PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
2404.04722
0
0

Abstract
Despite tremendous advancements in large language models (LLMs) over recent years, a notably urgent challenge for their practical deployment is the phenomenon of hallucination, where the model fabricates facts and produces non-factual statements. In response, we propose PoLLMgraph, a Polygraph for LLMs, as an effective model-based white-box detection and forecasting approach. PoLLMgraph distinctly differs from the large body of existing research that concentrates on addressing such challenges through black-box evaluations. In particular, we demonstrate that hallucination can be effectively detected by analyzing the LLM's internal state transition dynamics during generation via tractable probabilistic models. Experimental results on various open-source LLMs confirm the efficacy of PoLLMgraph, outperforming state-of-the-art methods by a considerable margin, evidenced by over 20% improvement in AUC-ROC on common benchmarking datasets like TruthfulQA. Our work paves a new way for model-based white-box analysis of LLMs, motivating the research community to further explore, understand, and refine the intricate dynamics of LLM behaviors.
Create account to get full access
Overview
- The paper introduces PoLLMgraph, a method for unraveling hallucinations in large language models (LLMs) by analyzing their state transition dynamics.
- Hallucinations refer to the generation of plausible-sounding but factually incorrect content by LLMs.
- PoLLMgraph aims to identify the root causes of hallucinations and provide insights into the internal workings of LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce content that is factually incorrect or nonsensical, a phenomenon known as "hallucinations." The researchers behind this paper have developed a method called PoLLMgraph to better understand how and why these hallucinations occur.
PoLLMgraph works by closely examining the internal states of the LLM as it generates text. By tracking how the model's internal representations change over time, the researchers can identify patterns that lead to hallucinations. This provides valuable insights into the inner workings of the LLM and can help us improve the reliability and trustworthiness of these models.
For example, PoLLMgraph might reveal that an LLM is more likely to hallucinate when it encounters certain types of input or when its internal states deviate too far from the training data. Armed with this knowledge, we can then develop strategies to mitigate these issues and create LLMs that are less prone to producing inaccurate or misleading content.
Overall, the PoLLMgraph approach represents an important step forward in our understanding of large language models and how to make them more robust and reliable. By shedding light on the root causes of hallucinations, this research could have significant implications for the development of safer and more trustworthy AI systems.
Technical Explanation
The paper introduces a novel method called PoLLMgraph (Probing Large Language Model Graph) for unraveling hallucinations in large language models (LLMs). Hallucinations refer to the generation of plausible-sounding but factually incorrect content by LLMs, which is a critical challenge in the deployment of these models.
PoLLMgraph works by analyzing the state transition dynamics of LLMs during text generation. The researchers propose a graph-based representation of the LLM's internal states, where nodes represent the model's hidden representations and edges capture the state transitions as the model generates text. By analyzing the structural properties of this graph, PoLLMgraph can identify the root causes of hallucinations and provide insights into the inner workings of the LLM.
The key steps of the PoLLMgraph approach are:
- Probing the LLM's internal states during text generation by periodically extracting the model's hidden representations.
- Constructing a graph-based representation of the state transitions, where nodes represent the model's hidden states and edges capture the transitions between them.
- Analyzing the structural properties of the graph, such as node centrality, to identify the critical states and transitions that contribute to hallucinations.
The researchers demonstrate the effectiveness of PoLLMgraph on several LLMs, including GPT-2 and GPT-3, and show that it can provide valuable insights into the inner workings of these models and the root causes of their hallucinations. The paper also discusses the potential applications of PoLLMgraph in improving the reliability and trustworthiness of large language models.
Critical Analysis
The PoLLMgraph approach represents an important step forward in understanding and mitigating the hallucination problem in large language models. By focusing on the dynamics of the model's internal states during text generation, the researchers are able to uncover insights that go beyond simply analyzing the model's output.
However, the paper also acknowledges several limitations and areas for further research. For example, the PoLLMgraph method is currently limited to analyzing the hidden representations of the LLM, and it does not directly consider the influence of the model's training data or other external factors that may contribute to hallucinations.
Additionally, while the paper demonstrates the effectiveness of PoLLMgraph on several LLMs, it remains to be seen how well the approach generalizes to a wider range of models and tasks. Further research is needed to understand the broader applicability and limitations of this method.
Another potential concern is the interpretability of the PoLLMgraph results. While the graph-based representation provides a structured way to analyze the LLM's internal states, the complexity of these models means that interpreting the underlying causes of hallucinations may still be a significant challenge.
Despite these limitations, the PoLLMgraph approach represents an important step forward in the ongoing efforts to improve the reliability and trustworthiness of large language models. By shedding light on the internal dynamics that lead to hallucinations, this research could inspire new strategies for model design, training, and deployment that are better equipped to handle the challenges of these powerful AI systems.
Conclusion
The PoLLMgraph method introduced in this paper offers a novel approach to unraveling hallucinations in large language models. By analyzing the state transition dynamics of LLMs during text generation, the researchers are able to identify the root causes of these hallucinations and gain valuable insights into the inner workings of these models.
The findings of this research could have significant implications for the development of more reliable and trustworthy AI systems. By better understanding the factors that contribute to hallucinations, we can work towards creating LLMs that are less prone to generating inaccurate or misleading content, and that can be more safely and effectively deployed in real-world applications.
While the PoLLMgraph method is not without its limitations, it represents an important step forward in the ongoing efforts to address the hallucination problem in large language models. As the field of AI continues to evolve, research like this will be crucial in helping us harness the power of these models while mitigating their potential risks and biases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran HU, Zhijing Wu, Yujia Zhou, Yiqun Liu
0
0
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
6/11/2024
Towards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework
Xiaoxi Sun, Jinpeng Li, Yan Zhong, Dongyan Zhao, Rui Yan
0
0
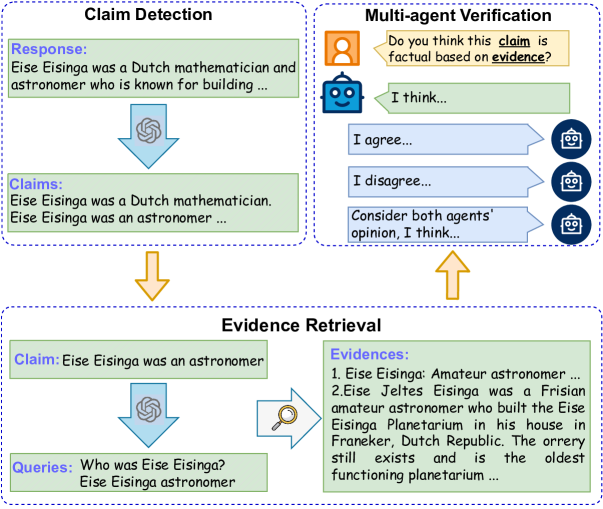
The advent of large language models (LLMs) has facilitated the development of natural language text generation. It also poses unprecedented challenges, with content hallucination emerging as a significant concern. Existing solutions often involve expensive and complex interventions during the training process. Moreover, some approaches emphasize problem disassembly while neglecting the crucial validation process, leading to performance degradation or limited applications. To overcome these limitations, we propose a Markov Chain-based multi-agent debate verification framework to enhance hallucination detection accuracy in concise claims. Our method integrates the fact-checking process, including claim detection, evidence retrieval, and multi-agent verification. In the verification stage, we deploy multiple agents through flexible Markov Chain-based debates to validate individual claims, ensuring meticulous verification outcomes. Experimental results across three generative tasks demonstrate that our approach achieves significant improvements over baselines.
6/6/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
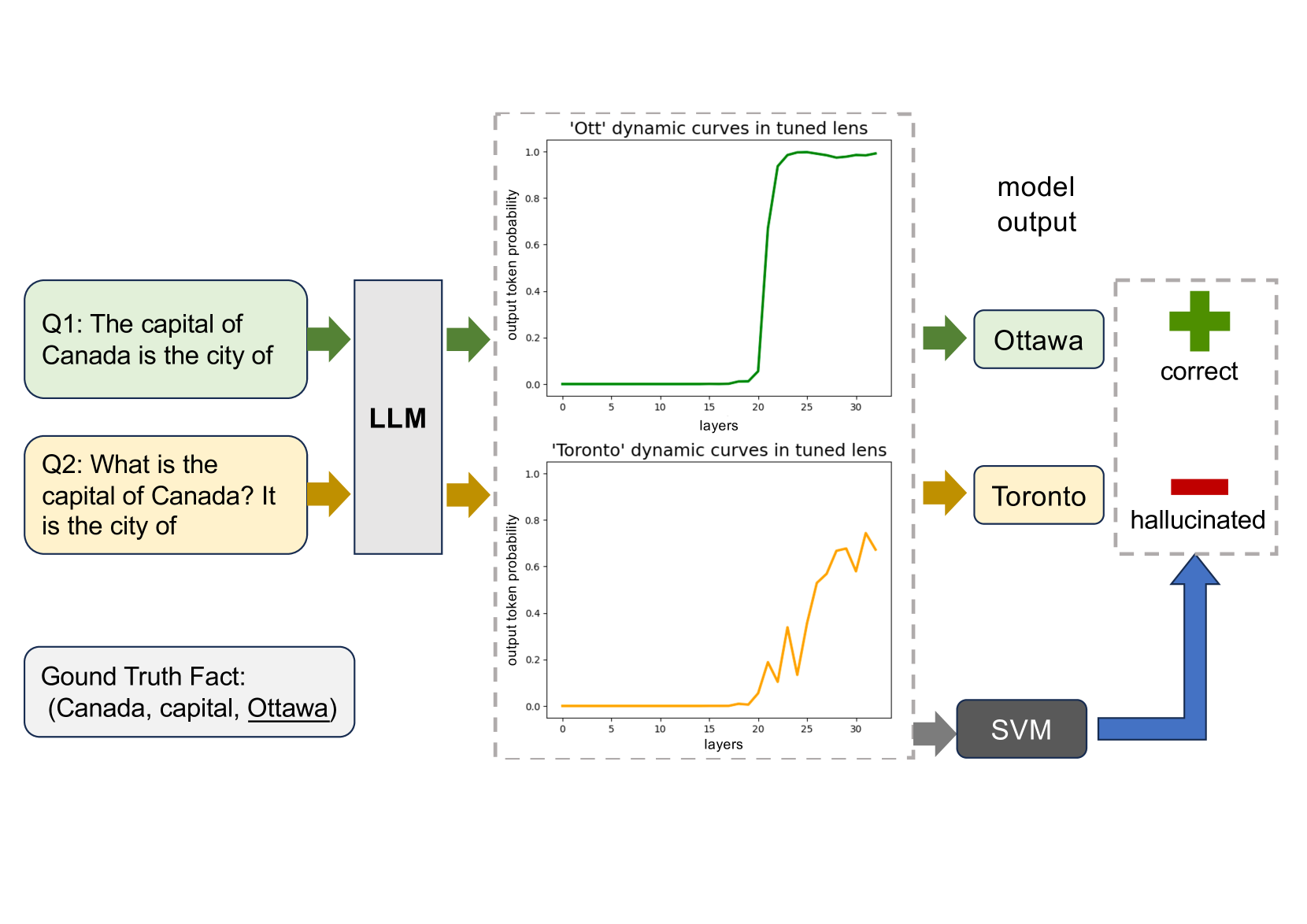
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024