PoseScript: Linking 3D Human Poses and Natural Language

0
🌿
Sign in to get full access
Overview
- This paper introduces the PoseScript dataset, which pairs 3D human poses with rich natural language descriptions.
- The dataset aims to provide detailed semantic information about human poses, which is crucial for various computer vision applications.
- To scale up the dataset, the authors propose an automatic captioning process that generates synthetic descriptions from 3D keypoints.
- The paper showcases three multi-modal learning tasks that utilize the PoseScript dataset, demonstrating its versatility and usefulness.
Plain English Explanation
Human poses can provide valuable information for computer vision tasks like image captioning, visual question answering, and cross-modal retrieval. However, existing 3D human pose datasets lack detailed language descriptions of the body parts and their spatial relationships.
To address this issue, the researchers created the PoseScript dataset, which links more than six thousand 3D human poses from the AMASS dataset with rich human-annotated descriptions. This allows for fine-grained semantic understanding of the poses.
To further expand the dataset, the researchers developed an automated captioning process. This process extracts low-level "posecodes" from the 3D keypoints using simple rules, and then combines these posecodes into more detailed natural language descriptions using syntactic rules. This increases the dataset size to over 100,000 samples, making it more suitable for training data-hungry deep learning models.
The paper then showcases three ways the PoseScript dataset can be used:
-
Cross-modal Retrieval: Mapping 3D poses and text descriptions into a joint embedding space to allow retrieving relevant poses from large datasets based on text queries.
-
Text-Conditioned Pose Generation: Establishing a baseline for generating 3D poses from textual descriptions.
-
Pose Description Generation: Learning a model to automatically generate natural language descriptions from 3D poses.
These applications demonstrate the value of annotated 3D human poses and pave the way for future research in this area.
Technical Explanation
The paper introduces the PoseScript dataset, which pairs 3D human poses from the AMASS dataset with rich natural language descriptions. The researchers collected over six thousand human-annotated descriptions to provide fine-grained semantic information about the body parts and their spatial relationships.
To scale up the dataset, the authors proposed an automatic captioning process. This process first extracts low-level "posecodes" from the 3D keypoints using a set of simple but generic rules. These posecodes capture information about the body parts and their spatial relationships. The posecodes are then combined into higher-level textual descriptions using syntactic rules. This increases the dataset size to over 100,000 samples, making it more suitable for training data-hungry deep learning models.
The paper presents three multi-modal learning tasks that showcase the potential of the PoseScript dataset:
-
Cross-modal Retrieval: The authors develop a pipeline that maps 3D poses and textual descriptions into a joint embedding space, allowing for cross-modal retrieval of relevant poses from large-scale datasets.
-
Text-Conditioned Pose Generation: The paper establishes a baseline for a text-conditioned model that generates 3D poses from textual descriptions.
-
Pose Description Generation: The researchers present a learned process for generating natural language descriptions from 3D poses.
These applications demonstrate the versatility and usefulness of the PoseScript dataset in various multi-modal learning tasks.
Critical Analysis
The paper presents a novel approach to annotating 3D human poses with rich natural language descriptions, which is a valuable contribution to the field of computer vision. The automatic captioning process is a clever way to scale up the dataset, though the quality and accuracy of the synthetic descriptions may be a concern.
The paper also acknowledges the limitations of the current work, such as the potential biases in the human-annotated descriptions and the need for further research on more advanced pose description generation models.
Additionally, the paper does not address potential privacy or ethical concerns around the use of 3D human pose data, which may be an important consideration for real-world applications. Exploring ways to ensure the responsible use of such datasets would be a valuable direction for future research.
Overall, the PoseScript dataset and the presented applications demonstrate the potential of annotated 3D human poses for advancing computer vision and multi-modal research. Further development and careful consideration of the dataset's limitations and ethical implications could lead to even more impactful contributions in this field.
Conclusion
This paper introduces the PoseScript dataset, which pairs 3D human poses with rich natural language descriptions. The dataset aims to provide detailed semantic information about human poses, which is crucial for various computer vision applications.
To scale up the dataset, the researchers developed an automatic captioning process that generates synthetic descriptions from 3D keypoints. This significantly increases the amount of available data, making it more suitable for training data-hungry deep learning models.
The paper showcases three multi-modal learning tasks that utilize the PoseScript dataset, demonstrating its versatility and usefulness. These applications include cross-modal retrieval, text-conditioned pose generation, and pose description generation.
Overall, the PoseScript dataset and the presented research pave the way for future work in leveraging annotated 3D human poses for advancing computer vision and multi-modal learning. Further exploration of the dataset's limitations and ethical considerations could lead to even more impactful contributions in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
PoseScript: Linking 3D Human Poses and Natural Language
Ginger Delmas, Philippe Weinzaepfel, Thomas Lucas, Francesc Moreno-Noguer, Gr'egory Rogez
Natural language plays a critical role in many computer vision applications, such as image captioning, visual question answering, and cross-modal retrieval, to provide fine-grained semantic information. Unfortunately, while human pose is key to human understanding, current 3D human pose datasets lack detailed language descriptions. To address this issue, we have introduced the PoseScript dataset. This dataset pairs more than six thousand 3D human poses from AMASS with rich human-annotated descriptions of the body parts and their spatial relationships. Additionally, to increase the size of the dataset to a scale that is compatible with data-hungry learning algorithms, we have proposed an elaborate captioning process that generates automatic synthetic descriptions in natural language from given 3D keypoints. This process extracts low-level pose information, known as posecodes, using a set of simple but generic rules on the 3D keypoints. These posecodes are then combined into higher level textual descriptions using syntactic rules. With automatic annotations, the amount of available data significantly scales up (100k), making it possible to effectively pretrain deep models for finetuning on human captions. To showcase the potential of annotated poses, we present three multi-modal learning tasks that utilize the PoseScript dataset. Firstly, we develop a pipeline that maps 3D poses and textual descriptions into a joint embedding space, allowing for cross-modal retrieval of relevant poses from large-scale datasets. Secondly, we establish a baseline for a text-conditioned model generating 3D poses. Thirdly, we present a learned process for generating pose descriptions. These applications demonstrate the versatility and usefulness of annotated poses in various tasks and pave the way for future research in the field.
Read more9/11/2024
0
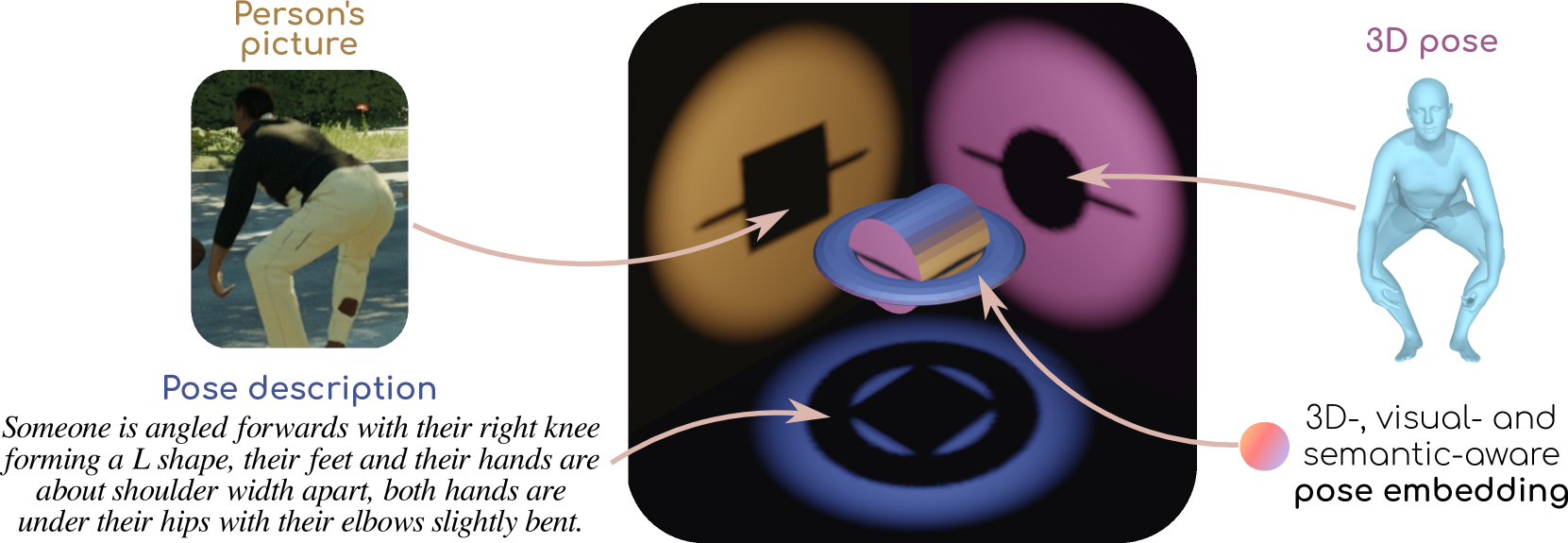
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, Gr'egory Rogez
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
Read more9/11/2024
0
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
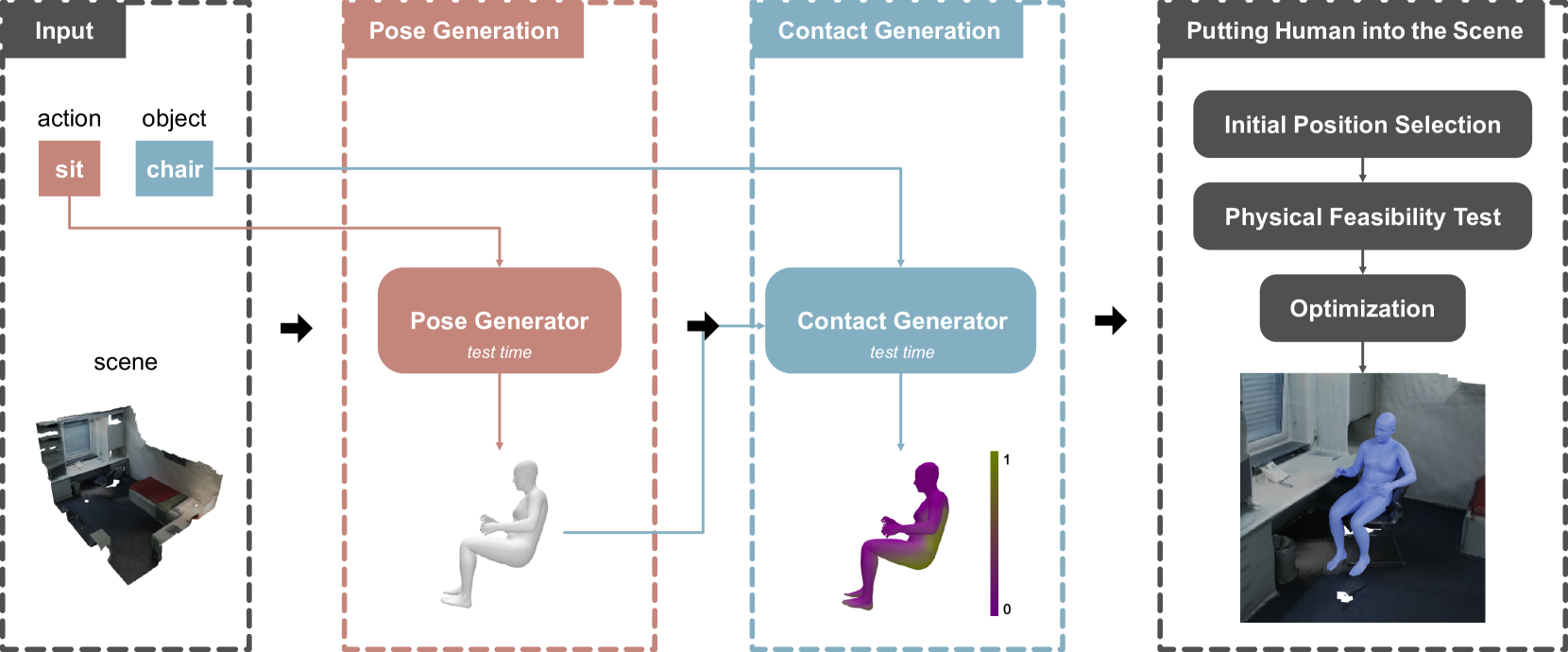
Bowen Dang, Xi Zhao
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
Read more6/11/2024
💬
0
Pose Priors from Language Models
Sanjay Subramanian, Evonne Ng, Lea Muller, Dan Klein, Shiry Ginosar, Trevor Darrell
We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
Read more5/7/2024