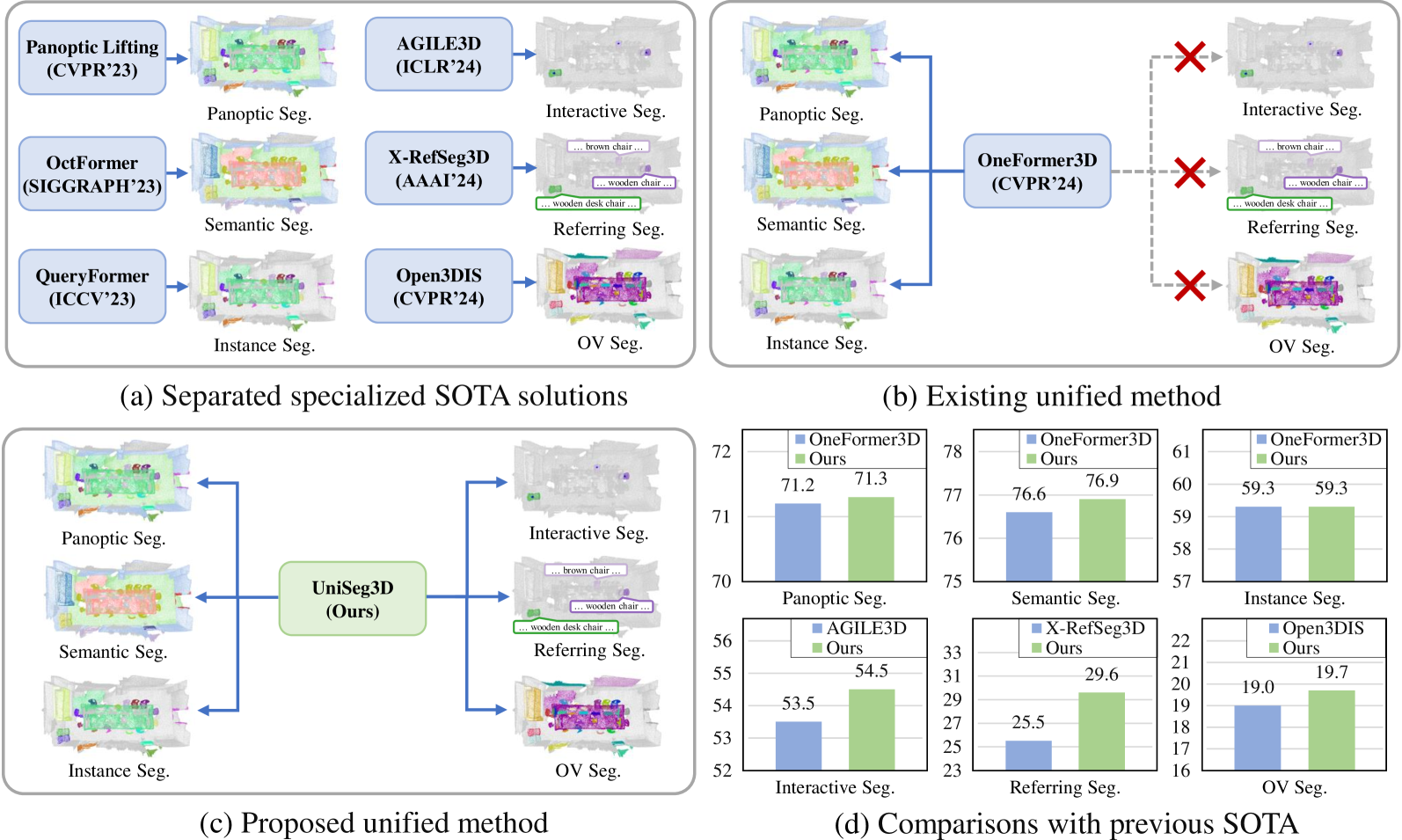
0
A Unified Framework for 3D Scene Understanding
Wei Xu, Chunsheng Shi, Sifan Tu, Xin Zhou, Dingkang Liang, Xiang Bai
We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.
Read more7/4/2024