Pose-Guided Fine-Grained Sign Language Video Generation

0

Sign in to get full access
Overview
- The paper proposes a method for generating fine-grained sign language videos guided by pose information.
- The approach uses a modal fusion model to incorporate both visual and motion cues for generating realistic and temporally consistent sign language videos.
- Experiments demonstrate the model's ability to generate high-quality sign language videos that preserve the fine-grained details of sign language motion.
Plain English Explanation
The research paper discusses a new technique for generating sign language videos that closely match the real-life movements and expressions of sign language signers. This is known as ,[object Object],.
The key idea is to use information about the signer's body pose (the positioning of their hands, arms, and torso) to guide the video generation process. This pose-guided approach helps ensure that the generated videos accurately reflect the intricate details of sign language motion.
To achieve this, the researchers develop a modal fusion model that combines visual and motion cues from the input data. This allows the model to generate sign language videos that not only look realistic, but also maintain a consistent flow of movement over time (temporal consistency).
Through experiments, the paper demonstrates the model's ability to create high-quality sign language videos that capture the nuanced details of sign language performance. This is an important advancement, as realistic sign language videos can aid in accessibility and education for the deaf and hard-of-hearing community.
Technical Explanation
The paper introduces a novel approach for pose-guided fine-grained sign language video generation. The key components of the proposed method are:
-
Pose Estimation: The model first extracts pose information from the input data, representing the signer's body positioning and motion.
-
Modal Fusion: A fusion module is used to combine the visual and motion cues from the input, enabling the model to generate videos that are both realistic and temporally consistent.
-
Video Generation: The fused visual and motion representations are then used to generate the final sign language video, which preserves the fine-grained details of the original sign language performance.
The authors evaluate their approach on several sign language datasets, demonstrating its ability to generate high-quality sign language videos that closely match the original motion and appearance of the signer. [This work builds on previous research in areas like co-speech gesture video generation and one-shot learning for pose-guided person image generation.
Critical Analysis
The paper presents a compelling approach to sign language video generation, with a strong focus on preserving the fine-grained details of sign language motion. The use of pose information to guide the video generation process is a notable innovation that helps ensure the realism and temporal consistency of the output.
However, the paper does not extensively discuss the potential limitations or challenges of this approach. For example, it would be valuable to understand how the model performs on more diverse or complex sign language data, or how it might handle variations in signing style or environmental conditions.
Additionally, while the authors demonstrate the model's ability to generate high-quality videos, they do not provide a thorough discussion of the potential real-world applications and implications of this technology, such as its use in accessibility tools or educational resources for the deaf and hard-of-hearing community.
[Further research could also explore the model's generalizability to other domains, such as language-guided face animation or other forms of expressive human motion.](https://aimodels.fyi/papers/arxiv/pose-guided-fine-grained-sign-language-video)
Conclusion
The paper presents a novel approach to fine-grained sign language video generation that leverages pose information to create realistic and temporally consistent sign language videos. The proposed modal fusion model effectively combines visual and motion cues, enabling the generation of high-quality sign language videos that preserve the intricate details of sign language performance.
This research represents an important step forward in the field of sign language technology, with potential applications in accessibility, education, and beyond. By improving the realism and fidelity of generated sign language videos, this work could contribute to more immersive and inclusive experiences for the deaf and hard-of-hearing community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pose-Guided Fine-Grained Sign Language Video Generation
Tongkai Shi, Lianyu Hu, Fanhua Shang, Jichao Feng, Peidong Liu, Wei Feng
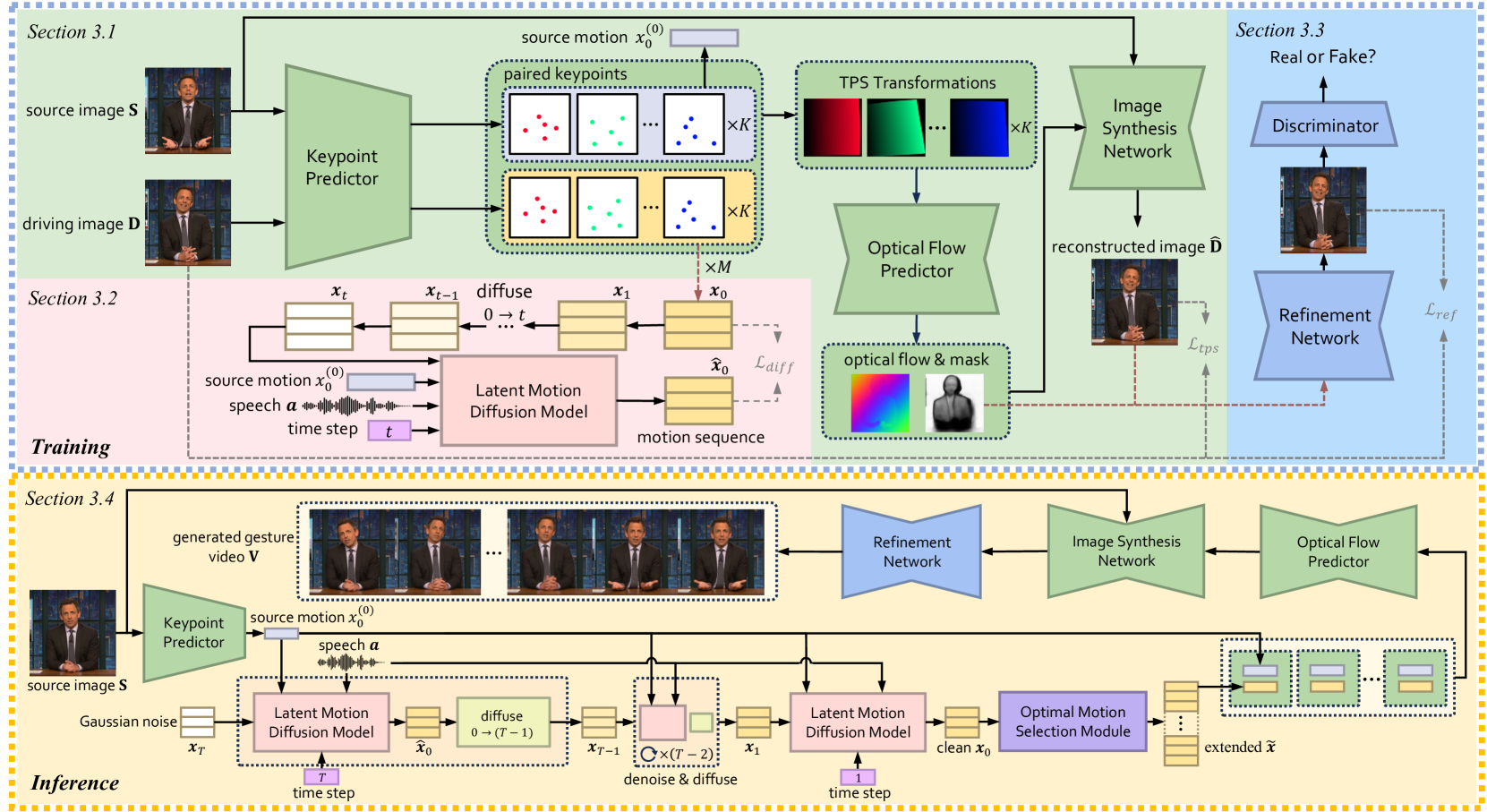
Sign language videos are an important medium for spreading and learning sign language. However, most existing human image synthesis methods produce sign language images with details that are distorted, blurred, or structurally incorrect. They also produce sign language video frames with poor temporal consistency, with anomalies such as flickering and abrupt detail changes between the previous and next frames. To address these limitations, we propose a novel Pose-Guided Motion Model (PGMM) for generating fine-grained and motion-consistent sign language videos. Firstly, we propose a new Coarse Motion Module (CMM), which completes the deformation of features by optical flow warping, thus transfering the motion of coarse-grained structures without changing the appearance; Secondly, we propose a new Pose Fusion Module (PFM), which guides the modal fusion of RGB and pose features, thus completing the fine-grained generation. Finally, we design a new metric, Temporal Consistency Difference (TCD) to quantitatively assess the degree of temporal consistency of a video by comparing the difference between the frames of the reconstructed video and the previous and next frames of the target video. Extensive qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in most benchmark tests, with visible improvements in details and temporal consistency.
Read more9/26/2024
0
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Read more4/3/2024

0
An Efficient Sign Language Translation Using Spatial Configuration and Motion Dynamics with LLMs
Eui Jun Hwang, Sukmin Cho, Junmyeong Lee, Jong C. Park
Gloss-free Sign Language Translation (SLT) converts sign videos directly into spoken language sentences without relying on glosses. Recently, Large Language Models (LLMs) have shown remarkable translation performance in gloss-free methods by harnessing their powerful natural language generation capabilities. However, these methods often rely on domain-specific fine-tuning of visual encoders to achieve optimal results. By contrast, this paper emphasizes the importance of capturing the spatial configurations and motion dynamics inherent in sign language. With this in mind, we introduce Spatial and Motion-based Sign Language Translation (SpaMo), a novel LLM-based SLT framework. The core idea of SpaMo is simple yet effective. We first extract spatial and motion features using off-the-shelf visual encoders and then input these features into an LLM with a language prompt. Additionally, we employ a visual-text alignment process as a warm-up before the SLT supervision. Our experiments demonstrate that SpaMo achieves state-of-the-art performance on two popular datasets, PHOENIX14T and How2Sign.
Read more8/21/2024

0
One-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Dongqi Fan, Tao Chen, Mingjie Wang, Rui Ma, Qiang Tang, Zili Yi, Qian Wang, Liang Chang
Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
Read more9/17/2024