Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges

0

Sign in to get full access
Overview
- This paper introduces the task of post-hoc answer attribution for long document comprehension, which aims to identify the most relevant parts of a document that support a given answer to a question.
- The authors discuss the challenges and insights gained from adapting existing datasets for this task, including issues around data quality, annotation, and evaluation.
- They propose several promising research directions for addressing the challenges and advancing the state of the art in this important area.
Plain English Explanation
When we read a long document and answer a question about its contents, it's often helpful to be able to point to the specific parts of the document that support our answer. This can make the reasoning behind our answer more transparent and trustworthy. The authors of this paper explore the task of post-hoc answer attribution, which involves identifying the most relevant sections of a document that justify a given answer.
The paper discusses the challenges the authors encountered when trying to adapt existing datasets, like SQuAD and HotpotQA, for this new task. Some of the key issues included poor data quality, lack of suitable annotations, and difficulties in properly evaluating system performance.
Despite these challenges, the authors provide several promising research directions, such as developing new datasets and models that can better ground answers in the source text. By addressing these challenges, the field can make progress towards building more transparent and trustworthy language understanding systems.
Technical Explanation
The paper introduces the task of post-hoc answer attribution, which aims to identify the specific parts of a long document that support a given answer to a question about the document's contents. The authors discuss their efforts to adapt existing datasets, such as SQuAD and HotpotQA, to this new task.
One of the key challenges the authors faced was the poor quality of the data in these datasets, with many answers not being well-grounded in the source text. Additionally, the datasets lacked suitable annotations to support the post-hoc attribution task, as they were primarily designed for answer extraction rather than answer justification.
To address these issues, the authors explored several potential solutions, including developing new datasets and models that can better ground answers in the source text. They also investigated techniques for chain-of-thought attribution and factuality scoring to better understand and evaluate the reasoning behind system outputs.
The insights and challenges discussed in this paper provide a valuable roadmap for future research in the area of long document comprehension and trustworthy AI systems.
Critical Analysis
The authors of this paper provide a thoughtful analysis of the challenges they encountered when adapting existing datasets for the task of post-hoc answer attribution. They rightly identify the lack of suitable annotations and the poor quality of the data as significant hurdles that need to be addressed.
One potential limitation of the paper is that it does not delve deeply into the specific shortcomings of the existing datasets or provide a detailed critique of their suitability for the task at hand. A more comprehensive analysis of the dataset issues could have strengthened the paper's contribution.
Additionally, while the authors propose several promising research directions, such as developing new datasets and models for grounding answers in the source text, they do not provide a clear roadmap or concrete steps for how to address these challenges. More specific recommendations or a discussion of potential pitfalls in these research directions could have made the paper more actionable for the research community.
Overall, this paper raises important issues and provides a valuable starting point for further research in the area of post-hoc answer attribution and trustworthy long document comprehension. By encouraging the community to think critically about the limitations of current approaches and explore new avenues for progress, the authors have laid the groundwork for future advancements in this important field.
Conclusion
This paper introduces the task of post-hoc answer attribution for long document comprehension, which aims to identify the specific parts of a document that support a given answer to a question. The authors discuss the challenges they faced when adapting existing datasets for this task, including issues with data quality, annotation, and evaluation.
Despite these challenges, the paper proposes several promising research directions, such as developing new datasets and models that can better ground answers in the source text. By addressing these challenges, the field can make progress towards building more transparent and trustworthy language understanding systems, which is crucial for applications ranging from academic research to real-world decision-making.
The insights and discussions presented in this paper provide a valuable foundation for future work in the area of long document comprehension and trustworthy AI, offering researchers a roadmap for tackling these important and complex problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges
Abhilasha Sancheti, Koustava Goswami, Balaji Vasan Srinivasan
Attributing answer text to its source document for information-seeking questions is crucial for building trustworthy, reliable, and accountable systems. We formulate a new task of post-hoc answer attribution for long document comprehension (LDC). Owing to the lack of long-form abstractive and information-seeking LDC datasets, we refactor existing datasets to assess the strengths and weaknesses of existing retrieval-based and proposed answer decomposition and textual entailment-based optimal selection attribution systems for this task. We throw light on the limitations of existing datasets and the need for datasets to assess the actual performance of systems on this task.
Read more6/12/2024

0
Attribute or Abstain: Large Language Models as Long Document Assistants
Jan Buchmann, Xiao Liu, Iryna Gurevych
LLMs can help humans working with long documents, but are known to hallucinate. Attribution can increase trust in LLM responses: The LLM provides evidence that supports its response, which enhances verifiability. Existing approaches to attribution have only been evaluated in RAG settings, where the initial retrieval confounds LLM performance. This is crucially different from the long document setting, where retrieval is not needed, but could help. Thus, a long document specific evaluation of attribution is missing. To fill this gap, we present LAB, a benchmark of 6 diverse long document tasks with attribution, and experiment with different approaches to attribution on 4 LLMs of different sizes, both prompted and fine-tuned. We find that citation, i.e. response generation and evidence extraction in one step, mostly performs best. We investigate whether the ``Lost in the Middle'' phenomenon exists for attribution, but do not find this. We also find that evidence quality can predict response quality on datasets with simple responses, but not so for complex responses, as models struggle with providing evidence for complex claims. We release code and data for further investigation.
Read more7/11/2024
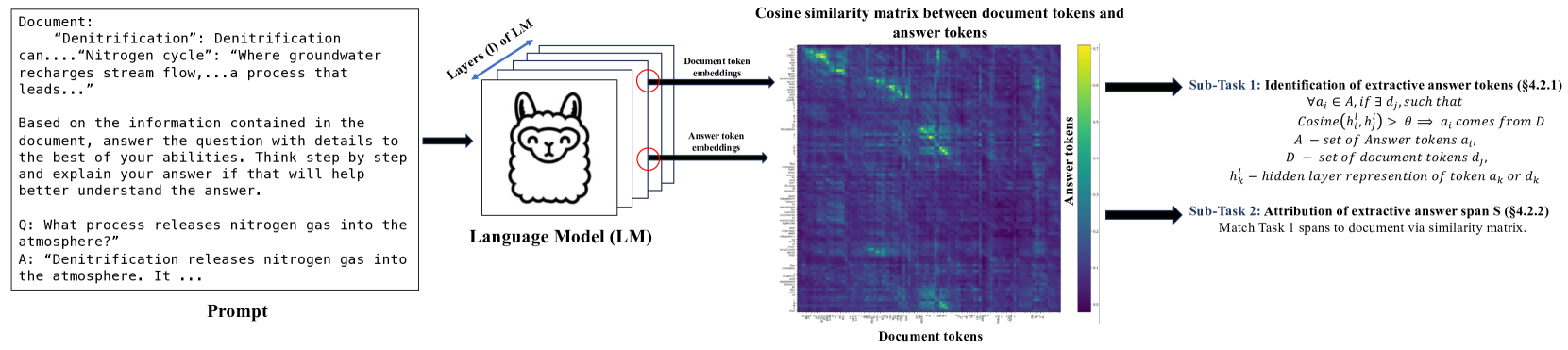
0
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024

0
Learning to Plan and Generate Text with Citations
Constanza Fierro, Reinald Kim Amplayo, Fantine Huot, Nicola De Cao, Joshua Maynez, Shashi Narayan, Mirella Lapata
The increasing demand for the deployment of LLMs in information-seeking scenarios has spurred efforts in creating verifiable systems, which generate responses to queries along with supporting evidence. In this paper, we explore the attribution capabilities of plan-based models which have been recently shown to improve the faithfulness, grounding, and controllability of generated text. We conceptualize plans as a sequence of questions which serve as blueprints of the generated content and its organization. We propose two attribution models that utilize different variants of blueprints, an abstractive model where questions are generated from scratch, and an extractive model where questions are copied from the input. Experiments on long-form question-answering show that planning consistently improves attribution quality. Moreover, the citations generated by blueprint models are more accurate compared to those obtained from LLM-based pipelines lacking a planning component.
Read more7/24/2024