PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science

0

Sign in to get full access
Overview
- Introduces a framework called PoliPrompt for high-performance, cost-effective text classification using large language models (LLMs) in political science research.
- Demonstrates the effectiveness of PoliPrompt on several political text classification tasks.
- Highlights the advantages of PoliPrompt over traditional supervised learning approaches in terms of performance, efficiency, and ease of use.
Plain English Explanation
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science presents a new way to analyze political texts using large language models (LLMs). LLMs are powerful AI systems that can understand and generate human-like text.
The researchers developed a framework called PoliPrompt that leverages LLMs to classify political texts into different categories, such as political ideology or party affiliation. This is useful for researchers studying political discourse, as it allows them to quickly and accurately categorize large amounts of text data.
Compared to traditional supervised learning approaches, PoliPrompt offers several advantages:
- Higher Performance: PoliPrompt achieves better accuracy on political text classification tasks than previous methods.
- Lower Cost: PoliPrompt is more cost-effective, as it doesn't require training large, specialized models from scratch.
- Easier to Use: PoliPrompt is designed to be user-friendly, making it accessible to researchers without extensive machine learning expertise.
By making political text analysis more efficient and accessible, PoliPrompt has the potential to accelerate research in political science and related fields.
Technical Explanation
The PoliPrompt framework leverages the power of large language models (LLMs) to perform high-performance, cost-effective text classification for political science research. The key elements of the framework include:
Architecture: PoliPrompt uses a "prompt-based" approach, where the LLM is fine-tuned on a small amount of labeled data and then used to classify new text by providing it with a carefully designed prompt. This avoids the need to train a large, specialized model from scratch.
Experiment Design: The researchers evaluate PoliPrompt on several political text classification tasks, including identifying political ideology, party affiliation, and policy positions. They compare PoliPrompt's performance to traditional supervised learning approaches and demonstrate its superior accuracy, efficiency, and ease of use.
Insights: The results show that PoliPrompt outperforms previous methods on a range of political text classification tasks, often by a significant margin. The framework is also more cost-effective, as it requires less computational resources and training data to achieve high performance.
Critical Analysis
The paper provides a compelling demonstration of the capabilities of PoliPrompt, but it also acknowledges some potential limitations and areas for further research:
- Generalizability: The paper focuses on a few specific political text classification tasks, and it's unclear how well PoliPrompt would generalize to other types of political texts or research questions.
- Interpretability: While PoliPrompt is effective, the inner workings of the LLM-based approach may be less interpretable than traditional supervised models, which could be a concern for some political science researchers.
- Ethical Considerations: The use of LLMs in political text analysis raises potential ethical concerns, such as the risk of amplifying biases or misinformation. The paper does not address these issues in depth.
Overall, the PoliPrompt framework represents an exciting development in the application of large language models to political science research. However, further research is needed to fully understand its capabilities, limitations, and potential implications.
Conclusion
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science introduces a novel approach to political text analysis that leverages the power of large language models. The framework demonstrates superior performance, efficiency, and ease of use compared to traditional supervised learning methods, potentially accelerating research in political science and related fields.
While the paper provides a strong technical and empirical foundation, it also highlights the need for further exploration of the generalizability, interpretability, and ethical considerations of using LLMs in this context. As the use of these advanced AI systems continues to expand, it will be crucial to address these concerns and ensure that the benefits of PoliPrompt are realized in a responsible and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science
Menglin Liu, Ge Shi
Recent advancements in large language models (LLMs) have opened new avenues for enhancing text classification efficiency in political science, surpassing traditional machine learning methods that often require extensive feature engineering, human labeling, and task-specific training. However, their effectiveness in achieving high classification accuracy remains questionable. This paper introduces a three-stage in-context learning approach that leverages LLMs to improve classification accuracy while minimizing experimental costs. Our method incorporates automatic enhanced prompt generation, adaptive exemplar selection, and a consensus mechanism that resolves discrepancies between two weaker LLMs, refined by an advanced LLM. We validate our approach using datasets from the BBC news reports, Kavanaugh Supreme Court confirmation, and 2018 election campaign ads. The results show significant improvements in classification F1 score (+0.36 for zero-shot classification) with manageable economic costs (-78% compared with human labeling), demonstrating that our method effectively addresses the limitations of traditional machine learning while offering a scalable and reliable solution for text analysis in political science.
Read more9/4/2024
👨🏫
0
Towards Human-Level Text Coding with LLMs: The Case of Fatherhood Roles in Public Policy Documents
Lorenzo Lupo, Oscar Magnusson, Dirk Hovy, Elin Naurin, Lena Wangnerud
Recent advances in large language models (LLMs) like GPT-3.5 and GPT-4 promise automation with better results and less programming, opening up new opportunities for text analysis in political science. In this study, we evaluate LLMs on three original coding tasks involving typical complexities encountered in political science settings: a non-English language, legal and political jargon, and complex labels based on abstract constructs. Along the paper, we propose a practical workflow to optimize the choice of the model and the prompt. We find that the best prompting strategy consists of providing the LLMs with a detailed codebook, as the one provided to human coders. In this setting, an LLM can be as good as or possibly better than a human annotator while being much faster, considerably cheaper, and much easier to scale to large amounts of text. We also provide a comparison of GPT and popular open-source LLMs, discussing the trade-offs in the model's choice. Our software allows LLMs to be easily used as annotators and is publicly available: https://github.com/lorelupo/pappa.
Read more8/29/2024
0
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
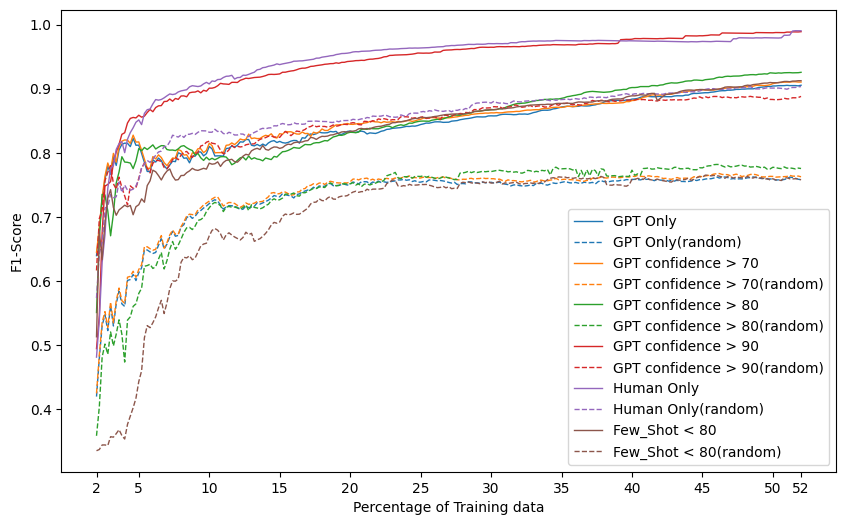
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
Read more6/19/2024
0
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
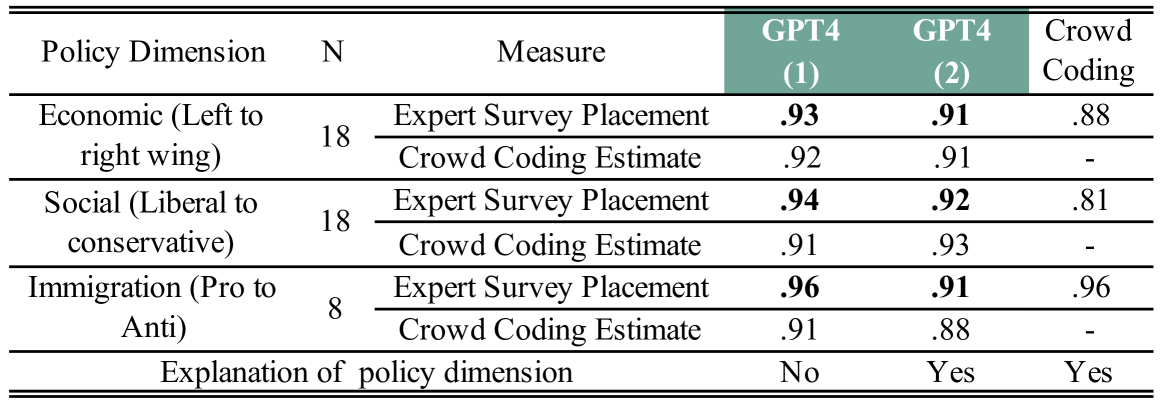
We use instruction-tuned Large Language Models (LLMs) like GPT-4, Llama 3, MiXtral, or Aya to position political texts within policy and ideological spaces. We ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to position political actors such as US Senators, or longer texts such as UK party manifestos or EU policy speeches given in 10 different languages. The correlations between the position estimates obtained with the best LLMs and benchmarks based on text coding by experts, crowdworkers, or roll call votes exceed .90. This approach is generally more accurate than the positions obtained with supervised classifiers trained on large amounts of research data. Using instruction-tuned LLMs to position texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Read more9/6/2024