PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation

0
Sign in to get full access
Overview
- PoseEmbroider proposes a new 3D, visual, semantic-aware human pose representation.
- It aims to enable tasks like 3D human pose retrieval and text generation from 3D poses.
- The approach involves learning a joint embedding space for 3D poses, images, and text descriptions.
Plain English Explanation
PoseEmbroider is a new way to represent 3D human poses that incorporates visual and semantic information. The key idea is to create a unified embedding space where 3D poses, images, and text descriptions of those poses are all mapped to the same space.
This allows for some interesting capabilities, like being able to retrieve 3D poses based on text descriptions or generate text descriptions from 3D poses. It also enables tasks like identifying visually similar 3D poses even if they have different underlying joint configurations.
The researchers achieve this by training a neural network model to learn the relationships between the 3D pose data, the visual appearance of the poses, and the natural language descriptions. The model is trained on a large dataset of 3D human poses, images, and text captions.
By embedding all this information into a shared space, the model can leverage the connections between the different modalities to improve performance on various 3D human pose understanding tasks.
Technical Explanation
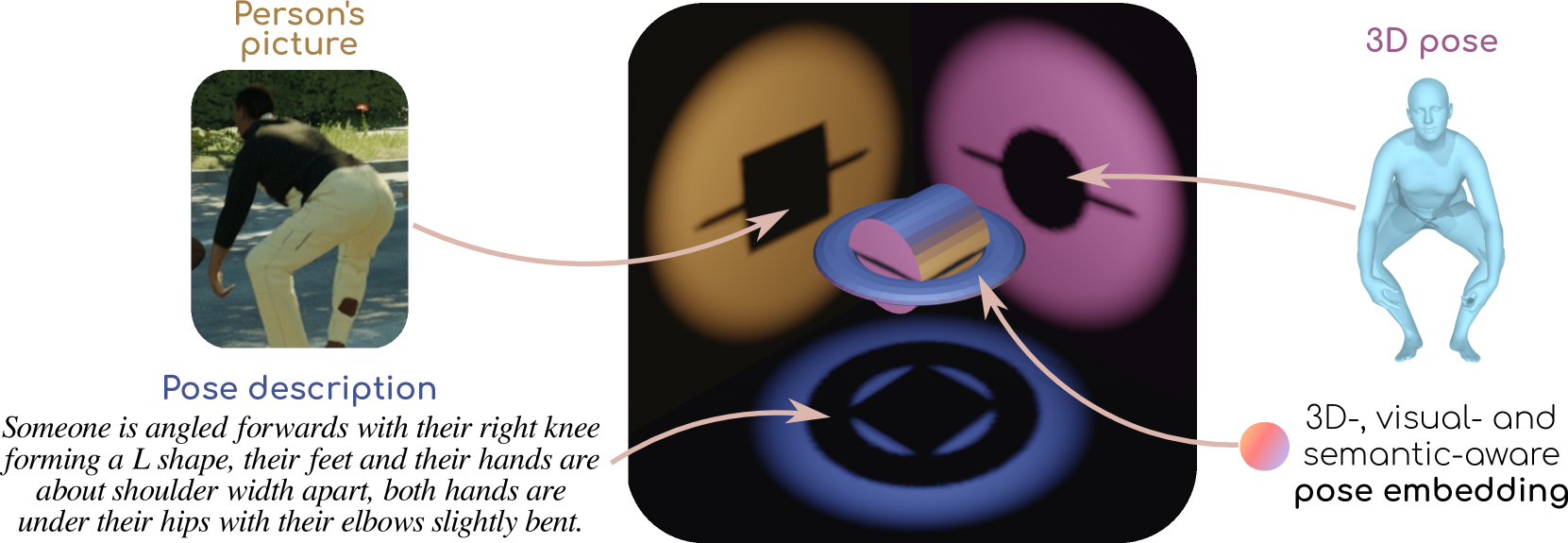
PoseEmbroider introduces a novel 3D human pose representation that captures both visual and semantic information. The key technical contribution is a joint embedding model that maps 3D poses, images, and text descriptions into a shared low-dimensional vector space.
The model consists of three main components:
- 3D Pose Encoder: This encodes the 3D joint positions of a human pose into a compact vector representation.
- Image Encoder: This encodes images of the human pose into a vector.
- Text Encoder: This encodes text descriptions of the human pose into a vector.
These three encoders are trained together to map their respective inputs into a common embedding space, where poses, images, and text that describe the same underlying human action are located close to each other.
The researchers leverage large datasets of 3D human poses, images, and text captions to train this joint embedding model end-to-end. They demonstrate the effectiveness of the learned representations on tasks like 3D pose retrieval from text queries and text generation from 3D poses.
Critical Analysis
The key strength of PoseEmbroider is its ability to jointly represent 3D human poses, visual appearances, and semantic descriptions in a shared embedding space. This unified representation enables powerful cross-modal capabilities, like retrieving 3D poses from text or generating text from 3D poses.
However, the paper does not address some important limitations and caveats:
- The model is trained and evaluated on a limited set of human pose datasets, so its performance on more diverse or challenging poses is unclear.
- The text generation component is relatively simple, only producing short captions. Generating more expressive, natural language descriptions remains an open challenge.
- The paper does not discuss the computational complexity or inference speed of the model, which are important practical considerations for real-world applications.
Additionally, while the authors claim the model can learn semantically meaningful representations, they do not provide a thorough qualitative analysis or visualization of the learned embedding space. Further investigation into the semantic properties of the representations would strengthen the claims.
Overall, PoseEmbroider presents a promising approach to 3D human pose understanding, but additional research is needed to fully validate its capabilities and limitations.
Conclusion
PoseEmbroider introduces a novel 3D human pose representation that jointly encodes visual, semantic, and 3D geometric information. By learning a shared embedding space for poses, images, and text, the model enables cross-modal capabilities like 3D pose retrieval from text and text generation from 3D poses.
This work represents an important step towards more holistic and interpretable 3D human pose understanding, with potential applications in areas like human-robot interaction, virtual reality, and video analysis. Further research is needed to fully explore the model's limitations and expand its capabilities, but the core idea of integrating multiple modalities into a unified representation is a promising direction for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, Gr'egory Rogez
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
Read more9/11/2024
🌿
0
PoseScript: Linking 3D Human Poses and Natural Language
Ginger Delmas, Philippe Weinzaepfel, Thomas Lucas, Francesc Moreno-Noguer, Gr'egory Rogez
Natural language plays a critical role in many computer vision applications, such as image captioning, visual question answering, and cross-modal retrieval, to provide fine-grained semantic information. Unfortunately, while human pose is key to human understanding, current 3D human pose datasets lack detailed language descriptions. To address this issue, we have introduced the PoseScript dataset. This dataset pairs more than six thousand 3D human poses from AMASS with rich human-annotated descriptions of the body parts and their spatial relationships. Additionally, to increase the size of the dataset to a scale that is compatible with data-hungry learning algorithms, we have proposed an elaborate captioning process that generates automatic synthetic descriptions in natural language from given 3D keypoints. This process extracts low-level pose information, known as posecodes, using a set of simple but generic rules on the 3D keypoints. These posecodes are then combined into higher level textual descriptions using syntactic rules. With automatic annotations, the amount of available data significantly scales up (100k), making it possible to effectively pretrain deep models for finetuning on human captions. To showcase the potential of annotated poses, we present three multi-modal learning tasks that utilize the PoseScript dataset. Firstly, we develop a pipeline that maps 3D poses and textual descriptions into a joint embedding space, allowing for cross-modal retrieval of relevant poses from large-scale datasets. Secondly, we establish a baseline for a text-conditioned model generating 3D poses. Thirdly, we present a learned process for generating pose descriptions. These applications demonstrate the versatility and usefulness of annotated poses in various tasks and pave the way for future research in the field.
Read more9/11/2024
🔮
0
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
Read more5/7/2024

0
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges
Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
Read more8/21/2024