Attribute or Abstain: Large Language Models as Long Document Assistants

0

Sign in to get full access
Overview
- This paper explores how large language models (LLMs) can be used as assistants for working with long documents, such as research papers or reports.
- The key focus is on the "attribute or abstain" approach, where the LLM can either attribute a given output to a specific section of the input document or abstain from providing an answer if it is not confident.
- The authors investigate this approach across various tasks, including question answering, summarization, and section retrieval, to understand the capabilities and limitations of LLMs for long-form document processing.
Plain English Explanation
The researchers in this paper looked at how powerful AI language models, known as large language models (LLMs), can be used to help people work with long and complex documents, like research papers or reports.
The main idea they focused on is called "attribute or abstain." This means the language model can either attribute or abstain - it can either try to give an answer to a question about the document, or it can say it's not confident enough to provide an answer. This is an important ability, because we want to make sure the language model is being honest about what it knows and doesn't know, rather than guessing.
The researchers tested this "attribute or abstain" approach across different tasks, like answering questions about the document, summarizing key points, and retrieving relevant sections. This helped them understand the strengths and limitations of using LLMs to assist people with working through long, complex documents, which is an important problem to tackle as these models become more widely used.
Technical Explanation
The paper investigates the use of large language models (LLMs) as assistants for working with long documents, such as research papers or reports. The key focus is on the "attribute or abstain" approach, where the LLM can either attribute a given output to a specific section of the input document or abstain from providing an answer if it is not confident.
The authors evaluate this approach across a variety of tasks, including question answering, summarization, and section retrieval. For question answering, the LLM must determine which part of the document the answer is grounded in or abstain if it is not confident. For summarization, the LLM must attribute generated summary sentences to their corresponding document sections or abstain. And for section retrieval, the LLM must identify the most relevant document sections for a given query or abstain.
The experiments show that the "attribute or abstain" approach can help improve the reliability and transparency of LLM-based assistants for long document processing. By allowing the model to abstain, it can avoid making guesses that may be incorrect, which is important for applications where trustworthiness is critical. The results also reveal insights into the strengths and limitations of current LLMs for handling long-form content and suggest directions for further research and development.
Critical Analysis
The paper provides a thoughtful exploration of the "attribute or abstain" approach for using large language models (LLMs) as long document assistants. The experimental design and evaluation across multiple tasks are well-executed and yield valuable insights.
One potential limitation highlighted in the paper is the reliance on human-annotated ground truth for evaluating the LLM's performance. While necessary for this type of study, this approach may not fully capture the nuances of how real users would interact with and rely on the system. Further research into more naturalistic evaluation setups could provide additional insights.
Additionally, the paper does not delve deeply into the specific architectural choices or training regimes that may impact the LLM's performance on these tasks. Exploring the model's inner workings and their connection to the observed behaviors could lead to further advancements in the field.
Overall, this paper makes a valuable contribution to the understanding of how LLMs can be leveraged as assistants for long-form document processing. The "attribute or abstain" approach seems promising, and the insights generated by this work can inform the development of more reliable and trustworthy LLM-based tools for a variety of applications.
Conclusion
This paper explores the use of large language models (LLMs) as assistants for working with long documents, such as research papers or reports. The key focus is on the "attribute or abstain" approach, where the LLM can either attribute a given output to a specific section of the input document or abstain from providing an answer if it is not confident.
The experiments across various tasks, including question answering, summarization, and section retrieval, demonstrate the potential of this approach to improve the reliability and transparency of LLM-based assistants for long document processing. By allowing the model to abstain when it is uncertain, the system can avoid making potentially incorrect guesses, which is crucial for applications where trustworthiness is critical.
The insights generated by this work can inform the development of more advanced LLM-based tools for handling long-form content and attribute-based generation, ultimately helping humans work more effectively with complex documents and information sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attribute or Abstain: Large Language Models as Long Document Assistants
Jan Buchmann, Xiao Liu, Iryna Gurevych
LLMs can help humans working with long documents, but are known to hallucinate. Attribution can increase trust in LLM responses: The LLM provides evidence that supports its response, which enhances verifiability. Existing approaches to attribution have only been evaluated in RAG settings, where the initial retrieval confounds LLM performance. This is crucially different from the long document setting, where retrieval is not needed, but could help. Thus, a long document specific evaluation of attribution is missing. To fill this gap, we present LAB, a benchmark of 6 diverse long document tasks with attribution, and experiment with different approaches to attribution on 4 LLMs of different sizes, both prompted and fine-tuned. We find that citation, i.e. response generation and evidence extraction in one step, mostly performs best. We investigate whether the ``Lost in the Middle'' phenomenon exists for attribution, but do not find this. We also find that evidence quality can predict response quality on datasets with simple responses, but not so for complex responses, as models struggle with providing evidence for complex claims. We release code and data for further investigation.
Read more7/11/2024

0
Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges
Abhilasha Sancheti, Koustava Goswami, Balaji Vasan Srinivasan
Attributing answer text to its source document for information-seeking questions is crucial for building trustworthy, reliable, and accountable systems. We formulate a new task of post-hoc answer attribution for long document comprehension (LDC). Owing to the lack of long-form abstractive and information-seeking LDC datasets, we refactor existing datasets to assess the strengths and weaknesses of existing retrieval-based and proposed answer decomposition and textual entailment-based optimal selection attribution systems for this task. We throw light on the limitations of existing datasets and the need for datasets to assess the actual performance of systems on this task.
Read more6/12/2024

0
An Evaluation Framework for Attributed Information Retrieval using Large Language Models
Hanane Djeddal, Pierre Erbacher, Raouf Toukal, Laure Soulier, Karen Pinel-Sauvagnat, Sophia Katrenko, Lynda Tamine
With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.
Read more9/14/2024
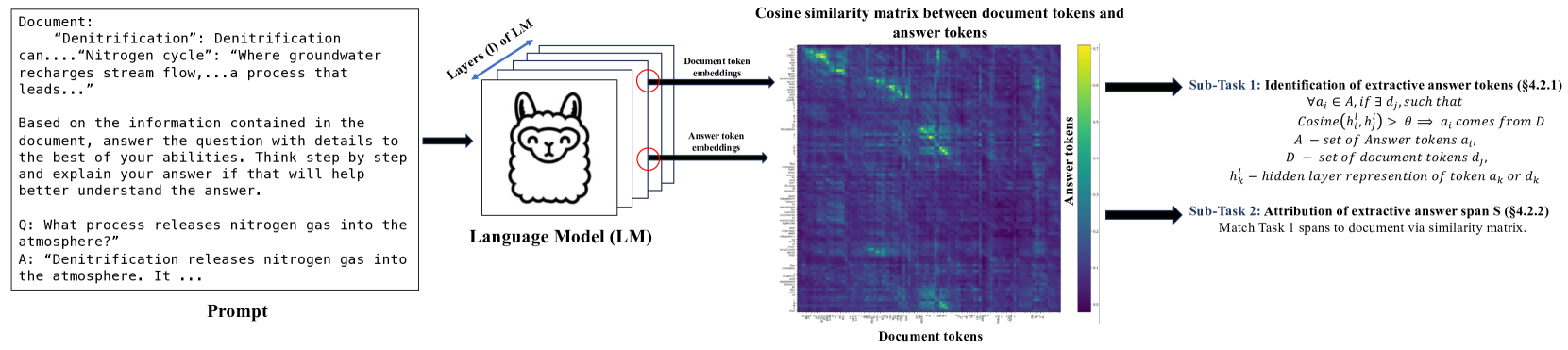
0
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024