Towards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework
2406.03075
0
0
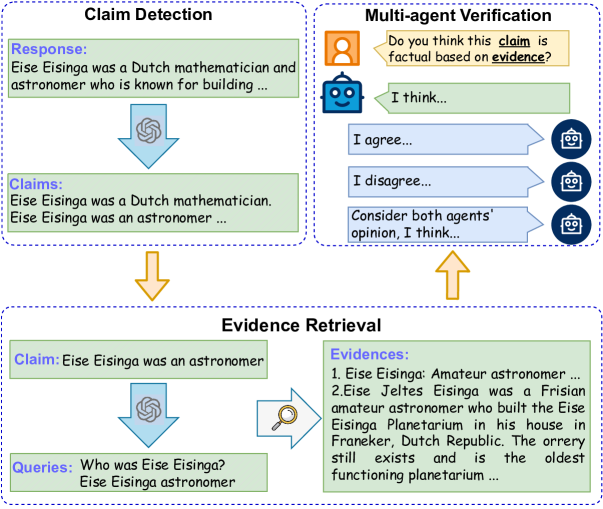
Abstract
The advent of large language models (LLMs) has facilitated the development of natural language text generation. It also poses unprecedented challenges, with content hallucination emerging as a significant concern. Existing solutions often involve expensive and complex interventions during the training process. Moreover, some approaches emphasize problem disassembly while neglecting the crucial validation process, leading to performance degradation or limited applications. To overcome these limitations, we propose a Markov Chain-based multi-agent debate verification framework to enhance hallucination detection accuracy in concise claims. Our method integrates the fact-checking process, including claim detection, evidence retrieval, and multi-agent verification. In the verification stage, we deploy multiple agents through flexible Markov Chain-based debates to validate individual claims, ensuring meticulous verification outcomes. Experimental results across three generative tasks demonstrate that our approach achieves significant improvements over baselines.
Create account to get full access
Overview
- This paper proposes a Markov Chain-based Multi-agent Debate Framework to detect hallucination in large language models (LLMs).
- Hallucination refers to the generation of false or nonsensical content by LLMs, which is a significant concern for the reliability and trustworthiness of these models.
- The authors aim to develop a framework that can effectively identify and mitigate hallucinations in LLM outputs.
Plain English Explanation
The paper is focused on addressing a critical issue with large language models (LLMs) - their tendency to generate false or nonsensical content, which is known as "hallucination." LLMs are powerful AI systems that can understand and generate human-like text, but they can sometimes output information that is completely made up or has no basis in reality.
To tackle this problem, the researchers have developed a new framework called the "Markov Chain-based Multi-agent Debate Framework." The key idea is to have two or more AI agents engage in a debate-like process to evaluate the truthfulness of the LLM's outputs. One agent will advocate for the output being truthful, while the other(s) will argue that it is a hallucination. By using a Markov Chain-based approach, the framework can systematically analyze the back-and-forth of the debate to determine the likelihood that the LLM's output is a hallucination.
The goal is to create a system that can reliably detect when an LLM is generating false or nonsensical content, which is crucial for building trust and ensuring the reliability of these powerful AI models. This research builds on previous work on hallucination detection and aims to provide a more robust and effective solution.
Technical Explanation
The paper presents a novel Markov Chain-based Multi-agent Debate Framework to detect hallucination in the outputs of large language models (LLMs). The framework involves two or more AI agents engaging in a debate-like process to evaluate the truthfulness of the LLM's outputs.
One agent, called the "Advocate," argues that the LLM's output is truthful, while the other agent(s), called the "Challenger(s)," argue that the output is a hallucination. The agents make their arguments by accessing external knowledge sources and engaging in a series of iterative exchanges.
The authors model this debate process as a Markov Chain, where each step in the debate represents a transition in the chain. By analyzing the probability distribution of the Markov Chain, the framework can estimate the likelihood that the LLM's output is a hallucination.
The authors evaluate their framework using a range of experiments, including hallucination detection tasks and comparisons to existing hallucination detection methods. The results demonstrate that the Markov Chain-based Multi-agent Debate Framework can effectively identify hallucinations in LLM outputs, outperforming other approaches.
Critical Analysis
The authors have proposed a promising approach to addressing the critical issue of hallucination in large language models. The Markov Chain-based Multi-agent Debate Framework provides a structured and systematic way to evaluate the truthfulness of LLM outputs, which is a significant advancement over existing methods that may be more heuristic or ad hoc.
However, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the framework relies on access to external knowledge sources, which may not always be available or reliable. Additionally, the debate process itself may be computationally expensive and may not scale well to large-scale LLM deployments.
Further research could explore ways to improve the efficiency and scalability of the framework, as well as investigate ways to integrate it more seamlessly with existing LLM architectures and workflows. It would also be interesting to see how the framework performs on a wider range of hallucination detection tasks and LLM models.
Conclusion
The Markov Chain-based Multi-agent Debate Framework proposed in this paper represents a significant step forward in addressing the hallucination problem in large language models. By leveraging a structured, multi-agent debate process, the framework can effectively identify when an LLM is generating false or nonsensical content, which is crucial for building trust and ensuring the reliability of these powerful AI systems.
While the framework has some limitations and areas for further research, the authors have demonstrated its effectiveness in hallucination detection tasks and its potential to become a key tool in the ongoing efforts to develop trustworthy and reliable large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
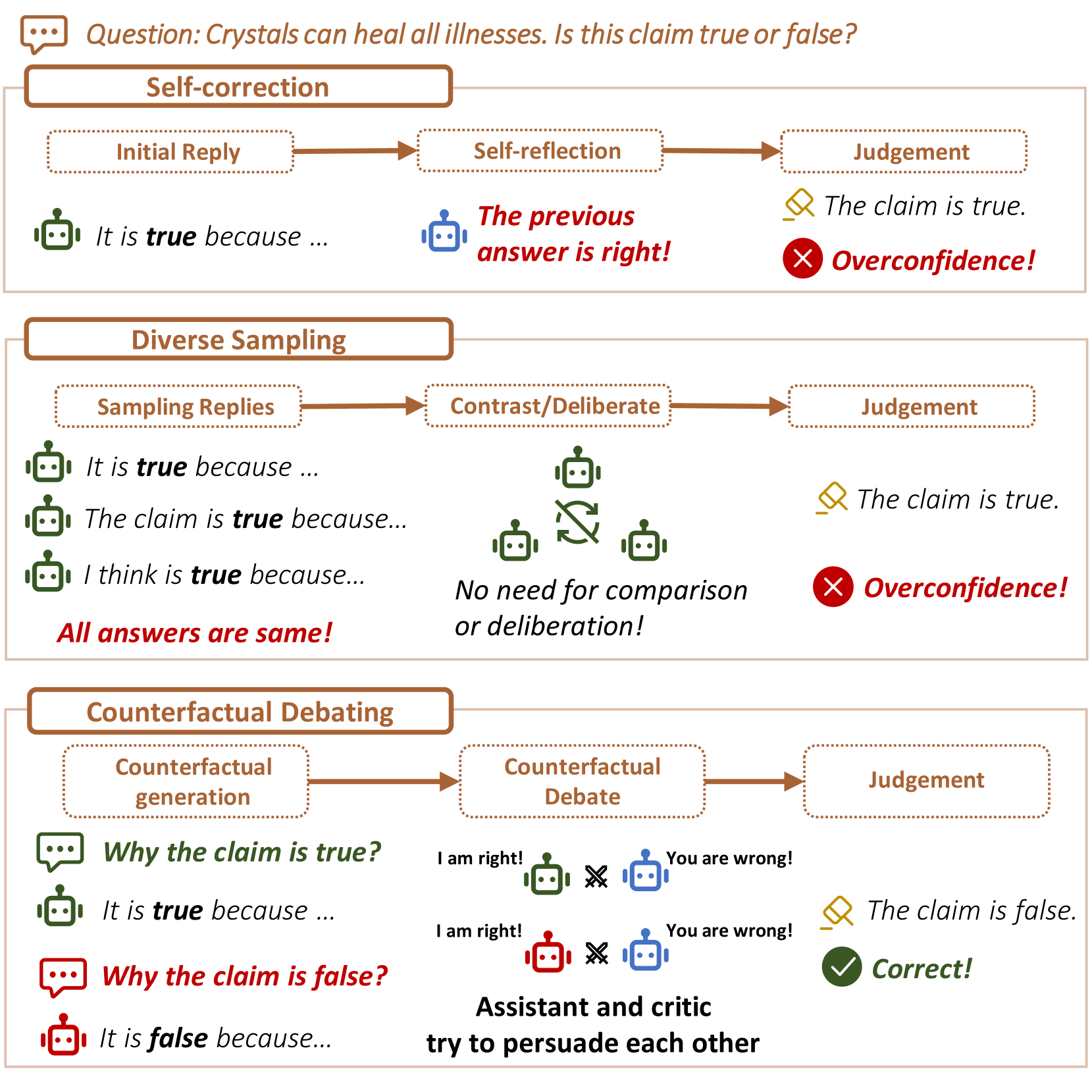
Counterfactual Debating with Preset Stances for Hallucination Elimination of LLMs
Yi Fang, Moxin Li, Wenjie Wang, Hui Lin, Fuli Feng
0
0
Large Language Models (LLMs) excel in various natural language processing tasks but struggle with hallucination issues. Existing solutions have considered utilizing LLMs' inherent reasoning abilities to alleviate hallucination, such as self-correction and diverse sampling methods. However, these methods often overtrust LLMs' initial answers due to inherent biases. The key to alleviating this issue lies in overriding LLMs' inherent biases for answer inspection. To this end, we propose a CounterFactual Multi-Agent Debate (CFMAD) framework. CFMAD presets the stances of LLMs to override their inherent biases by compelling LLMs to generate justifications for a predetermined answer's correctness. The LLMs with different predetermined stances are engaged with a skeptical critic for counterfactual debate on the rationality of generated justifications. Finally, the debate process is evaluated by a third-party judge to determine the final answer. Extensive experiments on four datasets of three tasks demonstrate the superiority of CFMAD over existing methods.
6/18/2024

Small Agent Can Also Rock! Empowering Small Language Models as Hallucination Detector
Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen
0
0
Hallucination detection is a challenging task for large language models (LLMs), and existing studies heavily rely on powerful closed-source LLMs such as GPT-4. In this paper, we propose an autonomous LLM-based agent framework, called HaluAgent, which enables relatively smaller LLMs (e.g. Baichuan2-Chat 7B) to actively select suitable tools for detecting multiple hallucination types such as text, code, and mathematical expression. In HaluAgent, we integrate the LLM, multi-functional toolbox, and design a fine-grained three-stage detection framework along with memory mechanism. To facilitate the effectiveness of HaluAgent, we leverage existing Chinese and English datasets to synthesize detection trajectories for fine-tuning, which endows HaluAgent with the capability for bilingual hallucination detection. Extensive experiments demonstrate that only using 2K samples for tuning LLMs, HaluAgent can perform hallucination detection on various types of tasks and datasets, achieving performance comparable to or even higher than GPT-4 without tool enhancements on both in-domain and out-of-domain datasets. We release our dataset and code at https://github.com/RUCAIBox/HaluAgent.
6/18/2024
🔎
Unified Hallucination Detection for Multimodal Large Language Models
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
0
0
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
5/28/2024

Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran HU, Zhijing Wu, Yujia Zhou, Yiqun Liu
0
0
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
6/11/2024