Post-train Black-box Defense via Bayesian Boundary Correction

0
🔍
Sign in to get full access
Overview
- Deep neural network classifiers are susceptible to adversarial attacks, where malicious inputs can fool the model.
- Existing defense methods often require retraining the model, which may not be feasible for users.
- The paper proposes a new post-training, black-box defense framework called Bayesian Boundary Correction (BBC) that can enhance robustness without retraining.
Plain English Explanation
Deep learning models used for tasks like image classification or activity recognition can be easily fooled by small, carefully crafted changes to the input data. These "adversarial attacks" can cause the model to misclassify the input, even when it would normally get the right answer.
Existing methods to defend against these attacks often require retraining the model with special loss functions or training regimes. However, retraining the model may not be possible for many users, due to limited computational resources or lack of access to the model's training details.
To address this, the researchers propose a new defense framework called Bayesian Boundary Correction (BBC). BBC can take a pre-trained, vulnerable model and make it more robust to adversarial attacks, without needing to retrain the model. It does this by using a Bayesian approach to model the relationship between the clean data, the adversarial examples, and the classifier itself. This allows BBC to "correct" the model's decision boundaries in a way that enhances robustness.
The key advantage of BBC is that it can be applied as a post-processing step, without modifying the original model. This makes it a flexible, black-box defense that can work with any pre-trained classifier, regardless of the model architecture or training details.
Technical Explanation
The paper introduces the Bayesian Boundary Correction (BBC) framework, which aims to improve the adversarial robustness of pre-trained classifiers in a black-box setting.
The core idea is to model the joint probability distribution of the clean data, adversarial examples, and the classifier parameters. By maximizing this joint probability, BBC can learn a "corrected" decision boundary that is more robust to adversarial perturbations, while preserving the original model's performance on clean data.
Specifically, BBC consists of two key components:
-
A Bayesian treatment that models the joint distribution of clean data, adversarial examples, and classifier parameters. This allows BBC to capture the complex relationships between these elements.
-
A post-training strategy that updates the classifier's decision boundary without modifying the original model parameters. This avoids the need for costly retraining of the victim model.
The authors instantiate BBC for both image classification and skeleton-based human activity recognition tasks, demonstrating its flexibility across different data modalities (static and dynamic). Extensive experiments show that BBC can significantly improve model robustness against adversarial attacks, while maintaining high accuracy on clean data, outperforming various existing defense methods.
Critical Analysis
The BBC framework presents a promising approach to adversarial defense that addresses the limitations of existing white-box methods that require retraining the victim model. By taking a post-training, black-box approach, BBC overcomes the need for access to model internals or retraining capabilities, making it more practical for real-world deployment.
However, the paper does not explore the scalability of BBC to larger, more complex models or datasets. The experiments are relatively limited in scope, and it would be valuable to see how BBC performs on state-of-the-art computer vision or natural language processing models.
Additionally, the paper does not provide a thorough analysis of BBC's computational overhead or latency implications. Since BBC involves additional post-processing steps, it would be important to understand the trade-offs in terms of inference time and resource utilization.
Furthermore, the paper could benefit from a more in-depth discussion of the potential limitations or failure modes of the Bayesian modeling approach used in BBC. While the results are promising, there may be scenarios or edge cases where the joint probability modeling breaks down or becomes unstable.
Overall, the BBC framework represents an interesting and practical contribution to the field of adversarial defense. Further research exploring its scalability, efficiency, and robustness in a wider range of domains would help solidify its place as a viable solution for making deep learning models more secure.
Conclusion
The Bayesian Boundary Correction (BBC) framework proposed in this paper offers a novel approach to enhancing the adversarial robustness of pre-trained deep learning classifiers. By modeling the joint probability distribution of clean data, adversarial examples, and the classifier parameters, BBC can learn a more robust decision boundary without the need for retraining the victim model.
This black-box, post-training defense strategy makes BBC a practical and flexible solution, as it can be applied to any pre-trained classifier regardless of the model architecture or training details. The authors demonstrate the effectiveness of BBC on both image classification and skeleton-based activity recognition tasks, showcasing its versatility across different data modalities.
While the paper leaves room for further exploration of BBC's scalability and limitations, the proposed framework represents an important step forward in addressing the widespread vulnerability of deep neural networks to adversarial attacks. As deep learning continues to permeate critical applications, developing robust and deployable defense mechanisms like BBC will be crucial for ensuring the safety and reliability of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Post-train Black-box Defense via Bayesian Boundary Correction
He Wang, Yunfeng Diao
Classifiers based on deep neural networks are susceptible to adversarial attack, where the widely existing vulnerability has invoked the research in defending them from potential threats. Given a vulnerable classifier, existing defense methods are mostly white-box and often require re-training the victim under modified loss functions/training regimes. While the model/data/training specifics of the victim are usually unavailable to the user, re-training is unappealing, if not impossible for reasons such as limited computational resources. To this end, we propose a new post-train black-box defense framework. It can turn any pre-trained classifier into a resilient one with little knowledge of the model specifics. This is achieved by new joint Bayesian treatments on the clean data, the adversarial examples and the classifier, for maximizing their joint probability. It is further equipped with a new post-train strategy which keeps the victim intact, avoiding re-training. We name our framework Bayesian Boundary Correction (BBC). BBC is a general and flexible framework that can easily adapt to different data types. We instantiate BBC for image classification and skeleton-based human activity recognition, for both static and dynamic data. Exhaustive evaluation shows that BBC has superior robustness and can enhance robustness without severely hurting the clean accuracy, compared with existing defense methods.
Read more6/12/2024

0
Privacy-preserving Universal Adversarial Defense for Black-box Models
Qiao Li, Cong Wu, Jing Chen, Zijun Zhang, Kun He, Ruiying Du, Xinxin Wang, Qingchuang Zhao, Yang Liu
Deep neural networks (DNNs) are increasingly used in critical applications such as identity authentication and autonomous driving, where robustness against adversarial attacks is crucial. These attacks can exploit minor perturbations to cause significant prediction errors, making it essential to enhance the resilience of DNNs. Traditional defense methods often rely on access to detailed model information, which raises privacy concerns, as model owners may be reluctant to share such data. In contrast, existing black-box defense methods fail to offer a universal defense against various types of adversarial attacks. To address these challenges, we introduce DUCD, a universal black-box defense method that does not require access to the target model's parameters or architecture. Our approach involves distilling the target model by querying it with data, creating a white-box surrogate while preserving data privacy. We further enhance this surrogate model using a certified defense based on randomized smoothing and optimized noise selection, enabling robust defense against a broad range of adversarial attacks. Comparative evaluations between the certified defenses of the surrogate and target models demonstrate the effectiveness of our approach. Experiments on multiple image classification datasets show that DUCD not only outperforms existing black-box defenses but also matches the accuracy of white-box defenses, all while enhancing data privacy and reducing the success rate of membership inference attacks.
Read more8/21/2024
0
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
Firuz Juraev, Mohammed Abuhamad, Eric Chan-Tin, George K. Thiruvathukal, Tamer Abuhmed
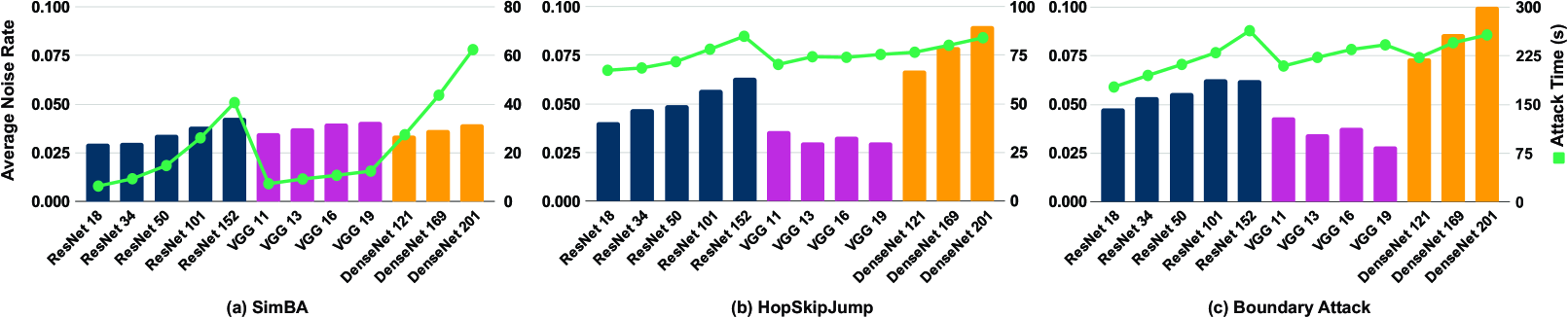
Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
Read more5/6/2024
0
Attacking Bayes: On the Adversarial Robustness of Bayesian Neural Networks
Yunzhen Feng, Tim G. J. Rudner, Nikolaos Tsilivis, Julia Kempe
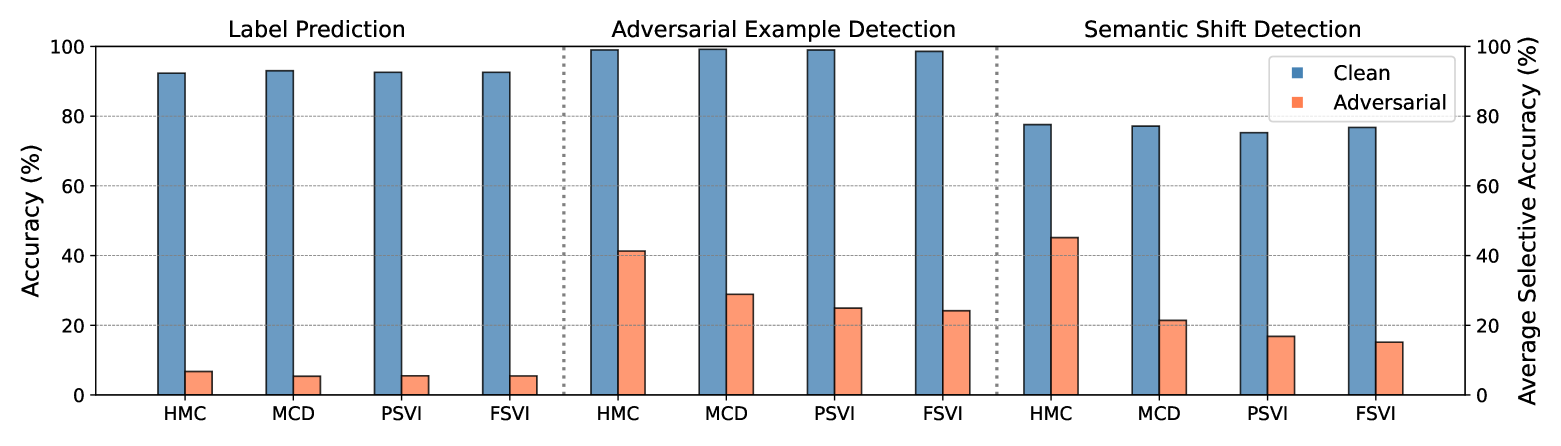
Adversarial examples have been shown to cause neural networks to fail on a wide range of vision and language tasks, but recent work has claimed that Bayesian neural networks (BNNs) are inherently robust to adversarial perturbations. In this work, we examine this claim. To study the adversarial robustness of BNNs, we investigate whether it is possible to successfully break state-of-the-art BNN inference methods and prediction pipelines using even relatively unsophisticated attacks for three tasks: (1) label prediction under the posterior predictive mean, (2) adversarial example detection with Bayesian predictive uncertainty, and (3) semantic shift detection. We find that BNNs trained with state-of-the-art approximate inference methods, and even BNNs trained with Hamiltonian Monte Carlo, are highly susceptible to adversarial attacks. We also identify various conceptual and experimental errors in previous works that claimed inherent adversarial robustness of BNNs and conclusively demonstrate that BNNs and uncertainty-aware Bayesian prediction pipelines are not inherently robust against adversarial attacks.
Read more5/1/2024